|
||||
|
|
Глава 12На твердой почве
Теперь, когда вы уже знакомы с основными причинами неточных результатов исторических тестов, давайте рассмотрим основные принципы правильного тестирования прошлого. В лучшем случае вы можете получить лишь примерное представление о том, как связано будущее с результатами исторического моделирования. Но к счастью, даже примерное представление может обеспечить хорошему трейдеру перевес, достаточный для того, чтобы заработать много денег. Чтобы при оценке ваших идей проанализировать важность факторов, влияющих на величину ошибки или уровень неточности, необходимо рассмотреть несколько основных статистических концепций, лежащих в основе исторического тестирования. Так как я не большой любитель книг, напичканных формулами и пространными объяснениями, то постараюсь быть прост в аспекте математики и понятен в объяснениях. Статистические основы тестированияПравильное тестирование учитывает статистические концепции, влияющие на прогностические возможности тестов и присущие им ограничения. Неправильное тестирование может сделать вас чересчур доверчивыми там, где нет оснований воспринимать результаты тестов в качестве прогноза. Оно может дать даже совершенно неверные ответы. В главе 11 мы изучили все основные факторы, низводящие историческое моделирование на уровень грубого наброска будущего. Эта глава расскажет о том, как улучшить прогнозную составляющую тестов и узнать хоть и приблизительные, но максимально вероятные варианты развития событий. Область статистики, связанная с формированием выборки из совокупности, является также основой для прогнозного потенциала тестов с использованием исторических данных. Основная идея заключается в том, что при достаточно большой выборке вы можете в определенных пределах применять результаты расчетов по ней для оценки всей совокупности. Поэтому если при выработке стратегии вы посмотрите на достаточно большую выборку прошлых сделок, то сможете сделать заключение о вероятном будущем развитии этой системы. Это тот же раздел статистики, который используют организации, изучающие общественное мнение. Например, опрашивая 500 случайно выбранных людей из разных штатов, имеющих право голоса, можно сделать вывод о настроениях всех голосующих жителей США. Аналогичным образом ученые оценивают действие лекарства для лечения какой-либо болезни на небольшой группе пациентов, так как для этого есть статистическая основа. Два основных фактора, влияющих на статистическую достоверность предположений, основанных на изучении выборки, – это размер выборки и степень, в которой выборка является репрезентативной по отношению ко всей совокупности. Многие трейдеры и тестеры систем понимают смысл размера выборки на концептуальном уровне, однако полагают, что размер относится лишь к количеству сделок в тестовом исследовании. Они не понимают, что статистическая достоверность тестов может быть снижена даже при изучении тысяч сделок в случаях, когда правила или концепции применяются только к некоторым характеристикам сделок. Также они часто игнорируют необходимость репрезентативности выборки относительно всей совокупности – и в этих случаях исследование становится запутанным, а измерения затрудняются без проведения субъективного анализа. Трейдер, тестирующий систему, предполагает, что прошлое в определенной степени представляет то, что принесет будущее. Если это действительно так, а выборка является достаточной, мы можем взять некоторые черты прошлого и применять их для оценки будущего. Если выборка нерепрезентативна, тестирование бесполезно и ничего не скажет нам о возможном будущем поведении тестируемой системы. Таким образом, предположение о репрезентативности является критически важным. Если считать, что репрезентативная выборка из 500 человек достаточна для того, чтобы определить с точностью до 2 процентов, кто может быть следующим президентом США, хватит ли опроса 500 участников Демократического национального собрания (органа, избирающего кандидата на должность президента от Демократической партии США) для получения картины по стране в целом? Конечно, нет – выборка не будет репрезентативной с точки зрения всего населения. Она будет состоять только из демократов, в то время как голосующее население США состоит также из республиканцев, не включенных в выборку. Возможно, республиканцы будут голосовать не за тех кандидатов, которые определились в вашем опросе. Если вы делаете ошибки такого рода в выборке, то в результате получите ответ, возможно, желаемый, но неправильный. Социологи знают, что вопрос соответствия выборки совокупности является основным. Результаты опросов, проводимых с нерепрезентативной выборкой, являются неточными, и за проведение таких опросов увольняют. В трейдинге это тоже является ключевым вопросом. К сожалению, в отличие от социологов, которые в целом понимают статистику выборки, большинство трейдеров ее не понимают. Часто можно наблюдать, как трейдеры тестируют только недавние периоды. Это все равно что проводить опрос членов Демократического собрания о следующем президенте США. Проблема тестов, проводимых на небольших интервалах, состоит в том, что за время такого интервала рынок может находиться в одном из двух состояний, описанных ранее в главе 2, например в состоянии стабильности (отсутствия тренда) и волатильности – в этих случаях хорошо работают стратегии торговли против тренда и учет отклонений от среднего значения. Однако если рынок изменяет свое состояние, методы тестирования становятся неприменимыми; их использование в этом случае приведет к потере денег. Поэтому тестирование должно проводиться таким образом, чтобы увеличить шансы на репрезентативность с точки зрения будущего сделок, включенных в тест. Существующие измерения неустойчивыПроводя тестирование, вы пытаетесь определить относительную результативность системы, оценить возможную результативность в будущем, а также выяснить, насколько обоснованна та или иная идея. Одна из проблем этого процесса состоит в том, что общепринятые показатели измерения нестабильны. Поэтому сравнительная оценка той или иной идеи затруднена – небольшие изменения за счет одной-двух сделок способны существенно повлиять на значения этих слабых показателей. Вследствие нестабильности измерений вы можете поверить в то, что идея более ценна, чем на самом деле, или отказаться от идеи, потому что она не кажется столь привлекательной, каковой является на самом деле, если к ее измерению применить более стабильные показатели. Статистические исследования являются устойчивыми, если изменение небольшого набора данных не приводит к существенным изменениям результатов. Существующие показатели измерения слишком чувствительны к изменениям данных. Это одна из причин того, что при проведении исторического моделирования при анализе торговых систем небольшие изменения значения параметра существенно изменяют значения результирующих показателей. Сами по себе показатели не являются устойчивыми, иначе говоря, они чувствительны к небольшим информационным массивам. Соответственно, все, что влияет на эти информационные массивы, способно также существенно повлиять на результаты. В итоге дело может закончиться подгонкой, и вы будете дурачить себя результатами, недостижимыми в реальной жизни. Первый шаг в тестировании согласно Пути Черепах состоит в том, чтобы найти показатели измерения результативности, которые являются устойчивыми и независимыми от небольших изменений в исходных данных. Во время собеседования перед началом программы Черепах Билл Экхардт спросил меня: «Знаешь ли ты, что такое устойчивый статистический показатель?» Я помолчал немного, а затем сказал: «Не имею никакого представления». Теперь я могу ответить на этот вопрос. Речь идет о разделе математики, занимающемся проблематикой несовершенной информации и неправильными предположениями, называемом статистикой надежности или робастной статистикой. Из самого вопроса было ясно, что Билл осознавал несовершенную природу тестирования и исследования на базе исторической информации, а также понимал суть непознаваемого, – редкое качество для тех времен (да и теперь). Я думаю, что в этом и заключалась причина отличных результатов трейдинга Билла на протяжении многих лет. Это – еще один пример того, насколько далеко по сравнению с другими игроками в отрасли продвинулись в своих исследованиях и размышлениях Рич и Билл. Чем больше я учусь, тем большее уважение испытываю к их вкладу в нас. И меня крайне удивляет, как недалеко продвинулась отрасль относительно того, что Рич и Билл знали в еще 1983 году. Устойчивые показатели измерения результативностиРанее мы говорили о таких показателях измерения сравнительной результативности, как коэффициент MAR, CAGR% и коэффициент Шарпа. Эти показатели не очень устойчивы, так как существенно зависят от дат начала и окончания периода тестирования. Это особенно справедливо для тестов менее чем 10-летних периодов. Представьте себе, что случится, если мы скорректируем сроки начала и окончания теста на несколько месяцев. Для этого проведем тест не с начала января 1996 года, а с начала февраля того же года. В качестве срока окончания возьмем не 30 июня 2006 года, а 30 апреля – то есть уберем всего один месяц с начала и два месяца с конца тестируемого периода. Тест тройной скользящей средней с первоначальными данными дал нам 43,2 процента отдачи с коэффициентом MAR, равным 1,39, и коэффициентом Шарпа, равным 1,25. Если изменить даты начала и окончания, отдача подскочит до 46,2 процента, коэффициент MAR вырастет до 1,39, а коэффициент Шарпа – до 1,37. Тест системы прорыва канала ATR с первоначальным периодом демонстрирует отдачу на уровне 51,7 процента, коэффициент MAR, равный 1,31, и коэффициент Шарпа, равный 1,39. Меняем период – меняются показатели. Отдача подскакивает до 54,9 процента, коэффициент MAR вырастает до 1,49, а коэффициент Шарпа – до 1,47. Такая чувствительность по всем трем измерениям объясняется тем, что MAR и коэффициент Шарпа содержат отдачу в качестве части числителя, а отдача, выраженная в процентах CAGR при расчете MAR или в среднемесячном показателе отдачи при расчете коэффициента Шарпа, существенно зависит от срока начала или окончания теста. MAR особо чувствителен к изменению сроков теста, так как в нем содержатся два компонента, зависимых от сроков теста. Таким образом, при расчете этого показателя эффект изменений усиливается в разы. Причина, по которой CAGR% зависит от начала и окончания тестируемого периода, заключается в том, что на логарифмической шкале показатель представляет собой градус наклона линии, начинающейся в начале теста и заканчивающейся в момент его окончания. Изменение дат начала и окончания тестируемого периода существенно меняет наклон линии, как показано на рисунке 12-1. Рисунок 12-1. Эффект воздействия изменения начальной и конечной даты на CAGR% 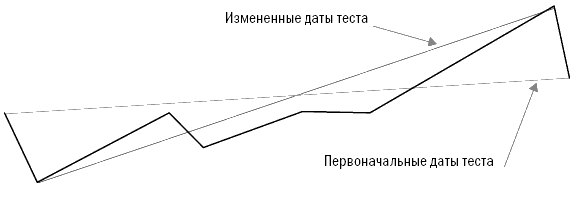 Заметьте, что наклон линии, называемой «Измененные даты теста», круче, чем наклон линии под названием «Первоначальные даты теста». В данном случае в начале тестируемого периода (январь 1996 года) произошло падение, также падение наблюдалось в мае и июне 2006 года, последних месяцах первоначального периода. Соответственно, сдвигая даты теста на несколько месяцев, мы смогли избавиться от результатов обоих падений. Это отмечено на рисунке 12-1: убрав падение на любом этапе теста, мы повысим наклон линии, определяющей CAGR%. Регрессированная годовая отдача (RAR%)Более подходящим методом оценки наклона является простая линейная регрессия каждой точки на каждой линии. Для тех читателей, которые не любят математику, поясню, что линейная регрессия – это просто мудреное название того, что именуется линией полного соответствия. Представьте себе прямую линию, проходящую через центр всех точек, как если бы вы убрали все выпуклости на графике, растянув их за края, не меняя общего направления линии. Линия линейной регрессии и соответствующий показатель отдачи создают возможность для формирования нового показателя, который я называю регрессированной годовой отдачей (Regressed Annual Return, RAR%). Этот показатель в гораздо меньшей степени чувствителен к изменениям данных в конце теста. На рисунке 12-2 показано, что при применении RAR% наклон линии практически не меняется при изменении конечной точки. Если мы теперь повторим тестирование, проведенное ранее, то заметим, что показатель RAR% менее зависим от изменений периода тестирования, потому что у обеих линий наблюдается примерно одинаковый наклон. RAR% для первоначального теста составляет 54,67 процента, а для теста с измененными датами он составляет 54,78 процента, что всего на 0,11 процента выше. Сравните эти результаты с результатами CAGR%, изменившимися на целых 3 процента, с 43,2 до 46,2 процента. В рамках данного теста CAGR% был почти в 30 раз более чувствителен к изменению конечных дат. Рисунок 12-2. Эффект воздействия изменения начальной и конечной даты на RAR% 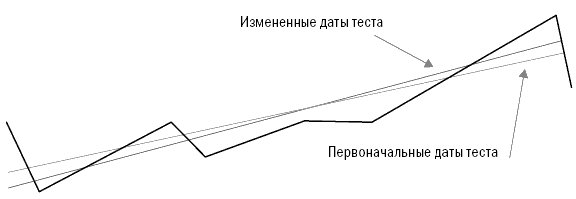 Значение среднемесячной отдачи, используемое при расчете коэффициента Шарпа, также зависит от изменений дат, так как мы исключаем из тестирования три последних плохих месяца, а это влияет на среднюю отдачу, хотя и в меньшей степени, чем на CAGR%. Лучшим показателем для числителя мог бы стать RAR%. Как было отмечено ранее, компонент, связанный с величиной максимального падения в расчете коэффициента MAR, также чувствителен к датам начала и окончания теста. Если крупное падение происходит в начале тестового периода или ближе к его окончанию, показатель MAR изменится достаточно существенно. Показатель максимального падения – это лишь одна точка на кривой капитала; соответственно, для корректных расчетов нам не хватает существенного объема данных. Наилучшим показателем является тот, который включает больше значений падения. Гораздо сложнее торговать по системе, в которой было пять крупных падений на уровне 32, 34, 35, 35 и 36 процентов, чем по системе, в которой падения были на уровне 20, 25, 26, 29 и 36 процентов. Более того, глубина падения – это лишь одно измерение. Все 30-процентные падения неодинаковы. Я обращаю меньше внимания на недавнее падение, которое продолжалось всего два месяца, чем на падение, которое продолжалось два года, пока рынок не вернулся к прежним значениям. Период возвращения к прежнему значению (продолжительность падения) важен сам по себе. R-cubed – новое соотношение риска и доходностиЧтобы учесть все эти факторы, я создал новый показатель измерения соотношения риск/доходность, который назвал устойчивым показателем соотношения риск/доходность (Robust Risk/Reward Ratio, или RRRR). Я также называю его R-cubed (или R в кубе) – просто потому, что люблю дурацкие псевдонаучные названия. R-cubed использует в качестве числителя RAR%, а в качестве знаменателя – новый показатель, который я называю средним максимальным падением с учетом продолжительности. В этом показателе присутствуют два компонента – величина среднего максимального падения и приведенная продолжительность. Среднее максимальное падение высчитывается путем сложения показателей пяти максимальных падений и деления результата на 5. Приведенная продолжительность рассчитывается путем деления среднего максимального падения в днях на 365 и последующего умножения полученного показателя на величину среднего максимального падения. Величина среднего максимального падения рассчитывается по тому же алгоритму: мы берем величины пяти максимальных падений, складываем и делим на 5. Соответственно, если RAR% составляет 50 процентов, среднее максимальное падение составляет 25 процентов, а средняя продолжительность максимального падения составляла один год, или 365 дней, значение R-cubed должно составлять 2,0, или 50 % / (25 % x 365 / 365). R-cubed – это соотношение риска/доходности, которое оценивает риск с точки зрения как жесткости, так и перспектив продолжительности. Такое вычисление возможно благодаря использованию показателей, менее чувствительных к изменению дат начала и окончания тестовых периодов. Этот показатель более устойчив, чем MAR, так как очень слабо реагирует на небольшие корректировки в условиях теста. Устойчивый коэффициент Шарпа (Robust Sharpe Ratio)Устойчивый коэффициент Шарпа выводится путем деления RAR% на стандартное отклонение ежемесячной отдачи, нормализованное по году. Этот показатель менее зависим от изменений периода тестирования по тем же причинам, по которым RAR% отличается от CAGR%, как было показано выше. Таблица 12-1 свидетельствует, что сильные показатели существенно менее зависимы от изменений конечных дат тестового периода. Таблица 12-1. Обычные и устойчивые показатели 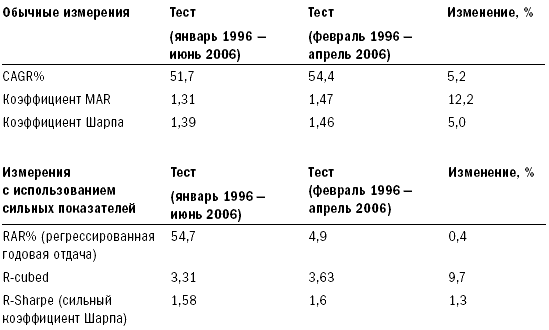 Copyright 2006 Trading Blox, все права защищены. Как видим, устойчивые показатели менее чувствительны, чем общепринятые показатели. Показатель R-cubed зависим от добавления или исключения величин крупных падений, но в меньшей степени, чем коэффициент MAR. При расчете показателя R-cubed влияние отдельного падения размывается путем усреднения. Все устойчивые показатели были в меньшей степени подвержены влиянию изменений в наборе данных, чем сравниваемые с ними показатели. Если бы в рамках теста не менялась величина максимального падения, то показатель R-cubed показал бы то же самое изменение в 0,4 процента, что и RAR%, и это сделало бы различия между показателями еще более существенными: MAR изменился бы на 5,2 процента (на ту же величину, что и CAGR% – его числитель), a R-cubed – всего на 0,4 процента. Еще одним примером того, как устойчивые показатели выигрывают по сравнению с традиционными, является сравнение результатов деятельности шести базовых систем, описанное нами в главе 7. Если вы помните, при включении дополнительных пяти месяцев (июль – ноябрь 2006 года) мы столкнулись с существенным ухудшением показателей отдачи. Таблицы 12-2 и 12-3 демонстрируют, что устойчивые показатели гораздо лучше выдержали существенные колебания последних нескольких месяцев. Таблица 12-2 показывает изменения RAR% по сравнению с изменением CAGR% для этих систем. RAR% изменился в шесть раз меньше, чем CAGR% за тот же период времени. Это свидетельствует о том, что RAR% гораздо более устойчивый показатель, чем CAGR%, а значит, он будет более стабилен в ходе трейдинга. То же самое справедливо для R-cubed, соотношения риска и доходности, по сравнению с его более слабым собратом – коэффициентом MAR. Таблица 12-3 показывает процентные изменения R-cubed по сравнению с процентными изменениями MAR для тех же систем. Таблица 12-2. Устойчивость RAR% по сравнению с CAGR% 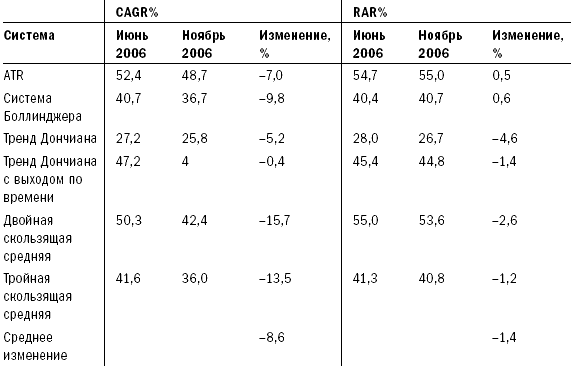 Таблица 12-3. Устойчивость R-cubed по сравнению с MAR 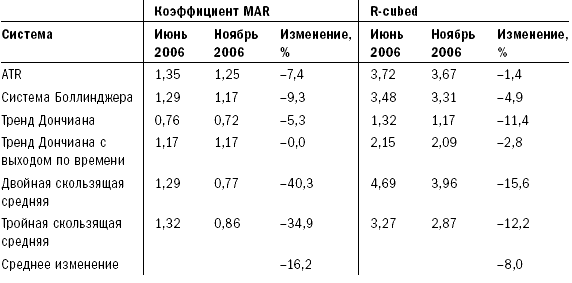 R-cubed за указанный период изменился в два раза меньше, чем MAR. Устойчивые показатели также менее зависимы от эффекта удачи. Например, трейдер, оказавшийся в отпуске и пропустивший крупнейшее падение, получит более высокое значение MAR по сравнению со своими коллегами. Это будет заметно при расчете R-cubed, так как данное обстоятельство не окажет значительного влияния на его расчет. Если вы используете неустойчивые показатели, то велик шанс получить хорошие результаты тестирования, обусловленные удачей, а не последовательным поведением на рынке, – и это еще одна причина использовать устойчивые показатели. Использование устойчивых показателей также позволит вам избежать подгонки, так как эти показатели в меньшей степени будут зависеть от больших изменений результата, связанных с небольшим количеством событий. Давайте рассмотрим ситуацию применения правил для улучшения нашей системы двойного скользящего среднего, ранее описанной при обсуждении подгонки. Правило, введенное для уменьшения размера падения, улучшило величину показателя CAGR% с 41,4 до 45,7 процентов (то есть на 10,3 процента), а коэффициент MAR – на 60 процентов (с 0,74 до 1,17). В отличие от него показатель RAR% изменился с 53,5 до 53,75 процента, то есть всего на 0,4 процента, а устойчивый показатель соотношения риска/доходности R-cubed изменился с 3,29 до 3,86 процента, то есть всего на 1,73 процента. Устойчивые показатели в меньшей степени отражают существенные изменения, вызванные небольшим количеством сделок. Таким образом, если подгонка кривой позволяет исправить неудачи нескольких сделок, то устойчивые показатели вряд ли покажут улучшения системы, вызванные такой подгонкой. Давайте рассмотрим, какие другие факторы влияют на надежность тестирования данных прошлого с целью предсказания будущего поведения системы. Репрезентативные выборкиРепрезентативность наших тестов для целей предсказания будущего определяется двумя факторами: – Количество рынков: тесты, проводимые на различных рынках, будут, скорее всего, включать рынки с разной степенью волатильности типов тренда. – Продолжительность теста: тесты, проводимые на более продолжительных периодах, учитывают различные состояния рынка и с большей вероятностью включают периоды, в которых прошлое сопоставимо с будущим. Я рекомендую проводить тестирование на всех данных, которые будут вам доступны. Вы заплатите гораздо меньше за доступ к данным, нежели за использование системы, которая, по вашему мнению, работала, но только потому, что вы не протестировали ее на достаточном количестве рынков или за достаточное количество лет. Не почувствуете ли вы себя дураком, когда ваша система перестанет работать из-за того, что рынок пришел в состояние, которое уже наблюдалось три или четыре раза на протяжении последних двадцати лет, не включенных в ваш тест? Этой ошибке часто подвержены молодые трейдеры. Они полагают, что наблюдаемое ими состояние является репрезентативным для всех рынков в целом. Часто они не понимают, что рынки проходят через различные этапы и меняются со временем, зачастую возвращаясь к тому состоянию, в котором были когда-то. Молодежь в трейдинге, как и в жизни вообще, не желает изучать историю, существовавшую до момента их появления. Будьте молодыми, но не будьте глупыми – изучайте историю. Помните те времена интернет-бума, когда буквально каждый был дейтрейдером и гением? Сколько этих гениев пережило коллапс, когда их прежде удачные методы перестали работать? Если бы они провели тестирование, то поняли бы, что их методы зависели от конкретных рыночных условий бума, поэтому они должны были отказаться от их использования, как только эти условия перестали существовать. Или, как вариант, они могли бы взять на вооружение устойчивые методы, хорошо работающие во всех условиях. Размер выборкиКонцепция размера выборки проста: для того чтобы делать статистически достоверные заключения, нужно иметь достаточно большую выборку. Чем меньше выборка, тем грубее выводы, которые можно сделать; чем выборка больше, тем выводы качественнее. Нет никакого волшебного количества – просто чем больше, тем лучше, а чем меньше, тем хуже. Выборка из 20 и менее элементов содержит большую вероятность ошибки. Выборка из 100 и более значений с большей вероятностью может использоваться для прогнозирования. Для большинства тестов обычно достаточно выборки в несколько сотен значений. Есть несколько специальных формул и методов, позволяющих оценить требуемую величину выборки, однако эти формулы не предназначены для данных, используемых в трейдинге, где у нас просто нет такого прекрасного распределения возможных исходов, как, например, распределение женщин по росту, показанное на рисунке 4–3 в главе 4. Однако проблема состоит не в том, как много элементов выборки вам нужно. Проблема возникает при оценке прошлого, а именно случаев, когда определенные правила вступали в силу достаточно редко. Поэтому для этих типов правил просто невозможно получить большую выборку. Возьмем, к примеру, поведение на рынке на последней стадии роста ценовых «пузырей». Для этих условий можно придумать правила и даже протестировать их, однако выборка будет слишком мала для принятия решения. В таких случаях важно понимать, что результаты теста не будут иметь ничего общего с тем, что мы могли бы узнать, если бы выборка была больше. Ранее отмеченные мной сезонные явления представляют область, в которой возникают аналогичные проблемы. Тестируя новые правила для системы, вы должны оценивать, как часто эти правила оказывают влияние на результат. Если за все время проведения теста правило воздействовало на результат всего четыре раза, то у вас нет статистических достоверных оснований, чтобы определить, работает оно или нет. Вполне возможно, что замеченные вами эффекты были вызваны случайными причинами. Одним из решений ситуации является изменение правила для того, чтобы оно вступало в действие чаще, – это увеличит размер выборки, а тем самым статистическую описательную ценность тестов для этого правила. Помимо размера выборки есть еще две проблемы, которые, однако, зачастую игнорируются: – Оптимизация под отдельный рынок: гораздо сложнее тестировать с помощью достаточного размера выборки методы оптимизации, предназначенные для каждого отдельного рынка, так как на каждом отдельно взятом рынке существует меньше возможностей для трейдинга. – Сложные системы: в сложных системах есть много правил. Поэтому со временем становится сложно определить, сколько раз применялось каждое правило, а также каково было его влияние. Таким образом, становится сложнее доверять статистической значимости тестов, проводимых с использованием сложных систем. По этим причинам я не рекомендую проводить оптимизацию для отдельных рынков и предпочитаю простые идеи, статистическое значение которых гораздо выше. Назад в будущееГлавный вопрос, интересующий всех, звучит так: «Как можно определить возможный исход будущего реального трейдинга?» Чтобы ответить на него, нужно понимать факторы, вызывающие потери, необходимость точных показателей и достаточного количества репрезентативных примеров. Исходя из этого, вы можете размышлять об эффектах изменений на рынках и о том, почему даже прекрасные системы, выстроенные опытными трейдерами, достаточно изменчивы с точки зрения отдачи. Реальность такова, что вы не знаете и не можете предсказать, как будет вести себя система. Лучшее, что вы можете сделать, это использовать инструменты, позволяющие определить набор возможных значений, и выявить факторы, влияющие на эти значения. Удачливые системыТот факт, что какая-то система в недавнем прошлом сработала хорошо, может быть связан с простой удачей или идеальными условиями на рынке в тот момент именно для данной системы. В целом хорошо работающим системам свойственно после успешных периодов испытывать плохие времена. Не ждите, что сможете повторить отличные результаты еще раз. Это может случиться, но на это не стоит полагаться. Скорее всего, в ближайшем будущем вам предстоит период частично удачной деятельности. Параметры вперемешкуВсем желающим начать торговлю по какой-либо системе я предлагаю выполнить следующее упражнение. Возьмите несколько параметров системы и существенно поменяйте их значения, например на 20 или 25 процентов. Выберите точку, расположенную значительно ниже кривых оптимизации, изображенных на рисунках 12-1 и 12-2. Теперь посмотрите на результаты теста. Используя систему прорыва Боллинджера, я решил посмотреть, что произойдет, если мы изменим оптимальные значения с 350 дней и -0,8 в качестве порога выхода на 250 дней и 0,0 соответственно. Такие значения уменьшили RAR% с 59 процентов до 58 процентов, а значение R-cubed сократилось с 3,67 до 2,18 – достаточно значительное снижение. Это только один пример серьезных изменений, которые можно обнаружить при переходе от использования исторических данных к реальному трейдингу на рынке. Окна повторяющейся оптимизацииЕще одно упражнение, более тесно, чем предыдущее, связанное с практикой перехода от тестирования к трейдингу. Для проведения упражнения выберите дату за истекший 8 – 10-летний период, а затем проведите оптимизацию всех данных до этой даты, используя те же методы оптимизации, что вы использовали бы в обычных условиях при ваших обычных допущениях. Просто представьте себе, что единственные данные, которые у вас есть, – это данные по состоянию на выбранную вами дату. После того как вы определили оптимальные значения параметров, проведите тестирование с включением двух лет после избранной вами даты. Как изменились результаты с учетом последующих лет? Продолжите процесс, добавив еще несколько лет из прошлого. Как соотносятся результаты этого теста с результатами первичного тестирования и первым окном повторяющейся оптимизации? Насколько сопоставимы результаты первичного тестирования с данными, рассчитанными на основании всей имеющейся информации? Продолжайте процесс до тех пор, пока не достигнете настоящего времени. Чтобы проиллюстрировать это упражнение, я провел оптимизацию систем прорыва Боллинджера, в рамках которой менял каждый из трех параметров в достаточно широких пределах. После этого я выбрал оптимальный набор значений, расположенный недалеко от точки, в которой был достигнут максимум значения R-cubed. Я произвел оптимизацию в рамках пяти независимых тестов. В таблице 12-4 показаны результаты повторяющейся оптимизации за год после указанного периода. Таблица 12-4. Повторяющаяся оптимизация и реальный RAR% 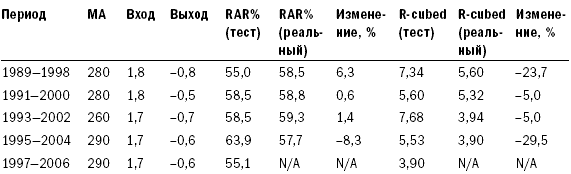 Copyright 2006 Trading Blox, все права защищены. Как видно из таблицы, результаты существенно различаются по каждому тестируемому периоду. Более того, оптимальные значения для каждого тестируемого периода различны. Это подтверждает неточность процессов тестирования и свидетельствует о том, что при переходе от тестов к реальному трейдингу вы непременно столкнетесь с неожиданным положением вещей. Моделирование по методу Монте-КарлоМоделирование по методу Монте-Карло представляет собой способ определения силы системы и отвечает на вопросы: «Что могло бы произойти, если бы прошлое было чуть другим?» или «Что может принести будущее?» Вы можете рассматривать метод как способ создания альтернативных ситуаций на основании набора данных, составляющих реальный набор данных о ценах. Моделирование по Монте-Карло относится к классу методов, использующих случайный набор данных для исследования какого-либо феномена. Оно в особенности применимо для ситуаций, точное математическое моделирование которых невозможно или затруднено. Название Монте-Карло происходит от города в Монако, известного своими казино, предлагающими большое количество игр, исход которых зависит от случайности, – например рулетка, блэкджек, кости и т. п. Метод использовался в ходе Манхэттенского проекта учеными, работавшими над созданием атомной бомбы, так что его название уходит корнями в ту эпоху. Тогда ученые пытались определить характеристики расщепления урана, чтобы рассчитать точную массу урана, необходимую для создания бомбы. Обогащенный уран был крайне дорог, поэтому они не могли себе позволить ошибиться в расчетах – в противном случае они потеряли бы месяцы (не говоря уже о деньгах), если бы бомба не взорвалась из-за недостаточного количества в ней урана. Аналогично, если бы они ошиблись в другую сторону, посчитав, что нужно большее количество урана, чем требовалось на самом деле, то тестирование пришлось бы отложить на месяцы. К сожалению, с помощью существовавших тогда методов невозможно было создать модель поведения атомов урана в бомбе, а компьютерные ресурсы, способные справиться с этой задачей, появились гораздо позже. Для определения количества расщепляемого урана им необходимо было узнать, какая доля нейтронов при расщеплении атома может привести к расщеплению другого атома. Известный физик Ричард Фейнман предположил, что они могут определить характеристики поведения отдельного нейтрона с помощью команды математиков, чтобы затем установить, был ли нейтрон поглощен другим ядром или расщепил другой атом. Фейнман понял, что для отображения различных типов нейтронов при расщеплении атома можно использовать случайные числа. Произведенное несколько тысяч раз, это действие позволило бы им пронаблюдать за распределением характеристик расщепления урана и определить необходимое его количество. Фейнман знал, что будущее предсказать невозможно, так как процесс был очень сложным, но он мог взять те части проблемы, которые понимал, и, используя случайные числа для моделирования особенностей нейтронов, получить ответ на требуемый вопрос. Он сумел понять характеристики расщепления урана в целом, хотя и не мог точно предсказать, что будет происходить с каждым атомом в какой-то момент времени. Альтернативные ситуации в трейдингеПоведение рынков, которые формируются действиями тысяч людей, руководствующихся собственным опытом и мышлением, гораздо сложнее, чем чисто физические процессы расщепления атомов. К счастью, подобно Фейнману и его анализу, мы можем использовать случайные значения для лучшего понимания потенциальных характеристик системы трейдинга, хотя и не знаем, что может принести будущее. Мы можем изучить набор различных альтернативных ситуаций, вариантов развития событий в случае немного другого исходного состояния. Для создания таких альтернативных ситуаций в методе Монте-Карло используется один из двух способов: – Сделки вперемешку: порядок и начальные даты сделок перемешиваются случайным образом, а затем потери или доходы в процентах используются для корректировки размера капитала путем открытия новой сделки. – Кривая капитала вперемешку: выстраивание новых кривых капитала путем сбора случайных частей первоначальной кривой капитала. Если сравнить эти два метода, то кривая вперемешку позволяет строить более реалистичные кривые капитала, так как метод Монте-Карло с изменением очередности сделок может привести к недооценке величины падений. Периоды максимального истощения обязательно возникают в конце больших трендов или периодов быстрого роста капитала. В эти времена корреляция рынков вырастает по сравнению с обычными моментами. Это правдиво как для рынков ценных бумаг, так и для фьючерсов. В конце большого тренда, когда он прерывается и меняет направление, кажется, что все сразу начинает двигаться против тебя: даже рынки, прежде казавшиеся некоррелировавшими, становятся таковыми в волатильные дни прекращения большого тренда. Так как смешивание сделок устраняет связь между сделками и их датами, оно также устраняет эффект влияния на кривую капитала в случаях, когда многие сделки одновременно закрываются и меняются на противоположные. Это означает, что длительность и частота ваших периодов истощения при применении метода будут показаны меньшими, чем на самом деле. Возьмите, к примеру, изменения цен на золото и серебро весной 2006 года. Если бы вы тестировали систему следования тренду, работающую на этих рынках, то перемешивание сделок означало бы, что периоды истощения для этих рынков произошли в разное время, что существенно сократило бы эффект каждого отдельного падения. На самом деле этот эффект воздействовал на другие, на первый взгляд не связанные рынки, такие как рынок сахара: в тот же период, когда падали цены на золото и серебро (20 дней с середины мая по середину июня 2006 года), на рынке сахара также наблюдалось падение. Таким образом, смешивание сделок – неподходящий метод, так как он недооценивает уровни истощения, с которыми неизбежно сталкиваются трейдеры, использующие долгосрочные и среднесрочные системы. Другим примером такого рода служит однодневное падение на фондовом рынке США в 1987 году. В день, когда при открытии возник кризис на рынке евродолларов, я обнаружил, что аналогичная ситуация наблюдается и на других рынках, обычно не коррелирующих с евродолларами. Смешивание сделок по методу Монте-Карло обычно размывает эффект таких фактов, потому что разделяет сделки, проведенные в одном и том же направлении в одни и те же дни. Многие программные продукты, позволяющие делать расчеты по методу Монте-Карло, дают возможность выстраивать новые кривые, возникающие при смешивании кривых капитала. Однако они не принимают в расчет один важный момент. В ходе тестирования и практического опыта я обнаружил, что влияние периода плохих дней в конце большого тренда заметно большее, чем можно ожидать от случайного события. В эти периоды существенного истощения кривая капитала для системы следования за трендом демонстрировала серийную корреляцию или корреляцию между величиной изменения в текущий и предшествующий день. Проще говоря, плохие дни группируются таким образом, что это сложно объяснить случайными факторами. Давайте вернемся к недавно описанному примеру с падением на рынках золота, серебра и сахара весной 2006 года. Если перемешать только величины ежедневных изменений, то будет потерян достаточно длинный период существенных колебаний размера капитала в период с середины мая по середину июня, так как маловероятно, что эти изменения вновь окажутся рядом при случайной выборке, даже если взяты из реальной кривой. Чтобы учесть это в программах моделирования, мы в компании Trading Blox также используем изменения значения кривой капитала, однако позволяем сделать выборку не по дневным значениям, а по значениям нескольких дней. Этот метод позволяет группировать вместе плохие дни, возможные в реальном трейдинге. В рамках моего теста я брал 20-дневные интервалы для перемешивания кривых капитала и обнаружил, что это может предотвратить автокорреляцию кривой капитала и позволяет модели приобрести более реалистичный вид для целей прогнозирования. Рисунок 12-3. Распределение RAR%, рассчитанного по методу Монте-Карло 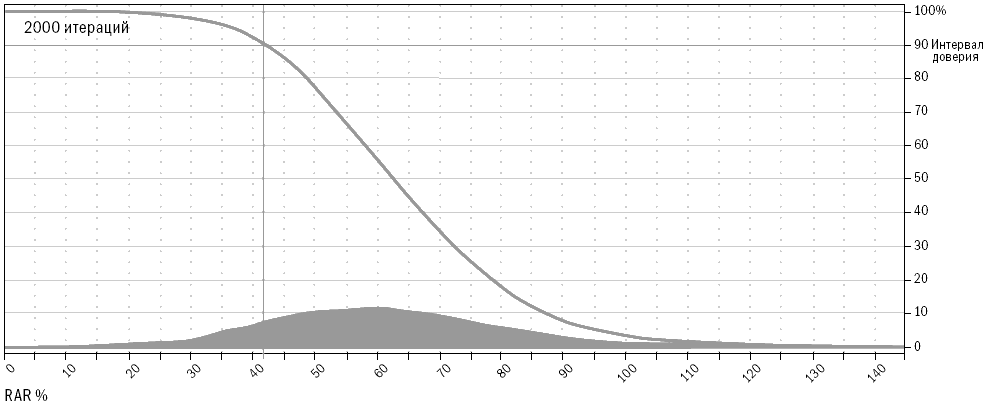 Copyright 2006 Trading Blox, все права защищены. Отчеты по методу Монте-КарлоЧто можно сделать с моделируемыми альтернативными кривыми капитала, получаемыми с помощью метода Монте-Карло? Мы можем использовать их при построении распределения результатов для определенного показателя, с тем чтобы определить набор вариантов, возможных в случае, если будущее напоминает одну из наших альтернативных смоделированных ситуаций. На рисунке 12-3 изображено распределение 2000 альтернативных вариантов кривых капитала, для каждой из которых рассчитан показатель RAR%, а затем на график нанесены распределения значений этих кривых. Вертикальная линия, пересекающая кривую вверху графика, показывает величину RAR%, которой достигли 90 процентов из 2000 смоделированных кривых капитала. В нашем случае этого уровня достигли 42 процента RAR%. Графики такого рода хороши тем, что позволяют понять непредсказуемый характер будущего, зависящий от множества вариантов. Однако не следует вчитываться в такие отчеты слишком внимательно. Помните, что эти цифры взяты из кривой капитала, зависящей от исторических данных, и поэтому страдают от недостатков, описанных в главе 11. Моделирование по методу Монте-Карло не делает плохой тест хорошим, так как моделируемые кривые капитала точны настолько, насколько точно историческое тестирование, на котором они базируются. Если ваш показатель RAR% переоценен на 20 процентов из-за парадокса оптимизации, метод Монте-Карло для оптимизированных значений параметра будет также переоценивать RAR% для всех альтернативных кривых, сформированных в процессе моделирования. Лишь аппроксимацияКак показали проделанные выше упражнения, тестирование прошлого является лишь грубой аппроксимацией возможного состояния дел в будущем. Устойчивые показатели лучше прогнозируют будущее, чем их более чувствительные собратья, однако результат все равно остается неточным. Каждый, кто говорит вам, что вы можете рассчитывать на определенный уровень отдачи, либо лжет (особенно если при этом он пытается вам что-то продать), либо не знает, о чем говорит. В главе 13 мы рассмотрим некоторые из методов, направленных на укрепление вашего трейдинга, – это сделает вас менее чувствительными к диким скачкам реальных результатов. |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||