|
||||
|
|
12.2 ГЛАВНЫЙ И ПОДЧИНЕННЫЙ ПРОЦЕССОРЫ 12.3 СЕМАФОРЫ 12.3.1 Определение семафоров 12.3.2 Реализация семафоров 12.5 УЗКИЕ МЕСТА В ФУНКЦИОНИРОВАНИИ МНОГОПРОЦЕССОРНЫХ СИСТЕМ 12.6 УПРАЖНЕНИЯ ГЛАВА 12. МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ В классической постановке для системы UNIX предполагается использование однопроцессорной архитектуры, состоящей из одного ЦП, памяти и периферийных устройств. Многопроцессорная архитектура, напротив, включает в себя два и более ЦП, совместно использующих общую память и периферийные устройства (Рисунок 12.1), располагая большими возможностями в увеличении производительности системы, связанными с одновременным исполнением процессов на разных ЦП. Каждый ЦП функционирует независимо от других, но все они работают с одним и тем же ядром операционной системы. Поведение процессов в такой системе ничем не отличается от поведения в однопроцессорной системе — с сохранением семантики обращения к каждой системной функции — но при этом они могут открыто перемещаться с одного процессора на другой. Хотя, к сожалению, это не приводит к снижению затрат процессорного времени, связанного с выполнением процесса. Отдельные многопроцессорные системы называются системами с присоединенными процессорами, поскольку в них периферийные устройства доступны не для всех процессоров. За исключением особо оговоренных случаев, в настоящей главе не проводится никаких различий между системами с присоединенными процессорами и остальными классами многопроцессорных систем. Параллельная работа нескольких процессоров в режиме ядра по выполнению различных процессов создает ряд проблем, связанных с сохранением целостности данных и решаемых благодаря использованию соответствующих механизмов защиты. Ниже будет показано, почему классический вариант системы UNIX не может быть принят в многопроцессорных системах без внесения необходимых изменений, а также будут рассмотрены два варианта, предназначенные для работы в указанной среде. 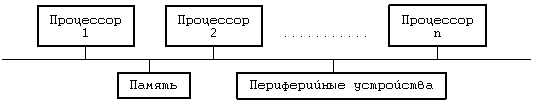 Рисунок 12.1. Многопроцессорная конфигурация 12.1 ПРОБЛЕМЫ, СВЯЗАННЫЕ С МНОГОПРОЦЕССОРНЫМИ СИСТЕМАМИВ главе 2 мы говорили о том, что защита целостности структур данных ядра системы UNIX обеспечивается двумя способами: ядро не может выгрузить один процесс и переключиться на контекст другого, если работа производится в режиме ядра, кроме того, если при выполнении критического участка программы обработчик возникающих прерываний может повредить структуры данных ядра, все возникающие прерывания тщательно маскируются. В многопроцессорной системе, однако, если два и более процессов выполняются одновременно в режиме ядра на разных процессорах, нарушение целостности ядра может произойти даже несмотря на принятие защитных мер, с другой стороны, в однопроцессорной системе вполне достаточных. struct queue {} *bp, *bp1; bp1-›forp = bp-›forp; bp1-›backp = bp; bp-›forp=bp1; /* рассмотрите возможность переключения контекста в этом месте */ bp1-›forp-›backp =b p1; Рисунок 12.2. Включение буфера в список с двойными указателями В качестве примера рассмотрим фрагмент программы из главы 2 (Рисунок 12.2), в котором новая структура данных (указатель bp1) помещается в список после существующей структуры (указатель bp). Предположим, что этот фрагмент выполняется одновременно двумя процессами на разных ЦП, причем процессор A пытается поместить вслед за структурой bp структуру bpA, а процессор B структуру bpB. По поводу сопоставления быстродействия процессоров не приходится делать никаких предположений: возможен даже наихудший случай, когда процессор B исполняет 4 команды языка Си, прежде чем процессор A исполнит одну. Пусть, например, выполнение программы процессором A приостанавливается в связи с обработкой прерывания. В результате, даже несмотря на блокировку остальных прерываний, целостность данных будет поставлена под угрозу (в главе 2 этот момент уже пояснялся). Ядро обязано удостовериться в том, что такого рода нарушение не сможет произойти. Если вопрос об опасности возникновения нарушения целостности оставить открытым, как бы редко подобные нарушения ни случались, ядро утратит свою неуязвимость и его поведение станет непредсказуемым. Избежать этого можно тремя способами: 1. Исполнять все критические операции на одном процессоре, опираясь на стандартные методы сохранения целостности данных в однопроцессорной системе; 2. Регламентировать доступ к критическим участкам программы, используя элементы блокирования ресурсов; 3. Устранить конкуренцию за использование структур данных путем соответствующей переделки алгоритмов. Первые два способа здесь мы рассмотрим подробнее, третьему способу будет посвящено отдельное упражнение. 12.2 ГЛАВНЫЙ И ПОДЧИНЕННЫЙ ПРОЦЕССОРЫ Систему с двумя процессорами, один из которых — главный (master) — может работать в режиме ядра, а другой — подчиненный (slave) — только в режиме задачи, впервые реализовал на машинах типа VAX 11/780 Гобл (см. [Goble 81]). Эта система, реализованная вначале на двух машинах, получила свое дальнейшее развитие в системах с одним главным и несколькими подчиненными процессорами. Главный процессор несет ответственность за обработку всех обращений к операционной системе и всех прерываний. Подчиненные процессоры ведают выполнением процессов в режиме задачи и информируют главный процессор о всех производимых обращениях к системным функциям. Выбор процессора, на котором будет выполняться данный процесс, производится в соответствии с алгоритмом диспетчеризации (Рисунок 12.3). В соответствующей записи таблицы процессов появляется новое поле, в которое записывается идентификатор выбранного процессора; предположим для простоты, что он показывает, является ли процессор главным или подчиненным. Когда процесс производит обращение к системной функции, выполняясь на подчиненном процессоре, подчиненное ядро переустанавливает значение поля идентификации процессора таким образом, чтобы оно указывало на главный процессор, и переключает контекст на другие процессы (Рисунок 12.4). Главное ядро запускает на выполнение процесс с наивысшим приоритетом среди тех процессов, которые должны выполняться на главном процессоре. Когда выполнение системной функции завершается, поле идентификации процессора перенастраивается обратно, и процесс вновь возвращается на подчиненный процессор. Если процессы должны выполняться на главном процессоре, желательно, чтобы главный процессор обрабатывал их как можно скорее и не заставлял их ждать своей очереди чересчур долго. Похожая мотивировка приводится в объяснение выгрузки процесса из памяти в однопроцессорной системе после выхода из системной функции с освобождением соответствующих ресурсов для выполнения более насущных счетных операций. Если в тот момент, когда подчиненный процессор делает запрос на исполнение системной функции, главный процесс выполняется в режиме задачи, его выполнение будет продолжаться до следующего переключения контекста. Главный процессор реагировал бы гораздо быстрее, если бы подчиненный процессор устанавливал при этом глобальный флаг; проверяя установку флага во время обработки очередного прерывания по таймеру, главный процессор произвел бы в итоге переключение контекста максимум через один таймерный тик. С другой стороны, подчиненный процессор мог бы прервать работу главного и заставить его переключить контекст немедленно, но данная возможность требует специальной аппаратной реализации. алгоритм schedule_process (модифицированный) входная информация: отсутствует выходная информация: отсутствует { do while (для запуска не будет выбран один из процессов) { if (работа ведется на главном процессоре) for (всех процессов в очереди готовых к выполнению) выбрать процесс, имеющий наивысший приоритет среди загруженных в память; else /* работа ведется на подчиненном процессоре */ for (тех процессов в очереди, которые не нуждаются в главном процессоре) выбрать процесс, имеющий наивысший приоритет среди загруженных в память; if (для запуска не подходит ни один из процессов) не загружать машину, переходящую в состояние простоя; /* из этого состояния машина выходит в результате прерывания */ } убрать выбранный процесс из очереди готовых к выполнению; переключиться на контекст выбранного процесса, возобновить его выполнение; } Рисунок 12.3. Алгоритм диспетчеризации алгоритм syscall /* исправленный алгоритм вызова системной функции */ входная информация: код системной функции выходная информация: результат выполнения системной функции { if (работа ведется на подчиненном процессоре) { переустановить значение поля идентификации процессора в соответствующей записи таблицы процессов; произвести переключение контекста; } выполнить обычный алгоритм реализации системной функции; перенастроить значение поля идентификации процессора, чтобы оно указывало на "любой" (подчиненный); if (на главном процессоре должны выполняться другие процессы) произвести переключение контекста; } Рисунок 12.4. Алгоритм обработки обращения к системной функции Программа обработки прерываний по таймеру на подчиненном процессоре следит за периодичностью перезапуска процессов, не допуская монопольного использования процессора одной задачей. Кроме того, каждую секунду эта программа выводит подчиненный процессор из состояния бездействия (простоя). Подчиненный процессор выбирает для выполнения процесс с наивысшим приоритетом среди тех процессов, которые не нуждаются в главном процессоре. Единственным местом, где целостность структур данных ядра еще подвергается опасности, является алгоритм диспетчеризации, поскольку он не предохраняет от выбора процесса на выполнение сразу на двух процессорах. Например, если в конфигурации имеется один главный процессор и два подчиненных, не исключена возможность того, что оба подчиненных процессора выберут для выполнения в режиме задачи один и тот же процесс. Если оба процессора начнут выполнять его параллельно, осуществляя чтение и запись, это неизбежно приведет к искажению содержимого адресного пространства процесса. Избежать возникновения этой проблемы можно двумя способами. Во-первых, главный процессор может явно указать, на каком из подчиненных процессоров следует выполнять данный процесс. Если на каждый процессор направлять несколько процессов, возникает необходимость в сбалансировании нагрузки (на один из процессоров назначается большое количество процессов, в то время как другие процессоры простаивают). Задача распределения нагрузки между процессорами ложится на главное ядро. Во-вторых, ядро может проследить за тем, чтобы в каждый момент времени в алгоритме диспетчеризации принимал участие только один процессор, для этого используются механизмы, подобные семафорам. 12.3 СЕМАФОРЫ Поддержка системы UNIX в многопроцессорной конфигурации может включать в себя разбиение ядра системы на критические участки, параллельное выполнение которых на нескольких процессорах не допускается. Такие системы предназначались для работы на машинах AT amp;T 3B20A и IBM 370, для разбиения ядра использовались семафоры (см. [Bach 84]). Нижеследующие рассуждения помогают понять суть данной особенности. При ближайшем рассмотрении сразу же возникают два вопроса: как использовать семафоры и где определить критические участки. Как уже говорилось в главе 2, если при выполнении критического участка программы процесс приостанавливается, для защиты участка от посягательств со стороны других процессов алгоритмы работы ядра однопроцессорной системы UNIX используют блокировку. Механизм установления блокировки: выполнять пока (блокировка установлена) /* операция проверки */ приостановиться (до снятия блокировки); установить блокировку; механизм снятия блокировки: снять блокировку; вывести из состояния приостанова все процессы, приостановленные в результате блокировки; 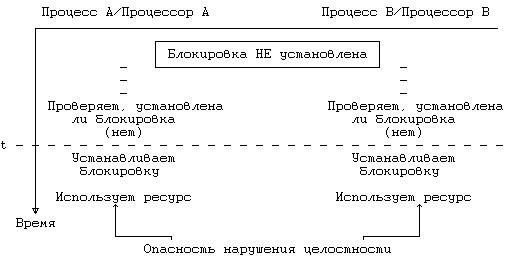 Рисунок 12.5. Конкуренция за установку блокировки в многопроцессорных системах Блокировки такого рода охватывают некоторые критические участки, но не работают в многопроцессорных системах, что видно из Рисунка 12.5. Предположим, что блокировка снята и что два процесса на разных процессорах одновременно пытаются проверить ее наличие и установить ее. В момент t они обнаруживают снятие блокировки, устанавливают ее вновь, вступают в критический участок и создают опасность нарушения целостности структур данных ядра. В условии одновременности имеется отклонение: механизм не сработает, если перед тем, как процесс выполняет операцию проверки, ни один другой процесс не выполнил операцию установления блокировки. Если, например, после обнаружения снятия блокировки процессор A обрабатывает прерывание и в этот момент процессор B выполняет проверку и устанавливает блокировку, по выходе из прерывания процессор A так же установит блокировку. Чтобы предотвратить возникновение подобной ситуации, нужно сделать так, чтобы процедура блокирования была неделимой: проверку наличия блокировки и ее установку следует объединить в одну операцию, чтобы в каждый момент времени с блокировкой имел дело только один процесс. 12.3.1 Определение семафоров Семафор представляет собой обрабатываемый ядром целочисленный объект, для которого определены следующие элементарные (неделимые) операции: • Инициализация семафора, в результате которой семафору присваивается неотрицательное значение; • Операция типа P, уменьшающая значение семафора. Если значение семафора опускается ниже нулевой отметки, выполняющий операцию процесс приостанавливает свою работу; • Операция типа V, увеличивающая значение семафора. Если значение семафора в результате операции становится больше или равно 0, один из процессов, приостановленных во время выполнения операции P, выходит из состояния приостанова; • Условная операция типа P, сокращенно CP (conditional P), уменьшающая значение семафора и возвращающая логическое значение "истина" в том случае, когда значение семафора остается положительным. Если в результате операции значение семафора должно стать отрицательным или нулевым, никаких действий над ним не производится и операция возвращает логическое значение "ложь". Определенные таким образом семафоры, безусловно, никак не связаны с семафорами пользовательского уровня, рассмотренными в главе 11. 12.3.2 Реализация семафоров Дийкстра [Dijkstra 65] показал, что семафоры можно реализовать без использования специальных машинных инструкций. На Рисунке 12.6 представлены реализующие семафоры функции, написанные на языке Си. Функция Pprim блокирует семафор по результатам проверки значений, содержащихся в массиве val; каждый процессор в системе управляет значением одного элемента массива. Прежде чем заблокировать семафор, процессор проверяет, не заблокирован ли уже семафор другими процессорами (соответствующие им элементы в массиве val тогда имеют значения, равные 2), а также не предпринимаются ли попытки в данный момент заблокировать семафор со стороны процессоров с более низким кодом идентификации (соответствующие им элементы имеют значения, равные 1). Если любое из условий выполняется, процессор переустанавливает значение своего элемента в 1 и повторяет попытку. Когда функция Pprim открывает внешний цикл, переменная цикла имеет значение, на единицу превышающее код идентификации того процессора, который использовал ресурс последним, тем самым гарантируется, что ни один из процессоров не может монопольно завладеть ресурсом (в качестве доказательства сошлемся на [Dijkstra 65] и [Coffman 73]). Функция Vprim освобождает семафор и открывает для других процессоров возможность получения исключительного доступа к ресурсу путем очистки соответствующего текущему процессору элемента в массиве val и перенастройки значения lastid. Чтобы защитить ресурс, следует выполнить следующий набор команд: Pprim(семафор); команды использования ресурса; Vprim(семафор); В большинстве машин имеется набор элементарных (неделимых) инструкций, реализующих операцию блокирования более дешевыми средствами, ибо циклы, входящие в функцию Pprim, работают медленно и снижают производительность системы. Так, например, в машинах серии IBM 370 поддерживается инструкция compare and swap (сравнить и переставить), в машине AT amp;T 3B20 — инструкция read and clear (прочитать и очистить). При выполнении инструкции read and clear процессор считывает содержимое ячейки памяти, очищает ее (сбрасывает в 0) и по результатам сравнения первоначального содержимого с 0 устанавливает код завершения инструкции. Если ту же инструкцию над той же ячейкой параллельно выполняет еще один процессор, один из двух процессоров прочитает первоначальное содержимое, а другой — 0: неделимость операции гарантируется аппаратным путем. Таким образом, за счет использования данной инструкции функцию Pprim можно было бы реализовать менее сложными средствами (Рисунок 12.7). Процесс повторяет инструкцию read and clear в цикле до тех пор, пока не будет считано значение, отличное от нуля. Начальное значение компоненты семафора, связанной с блокировкой, должно быть равно 1. Как таковую, данную семафорную конструкцию нельзя реализовать в составе ядра операционной системы, поскольку работающий с ней процесс не выходит из цикла, пока не достигнет своей цели. Если семафор используется для блокирования структуры данных, процесс, обнаружив семафор заблокированным, приостанавливает свое выполнение, чтобы ядро имело возможность переключиться на контекст другого процесса и выполнить другую полезную работу. С помощью функций Pprim и Vprim можно реализовать более сложный набор семафорных операций, соответствующий тому составу, который определен в разделе 12.3.1. struct semaphore { int val[NUMPROCS]; /* замок 1 элемент на каждый процессор */ int lastid; /* идентификатор процессора, получившего семафор последним */ }; int procid; /* уникальный идентификатор процессора */ int lastid; /* идентификатор процессора, получившего семафор последним */ INIT(semaphore) struct semaphore semaphore; { int i; for (i = 0; i ‹ NUMPROCS; i++) semaphore.val[i] = 0; } Pprim(semaphore) struct semaphore semaphore; { int i, first; loop: first = lastid; semaphore.val[procid] = 1; forloop: for (i = first; i ‹ NUMPROCS; i++) { if (i == procid) { semaphore.val[i] = 2; for (i = 1; i ‹ NUMPROCS; i++) if (i != procid && semaphore.val[i] == 2) goto loop; lastid = procid; return; /* успешное завершение, ресурс можно использовать */ } else if (semaphore.val[i]) goto loop; } first = 1; goto forloop; } Vprim(semaphore) struct semaphore semaphore; { lastid = (procid + 1) % NUMPROCS; /* на следующий процессор */ semaphore.val[procid] = 0; } Рисунок 12.6. Реализация семафорной блокировки на Си Для начала дадим определение семафора как структуры, состоящей из поля блокировки (управляющего доступом к семафору), значения семафора и очереди процессов, приостановленных по семафору. Поле блокировки содержит информацию, открывающую во время выполнения операций типа P и V доступ к другим полям структуры только одному процессу. По завершении операции значение поля сбрасывается. Это значение определяет, разрешен ли процессу доступ к критическому участку, защищаемому семафором. В начале выполнения алгоритма операции P (Рисунок 12.8) ядро с помощью функции Pprim предоставляет процессу право исключительного доступа к семафору и уменьшает значение семафора. Если семафор имеет неотрицательное значение, текущий процесс получает доступ к критическому участку. По завершении работы процесс сбрасывает блокировку семафора (с помощью функции Vprim), открывая доступ к семафору для других процессов, и возвращает признак успешного завершения. Если же в результате уменьшения значение семафора становится отрицательным, ядро приостанавливает выполнение процесса, используя алгоритм, подобный алгоритму sleep (глава 6): основываясь на значении приоритета, ядро проверяет поступившие сигналы, включает текущий процесс в список приостановленных процессов, в котором последние представлены в порядке поступления, и выполняет переключение контекста. Операция V (Рисунок 12.9) получает исключительный доступ к семафору через функцию Pprim и увеличивает значение семафора. Если очередь приостановленных по семафору процессов непуста, ядро выбирает из нее первый процесс и переводит его в состояние "готовности к запуску". Операции P и V по своему действию похожи на функции sleep и wakeup. Главное различие между ними состоит в том, что семафор является структурой данных, тогда как используемый функциями sleep и wakeup адрес представляет собой всего лишь число. Если начальное значение семафора — нулевое, при выполнении операции P над семафором процесс всегда приостанавливается, поэтому операция P может заменять функцию sleep. Операция V, тем не менее, выводит из состояния приостанова только один процесс, тогда как однопроцессорная функция wakeup возобновляет все процессы, приостановленные по адресу, связанному с событием. С точки зрения семантики использование функции wakeup означает: данное системное условие более не удовлетворяется, следовательно, все приостановленные по условию процессы должны выйти из состояния приостанова. Так, например, процессы, приостановленные в связи с занятостью буфера, не должны дальше пребывать в этом состоянии, если буфер больше не используется, поэтому они возобновляются ядром. Еще один пример: если несколько процессов выводят данные на терминал с помощью функции write, терминальный драйвер может перевести их в состояние приостанова в связи с невозможностью обработки больших объемов информации. Позже, когда драйвер будет готов к приему следующей порции данных, он возобновит все приостановленные им процессы. Использование операций P и V в тех случаях, когда устанавливающие блокировку процессы получают доступ к ресурсу поочередно, а все остальные процессы — в порядке поступления запросов, является более предпочтительным. В сравнении с однопроцессорной процедурой блокирования (sleep-lock) данная схема обычно выигрывает, так как если при наступлении события все процессы возобновляются, большинство из них может вновь наткнуться на блокировку и снова перейти в состояние приостанова. С другой стороны, в тех случаях, когда требуется вывести из состояния приостанова все процессы одновременно, использование операций P и V представляет известную сложность. struct semaphore { int lock; }; Init(semaphore) struct semaphore semaphore; { semaphore.lock = 1; } Pprim(semaphore) struct semaphore semaphore; { while (read_and_clear(semaphore.lock)); } Vprim(semaphore) struct semaphore semaphore; { semaphore.lock = 1; } Рисунок 12.7. Операции над семафором, использующие инструкцию read_and_clear Если операция возвращает значение семафора, является ли она эквивалентной функции wakeup? while (value(semaphore) ‹ 0) V(semaphore); Если вмешательства со стороны других процессов нет, ядро повторяет цикл до тех пор, пока значение семафора не станет больше или равно 0, ибо это означает, что в состоянии приостанова по семафору нет больше ни одного процесса. Тем не менее, нельзя исключить и такую возможность, что сразу после того, как процесс A при тестировании семафора на одноименном процессоре обнаружил нулевое значение семафора, процесс B на своем процессоре выполняет операцию P, уменьшая значение семафора до -1 (Рисунок 12.10). Процесс A продолжит свое выполнение, думая, что им возобновлены все приостановленные по семафору процессы. Таким образом, цикл выполнения операции не дает гарантии возобновления всех приостановленных процессов, поскольку он не является элементарным. алгоритм P /* операция над семафором типа P */ входная информация: (1) семафор (2) приоритет выходная информация: 0 — в случае нормального завершения -1 — в случае аварийного выхода из состояния приостанова по сигналу, принятому в режиме ядра { Pprim(semaphore.lock); уменьшить (semaphore.value); if (semaphore.value ›= 0) { Vprim(semaphore.lock); return (0); } /* следует перейти в состояние приостанова */ if (проверяются сигналы) { if (имеется сигнал, прерывающий нахождение в состоянии приостанова) { увеличить (semaphore.value); if (сигнал принят в режиме ядра) { Vprim(semaphore.lock); return(-1); } else { Vprim(semaphore.lock); longjmp; } } } поставить процесс в конец списка приостановленных по семафору; Vprim(semaphore.lock); выполнить переключение контекста; проверить сигналы (см. выше); return(0); } Рисунок 12.8. Алгоритм выполнения операции P Рассмотрим еще один феномен, связанный с использованием семафоров в однопроцессорной системе. Предположим, что два процесса, A и B, конкурируют за семафор. Процесс A обнаруживает, что семафор свободен и что процесс B приостановлен; значение семафора равно -1. Когда с помощью операции V процесс A освобождает семафор, он выводит тем самым процесс B из состояния приостанова и вновь делает значение семафора нулевым. Теперь предположим, что процесс A, по-прежнему выполняясь в режиме ядра, пытается снова заблокировать семафор. Производя операцию P, процесс приостановится, поскольку семафор имеет нулевое значение, несмотря на то, что ресурс пока свободен. Системе придется "раскошелиться" на дополнительное переключение контекста. С другой стороны, если бы блокировка была реализована на основе однопроцессорной схемы (sleep-lock), процесс A получил бы право на повторное использование ресурса, поскольку за это время ни один из процессов не смог бы заблокировать его. Для этого случая схема sleep-lock более подходит, чем схема с использованием семафоров. алгоритм V /* операция над семафором типа V */ входная информация: адрес семафора выходная информация: отсутствует { Pprim(semaphore.lock); увеличить (semaphore.value); if (semaphore.value ‹= 0) { удалить из списка процессов, приостановленных по семафору, первый по счету процесс; перевести его в состояние готовности к запуску; } Vprim(semaphore.lock); } Рисунок 12.9. Алгоритм выполнения операции V Когда блокируются сразу несколько семафоров, очередность блокирования должна исключать возникновение тупиковых ситуаций. В качестве примера рассмотрим два семафора, A и B, и два алгоритма, требующих одновременной блокировки семафоров. Если бы алгоритмы устанавливали блокировку на семафоры в обратном порядке, как следует из Рисунка 12.11, последовало бы возникновение тупиковой ситуации; процесс A на одноименном процессоре захватывает семафор SA, в то время как процесс B на своем процессоре захватывает семафор SB. Процесс A пытается захватить и семафор SB, но в результате операции P переходит в состояние приостанова, поскольку значение семафора SB не превышает 0. То же самое происходит с процессом B, когда последний пытается захватить семафор SA. Ни тот, ни другой процессы продолжаться уже не могут. Для предотвращения возникновения подобных ситуаций используются соответствующие алгоритмы обнаружения опасности взаимной блокировки, устанавливающие наличие опасной ситуации и ликвидирующие ее. Тем не менее, использование таких алгоритмов "утяжеляет" ядро. Поскольку число ситуаций, в которых процесс должен одновременно захватывать несколько семафоров, довольно ограничено, легче было бы реализовать алгоритмы, предупреждающие возникновение тупиковых ситуаций еще до того, как они будут иметь место. Если, к примеру, какой-то набор семафоров всегда блокируется в одном и том же порядке, тупиковая ситуация никогда не возникнет. Но в том случае, когда захвата семафоров в обратном порядке избежать не удается, операция CP предотвратит возникновение тупиковой ситуации (см. Рисунок 12.12): если операция завершится неудачно, процесс B освободит свои ресурсы, дабы избежать взаимной блокировки, и позже запустит алгоритм на выполнение повторно, скорее всего тогда, когда процесс A завершит работу с ресурсом. Чтобы предупредить одновременное обращение процессов к ресурсу, программа обработки прерываний, казалось бы, могла воспользоваться семафором, но из-за того, что она не может приостанавливать свою работу (см. главу 6), использовать операцию P в этой программе нельзя. Вместо этого можно использовать "циклическую блокировку" (spin lock) и не переходить в состояние приостанова, как в следующем примере: 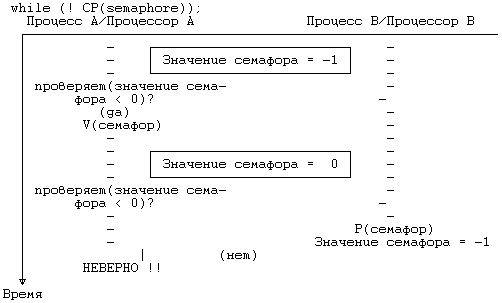 Рисунок 12.10. Неудачное имитация функции wakeup при использовании операции V  Рисунок 12.11. Возникновение тупиковой ситуации из-за смены очередности блокирования  Рисунок 12.12. Использование операции P условного типа для предотвращения взаимной блокировки Операция повторяется в цикле до тех пор, пока значение семафора не превысит 0; программа обработки прерываний не приостанавливается и цикл завершается только тогда, когда значение семафора станет положительным, после чего это значение будет уменьшено операцией CP. Чтобы предотвратить ситуацию взаимной блокировки, ядру нужно запретить все прерывания, выполняющие "циклическую блокировку". Иначе выполнение процесса, захватившего семафор, будет прервано еще до того, как он сможет освободить семафор; если программа обработки прерываний попытается захватить этот семафор, используя "циклическую блокировку", ядро заблокирует само себя. В качестве примера обратимся к Рисунку 12.13. В момент возникновения прерывания значение семафора не превышает 0, поэтому результатом выполнения операции CP всегда будет "ложь". Проблема решается путем запрещения всех прерываний на то время, пока семафор захвачен процессом.  Рисунок 12.13. Взаимная блокировка при выполнении программы обработки прерывания 12.3.3 Примеры алгоритмовВ данном разделе мы рассмотрим четыре алгоритма ядра, реализованных с использованием семафоров. Алгоритм выделения буфера иллюстрирует сложную схему блокирования, на примере алгоритма wait показана синхронизация выполнения процессов, схема блокирования драйверов реализует изящный подход к решению данной проблемы, и наконец, метод решения проблемы холостой работы процессора показывает, что нужно сделать, чтобы избежать конкуренции между процессами. 12.3.3.1 Выделение буфераОбратимся еще раз к алгоритму getblk, рассмотренному нами в главе 3. Алгоритм работает с тремя структурами данных: заголовком буфера, хеш-очередью буферов и списком свободных буферов. Ядро связывает семафор со всеми экземплярами каждой структуры. Другими словами, если у ядра имеются в распоряжении 200 буферов, заголовок каждого из них включает в себя семафор, используемый для захвата буфера; когда процесс выполняет над семафором операцию P, другие процессы, тоже пожелавшие захватить буфер, приостанавливаются до тех пор, пока первый процесс не исполнит операцию V. У каждой хеш-очереди буферов также имеется семафор, блокирующий доступ к очереди. В однопроцессорной системе блокировка хеш-очереди не нужна, ибо процесс никогда не переходит в состояние приостанова, оставляя очередь в несогласованном (неупорядоченном) виде. В многопроцессорной системе, тем не менее, возможны ситуации, когда с одной и той же хеш-очередью работают два процесса; в каждый момент времени семафор открывает доступ к очереди только для одного процесса. По тем же причинам и список свободных буферов нуждается в семафоре для защиты содержащейся в нем информации от искажения. алгоритм getblk /* многопроцессорная версия */ входная информация: номер файловой системы номер блока выходная информация: захваченный буфер, предназначенный для обработки содержимого блока { do while(буфер не будет обнаружен) { P(семафор хеш-очереди); if (блок находится в хеш-очереди) { if (операция CP(семафор буфера) завершается неудачно) { /* буфер занят */ V(семафор хеш-очереди); P(семафор буфера); /* приостанов до момента освобождения */ if (операция CP(семафор хеш-очереди) завершается неудачно) { V(семафор буфера); continue; /* выход в цикл "выполнять" */ } else if (номер устройства или номер блока изменились) { V(семафор буфера); V(семафор хеш-очереди); } } do while(операция CP(семафор списка свободных буферов) не завершится успешно); /* "кольцевой цикл" */ пометить буфер занятым; убрать буфер из списка свободных буферов; V(семафор списка свободных буферов); V(семафор хеш-очереди); return буфер; } else /* буфер отсутствует в хеш-очереди здесь начинается выполнение оставшейся части алгоритма */ } } Рисунок 12.14. Выделение буфера с использованием семафоров На Рисунке 12.14 показана первая часть алгоритма getblk, реализованная в многопроцессорной системе с использованием семафоров. Просматривая буферный кеш в поисках указанного блока, ядро с помощью операции P захватывает семафор, принадлежащий хеш-очереди. Если над семафором уже кем-то произведена операция данного типа, текущий процесс приостанавливается до тех пор, пока процесс, захвативший семафор, не освободит его, выполнив операцию V. Когда текущий процесс получает право исключительного контроля над хеш-очередью, он приступает к поиску подходящего буфера. Предположим, что буфер находится в хеш-очереди. Ядро (процесс A) пытается захватить буфер, но если оно использует операцию P и если буфер уже захвачен, ядру придется приостановить свою работу, оставив хеш-очередь заблокированной и не допуская таким образом обращений к ней со стороны других процессов, даже если последние ведут поиск незахваченных буферов. Пусть вместо этого процесс A захватывает буфер, используя операцию CP; если операция завершается успешно, буфер становится открытым для процесса. Процесс A захватывает семафор, принадлежащий списку свободных буферов, выполняя операцию CP, поскольку семафор захватывается на непродолжительное время и, следовательно, приостанавливать свою работу, выполняя операцию P, процесс просто не имеет возможности. Ядро убирает буфер из списка свободных буферов, снимает блокировку со списка и с хеш-очереди и возвращает захваченный буфер. Предположим, что операция CP над буфером завершилась неудачно из-за того, что семафор, принадлежащий буферу, оказался захваченным. Процесс A освобождает семафор, связанный с хеш-очередью, и приостанавливается, пытаясь выполнить операцию P над семафором буфера. Операция P над семафором будет выполняться, несмотря на то, что операция CP уже потерпела неудачу. По завершении выполнения операции процесс A получает власть над буфером. Так как в оставшейся части алгоритма предполагается, что буфер и хеш-очередь захвачены, процесс A теперь пытается захватить хеш-очередь[34]. Поскольку очередность захвата здесь (сначала семафор буфера, потом семафор очереди) обратна вышеуказанной очередности, над семафором выполняется операция CP. Если попытка захвата заканчивается неудачей, имеет место обычная обработка, требующаяся по ходу задачи. Но если захват удается, ядро не может быть уверено в том, что захвачен корректный буфер, поскольку содержимое буфера могло быть ранее изменено другим процессом, обнаружившим буфер в списке свободных буферов и захватившим на время его семафор. Процесс A, ожидая освобождения семафора, не имеет ни малейшего представления о том, является ли интересующий его буфер тем буфером, который ему нужен, и поэтому прежде всего он должен убедиться в правильности содержимого буфера; если проверка дает отрицательный результат, алгоритм запускается сначала. Если содержимое буфера корректно, процесс A завершает выполнение алгоритма. Оставшуюся часть алгоритма можно рассмотреть в качестве упражнения. 12.3.3.2 Waitмногопроцессорная версия алгоритма wait { для (;;) { /* цикл */ перебор всех процессов-потомков: if (потомок находится в состоянии "прекращения существования") return ; P(zombie_semaphore); /* начальное значение — 0 */ } } Рисунок 12.15. Многопроцессорная версия алгоритма wait Из главы 7 мы уже знаем о том, что во время выполнения системной функции wait процесс приостанавливает свою работу до момента завершения выполнения своего потомка. В многопроцессорной системе перед процессом встает задача не упустить при выполнении алгоритма wait потомка, прекратившего существование с помощью функции exit; если, например, в то время, пока на одном процессоре процесс-родитель запускает функцию wait, на другом процессоре его потомок завершил свою работу, родителю нет необходимости приостанавливать свое выполнение в ожидании завершения второго потомка. В каждой записи таблицы процессов имеется семафор, именуемый zombie_semaphore и имеющий в начале нулевое значение. Этот семафор используется при организации взаимодействия wait/exit (Рисунок 12.15). Когда потомок завершает работу, он выполняет над семафором своего родителя операцию V, выводя родителя из состояния приостанова, если тот перешел в него во время исполнения функции wait. Если потомок завершился раньше, чем родитель запустил функцию wait, этот факт будет обнаружен родителем, который тут же выйдет из состояния ожидания. Если оба процесса исполняют функции exit и wait параллельно, но потомок исполняет функцию exit уже после того, как родитель проверил его статус, операция V, выполненная потомком, воспрепятствует переходу родителя в состояние приостанова. В худшем случае процесс-родитель просто повторяет цикл лишний раз. 12.3.3.3 ДрайверыВ многопроцессорной реализации вычислительной системы на базе компьютеров AT&T 3B20 семафоры в структуру загрузочного кода драйверов не включаются, а операции типа P и V выполняются в точках входа в каждый драйвер (см. [Bach 84]). В главе 10 мы говорили о том, что интерфейс, реализуемый драйверами устройств, характеризуется очень небольшим числом точек входа (на практике их около 20). Защита драйверов осуществляется на уровне точек входа в них: P(семафор драйвера); открыть (драйвер); V(семафор драйвера); Если для всех точек входа в драйвер использовать один и тот же семафор, но при этом для разных драйверов — разные семафоры, критический участок программы драйвера будет исполняться процессом монопольно. Семафоры могут назначаться как отдельному устройству, так и классам устройств. Так, например, отдельный семафор может быть связан и с отдельным физическим терминалом и со всеми терминалами сразу. В первом случае быстродействие системы выше, ибо процессы, обращающиеся к терминалу, не захватывают семафор, имеющий отношение к другим терминалам, как во втором случае. Драйверы некоторых устройств, однако, поддерживают внутреннюю связь с другими драйверами; в таких случаях использование одного семафора для класса устройств облегчает понимание задачи. В качестве альтернативы в вычислительной системе 3B20A предоставлена возможность такого конфигурирования отдельных устройств, при котором программы драйвера запускаются на точно указанных процессорах. Проблемы возникают тогда, когда драйвер прерывает работу системы и его семафор захвачен: программа обработки прерываний не может быть вызвана, так как иначе возникла бы угроза разрушения данных. С другой стороны, ядро не может оставить прерывание необработанным. Система 3B20A выстраивает прерывания в очередь и ждет момента освобождения семафора, когда вызов программы обработки прерываний не будет иметь опасные последствия. 12.3.3.4 Фиктивные процессыКогда ядро выполняет переключение контекста в однопроцессорной системе, оно функционирует в контексте процесса, уступающего управление (см. главу 6). Если в системе нет процессов, готовых к запуску, ядро переходит в состояние простоя в контексте процесса, выполнявшегося последним. Получив прерывание от таймера или других периферийных устройств, оно обрабатывает его в контексте того же процесса. В многопроцессорной системе ядро не может простаивать в контексте процесса, выполнявшегося последним. Посмотрим, что произойдет после того, как процесс, приостановивший свою работу на процессоре A, выйдет из состояния приостанова. Процесс в целом готов к запуску, но он запускается не сразу же по выходе из состояния приостанова, даже несмотря на то, что его контекст уже находится в распоряжении процессора A. Если этот процесс выбирается для запуска процессором B, последний переключается на его контекст и возобновляет его выполнение. Когда в результате прерывания процессор A выйдет из простоя, он будет продолжать свою работу в контексте процесса A до тех пор, пока не произведет переключение контекста. Таким образом, в течение короткого промежутка времени с одним и тем же адресным пространством (в частности, со стеком ядра) будут вести работу (и, что весьма вероятно, производить запись) сразу два процессора. Решение этой проблемы состоит в создании некоторого фиктивного процесса; когда процессор находится в состоянии простоя, ядро переключается на контекст фиктивного процесса, делая этот контекст текущим для бездействующего процессора. Контекст фиктивного процесса состоит только из стека ядра; этот процесс не является выполнимым и не выбирается для запуска. Поскольку каждый процессор простаивает в контексте своего собственного фиктивного процесса, навредить друг другу процессоры уже не могут. 12.4 СИСТЕМА TUNISПользовательский интерфейс системы Tunis совместим с аналогичным интерфейсом системы UNIX, но ядро этой системы, разработанное на языке Concurrent Euclid, состоит из процессов, управляющих каждой частью системы. Проблема взаимного исключения решается в системе Tunis довольно просто, так как в каждый момент времени исполняется не более одной копии управляемого ядром процесса, кроме того, процессы работают только с теми структурами данных, которые им принадлежат. Системные процессы активизируются запросами на ввод, защиту очереди запросов осуществляет процедура программного монитора. Эта процедура усиливает взаимное исключение, разрешая доступ к своей исполняемой части в каждый момент времени не более, чем одному процессу. Механизм монитора отличается от механизма семафоров тем, что, во-первых, благодаря последним усиливается модульность программ (операции P и V присутствуют на входе в процедуру монитора и на выходе из нее), а во-вторых, сгенерированный компилятором код уже содержит элементы синхронизации. Холт отмечает, что разработка таких систем облегчается, если используется язык, поддерживающий мониторы и включающий понятие параллелизма (см. [Holt 83], стр.190). При всем при этом внутренняя структура системы Tunis отличается от традиционной реализации системы UNIX радикальным образом. 12.5 УЗКИЕ МЕСТА В ФУНКЦИОНИРОВАНИИ МНОГОПРОЦЕССОРНЫХ СИСТЕМ В данной главе нами были рассмотрены два метода реализации многопроцессорных версий системы UNIX: конфигурация, состоящая из главного и подчиненного процессоров, в которой только один процессор (главный) функционирует в режиме ядра, и метод, основанный на использовании семафоров и допускающий одновременное исполнение в режиме ядра всех имеющихся в системе процессов. Оба метода инвариантны к количеству процессоров, однако говорить о том, что с ростом числа процессоров общая производительность системы увеличивается с линейной скоростью, нельзя. Потери производительности возникают, во-первых, как следствие конкуренции за ресурсы памяти, которая выражается в увеличении продолжительности обращения к памяти. Во-вторых, в схеме, основанной на использовании семафоров, к этой конкуренции добавляется соперничество за семафоры; процессы зачастую обнаруживают семафоры захваченными, больше процессов находится в очереди, долгое время ожидая получения доступа к семафорам. Первая схема, основанная на использовании главного и подчиненного процессоров, тоже не лишена недостатков: по мере увеличения числа процессоров главный процессор становится узким местом в системе, поскольку только он один может функционировать в режиме ядра. Несмотря на то, что более внимательное техническое проектирование позволяет сократить конкуренцию до разумного минимума и в некоторых случаях приблизить скорость повышения производительности системы при увеличении числа процессоров к линейной (см., например, [Beck 85]), все построенные с использованием современной технологии многопроцессорные системы имеют предел, за которым расширение состава процессоров не сопровождается увеличением производительности системы. 12.6 УПРАЖНЕНИЯ 1. Решите проблему функционирования многопроцессорных систем таким образом, чтобы все процессоры в системе могли функционировать в режиме ядра, но не более одного одновременно. Такое решение будет отличаться от первой из предложенных в тексте схем, где только один процессор (главный) предназначен для реализации функций ядра. Как добиться того, чтобы в режиме ядра в каждый момент времени находился только один процессор? Какую стратегию обработки прерываний при этом можно считать приемлемой? 2. Используя системные функции работы с разделяемой областью памяти, протестируйте программу, реализующую семафорную блокировку (Рисунок 12.6). Последовательности операций P-V над семафором могут независимо один от другого выполнять несколько процессов. Каким образом в программе следует реализовать индикацию и обработку ошибок? 3. Разработайте алгоритм выполнения операции CP (условный тип операции P), используя текст алгоритма операции P. 4. Объясните, зачем в алгоритмах операций P и V (Рисунки 12.8 и 12.9) нужна блокировка прерываний. В какие моменты ее следует осуществлять? 5. Почему при выполнении "циклической блокировки" вместо строки: while (! CP(семафор)); ядро не может использовать операцию P безусловного типа? (В качестве наводящего вопроса: что произойдет в том случае, если процесс запустит операцию P и приостановится?) 6. Обратимся к алгоритму getblk, приведенному в главе 3. Опишите реализацию алгоритма в многопроцессорной системе для случая, когда блок отсутствует в буферном кеше. *7. Предположим, что при выполнении алгоритма выделения буфера возникла чрезвычайно сильная конкуренция за семафор, принадлежащий списку свободных буферов. Разработайте схему ослабления конкуренции за счет разбиения списка свободных буферов на два подсписка. *8. Предположим, что у терминального драйвера имеется семафор, значение которого при инициализации сбрасывается в 0 и по которому процессы приостанавливают свою работу в случае переполнения буфера вывода на терминал. Когда терминал готов к приему следующей порции данных, он выводит из состояния ожидания все процессы, приостановленные по семафору. Разработайте схему возобновления процессов, использующую операции типа P и V. В случае необходимости введите дополнительные флаги и семафоры. Как должна вести себя схема в том случае, если процессы выводятся из состояния ожидания по прерыванию, но при этом текущий процессор не имеет возможности блокировать прерывания на других процессорах? *9. Если точки входа в драйвер защищаются семафорами, должно соблюдаться условие освобождения семафора в случае перехода процесса в состояние приостанова. Как это реализуется на практике? Каким образом должна производиться обработка прерываний, поступающих в то время, пока семафор драйвера заблокирован? 10. Обратимся к системным функциям установки и контроля системного времени (глава 8). Разные процессоры могут иметь различную тактовую частоту. Как в этом случае указанные функции должны работать? Примечания:3 В некоторых реализациях системы UNIX операционная система взаимодействует с собственной операционной системой, которая, в свою очередь, взаимодействует с аппаратурой и выполняет необходимые функции по обслуживанию системы. В таких реализациях допускается инсталляция других операционных систем с загрузкой под их управлением прикладных программ параллельно с системой UNIX. Классическим примером подобной реализации явилась система MERT [Lycklama 78a]. Более новым примером могут служить реализации для компьютеров серии IBM 370 [Felton 84] и UNIVAC 1100 [Bodenstab 84]. 34 Вместо захвата хеш-очереди в этом месте можно было бы установить соответствующий флаг, проверяемый далее перед выполнением операции V, но чтобы проиллюстрировать схему захвата семафоров в обратной последовательности, в изложении мы будем придерживаться ранее описанного варианта. |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||