|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
4.5 СУПЕРБЛОК 4.8 ДРУГИЕ ТИПЫ ФАЙЛОВ 4.9 ВЫВОДЫ ГЛАВА 4. ВНУТРЕННЕЕ ПРЕДСТАВЛЕНИЕ ФАЙЛОВКак уже было замечено в главе 2, каждый файл в системе UNIX имеет уникальный индекс. Индекс содержит информацию, необходимую любому процессу для того, чтобы обратиться к файлу, например, права собственности на файл, права доступа к файлу, размер файла и расположение данных файла в файловой системе. Процессы обращаются к файлам, используя четко определенный набор системных вызовов и идентифицируя файл строкой символов, выступающих в качестве составного имени файла. Каждое составное имя однозначно определяет файл, благодаря чему ядро системы преобразует это имя в индекс файла. Эта глава посвящена описанию внутренней структуры файлов в операционной системе UNIX, в следующей же главе рассматриваются обращения к операционной системе, связанные с обработкой файлов. Раздел 4.1 касается индекса и работы с ним ядра, раздел 4.2 — внутренней структуры обычных файлов и некоторых моментов, связанных с чтением и записью ядром информации файлов. В разделе 4.3 исследуется строение каталогов — структур данных, позволяющих ядру организовывать файловую систему в виде иерархии файлов, раздел 4.4 содержит алгоритм преобразования имен пользовательских файлов в индексы. В разделе 4.5 дается структура суперблока, а в разделах 4.6 и 4.7 представлены алгоритмы назначения файлам дисковых индексов и дисковых блоков. Наконец, в разделе 4.8 идет речь о других типах файлов в системе, а именно о каналах и файлах устройств. Алгоритмы, описанные в этой главе, уровнем выше по сравнению с алгоритмами управления буферным кешем, рассмотренными в предыдущей главе (Рисунок 4.1). Алгоритм iget возвращает последний из идентифицированных индексов с возможностью считывания его с диска, используя буферный кеш, а алгоритм iput освобождает индекс. Алгоритм bmap устанавливает параметры ядра, связанные с обращением к файлу. Алгоритм namei преобразует составное имя пользовательского файла в имя индекса, используя алгоритмы iget, iput и bmap. Алгоритмы alloc и free выделяют и освобождают дисковые блоки для файлов, алгоритмы ialloc и ifree назначают и освобождают для файлов индексы.
Рисунок 4.1. Алгоритмы файловой системы 4.1 ИНДЕКСЫ4.1.1 ОпределениеИндексы существуют на диске в статической форме и ядро считывает их в память прежде, чем начать с ними работать. Дисковые индексы включают в себя следующие поля: • Идентификатор владельца файла. Права собственности разделены между индивидуальным владельцем и «групповым» и тем самым помогают определить круг пользователей, имеющих права доступа к файлу. Суперпользователь имеет право доступа ко всем файлам в системе. • Тип файла. Файл может быть файлом обычного типа, каталогом, специальным файлом, соответствующим устройствам ввода-вывода символами или блоками, а также абстрактным файлом канала (организующим обслуживание запросов в порядке поступления, «первым пришел — первым вышел»). • Права доступа к файлу. Система разграничивает права доступа к файлу для трех классов пользователей: индивидуального владельца файла, группового владельца и прочих пользователей; каждому классу выделены определенные права на чтение, запись и исполнение файла, которые устанавливаются индивидуально. Поскольку каталоги как файлы не могут быть исполнены, разрешение на исполнение в данном случае интерпретируется как право производить поиск в каталоге по имени файла. • Календарные сведения, характеризующие работу с файлом: время внесения последних изменений в файл, время последнего обращения к файлу, время внесения последних изменений в индекс. • Число указателей на файл, означающее количество имен, используемых при поиске файла в иерархии каталогов. Указатели на файл подробно рассматриваются в главе 5. • Таблица адресов на диске, в которых располагается информация файла. Хотя пользователи трактуют информацию в файле как логический поток байтов, ядро располагает эти данные в несоприкасающихся дисковых блоках. Дисковые блоки, содержащие информацию файла, указываются в индексе. • Размер файла. Данные в файле адресуются с помощью смещения в байтах относительно начала файла, начиная со смещения, равного 0, поэтому размер файла в байтах на 1 больше максимального смещения. Например, если пользователь создает файл и записывает только 1 байт информации по адресу со смещением 1000 от начала файла, размер файла составит 1001 байт. В индексе отсутствует составное имя файла, необходимое для осуществления доступа к файлу.
Рисунок 4.2. Пример дискового индекса На Рисунке 4.2 показан дисковый индекс некоторого файла. Этот индекс принадлежит обычному файлу, владелец которого — «mjb» и размер которого 6030 байт. Система разрешает пользователю «mjb» производить чтение, запись и исполнение файла; членам группы «os» и всем остальным пользователям разрешается только читать или исполнять файл, но не записывать в него данные. Последний раз файл был прочитан 23 октября 1984 года в 13:45, запись последний раз производилась 22 октября 1984 года в 10:30. Индекс изменялся последний раз 23 октября 1984 года в 13:30, хотя никакая информация в это время в файл не записывалась. Ядро кодирует все вышеперечисленные данные в индексе. Обратите внимание на различие в записи на диск содержимого индекса и содержимого файла. Содержимое файла меняется только тогда, когда в файл производится запись. Содержимое индекса меняется как при изменении содержимого файла, так и при изменении владельца файла, прав доступа и набора указателей. Изменение содержимого файла автоматически вызывает коррекцию индекса, однако коррекция индекса еще не означает изменения содержимого файла. Копия индекса в памяти, кроме полей дискового индекса, включает в себя и следующие поля: • Состояние индекса в памяти, отражающее - заблокирован ли индекс, - ждет ли снятия блокировки с индекса какой-либо процесс, - отличается ли представление индекса в памяти от своей дисковой копии в результате изменения содержимого индекса, - отличается ли представление индекса в памяти от своей дисковой копии в результате изменения содержимого файла, - находится ли файл в верхней точке (см. раздел 5.15). • Логический номер устройства файловой системы, содержащей файл. • Номер индекса. Так как индексы на диске хранятся в линейном массиве (см. раздел 2.2.1), ядро идентифицирует номер дискового индекса по его местоположению в массиве. В дисковом индексе это поле не нужно. • Указатели на другие индексы в памяти. Ядро связывает индексы в хеш-очереди и включает их в список свободных индексов подобно тому, как связывает буферы в буферные хеш-очереди и включает их в список свободных буферов. Хеш-очередь идентифицируется в соответствии с логическим номером устройства и номером индекса. Ядро может располагать в памяти не более одной копии данного дискового индекса, но индексы могут находиться одновременно как в хеш-очереди, так и в списке свободных индексов. • Счетчик ссылок, означающий количество активных экземпляров файла (таких, которые открыты). Многие поля в копии индекса, с которой ядро работает в памяти, аналогичны полям в заголовке буфера, и управление индексами похоже на управление буферами. Индекс так же блокируется, в результате чего другим процессам запрещается работа с ним; эти процессы устанавливают в индексе специальный флаг, возвещающий о том, что выполнение обратившихся к индексу процессов следует возобновить, как только блокировка будет снята. Установкой других флагов ядро отмечает противоречия между дисковым индексом и его копией в памяти. Когда ядру нужно будет записать изменения в файл или индекс, ядро перепишет копию индекса из памяти на диск только после проверки этих флагов. Наиболее разительным различием между копией индекса в памяти и заголовком буфера является наличие счетчика ссылок, подсчитывающего количество активных экземпляров файла. Индекс активен, когда процесс выделяет его, например, при открытии файла. Индекс находится в списке свободных индексов, только если значение его счетчика ссылок равно 0, и это значит, что ядро может переназначить свободный индекс в памяти другому дисковому индексу. Таким образом, список свободных индексов выступает в роли кеша для неактивных индексов. Если процесс пытается обратиться к файлу, чей индекс в этот момент отсутствует в индексном пуле, ядро переназначает свободный индекс из списка для использования этим процессом. С другой стороны, у буфера нет счетчика ссылок; он находится в списке свободных буферов тогда и только тогда, когда он разблокирован. 4.1.2 Обращение к индексамЯдро идентифицирует индексы по имени файловой системы и номеру индекса и выделяет индексы в памяти по запросам соответствующих алгоритмов. Алгоритм iget назначает индексу место для копии в памяти (Рисунок 4.3); он почти идентичен алгоритму getblk для поиска дискового блока в буферном кеше. Ядро преобразует номера устройства и индекса в имя хеш-очереди и просматривает эту хеш-очередь в поисках индекса. Если индекс не обнаружен, ядро выделяет его из списка свободных индексов и блокирует его. Затем ядро готовится к чтению с диска в память индекса, к которому оно обращается. Ядро уже знает номера индекса и логического устройства и вычисляет номер логического блока на диске, содержащего индекс, с учетом того, сколько дисковых индексов помещается в одном дисковом блоке. Вычисления производятся по формуле номер блока = ((номер индекса — 1) / число индексов в блоке) + начальный блок в списке индексов где операция деления возвращает целую часть частного. Например, предположим, что блок 2 является начальным в списке индексов и что в каждом блоке помещаются 8 индексов, тогда индекс с номером 8 находится в блоке 2, а индекс с номером 9 — в блоке 3. Если же в дисковом блоке помещаются 16 индексов, тогда индексы с номерами 8 и 9 располагаются в дисковом блоке с номером 2, а индекс с номером 17 является первым индексом в дисковом блоке 3. алгоритм iget входная информация: номер индекса в файловой системе выходная информация: заблокированный индекс { do { if (индекс в индексном кеше) { if (индекс заблокирован) { sleep (до освобождения индекса); continue; /* цикл с условием продолжения */ } /* специальная обработка для точек монтирования (глава 5) */ if (индекс в списке свободных индексов) убрать из списка свободных индексов; увеличить счетчик ссылок для индекса; return (индекс); } /* индекс отсутствует в индексном кеше */ if (список свободных индексов пуст) return (ошибку); убрать новый индекс из списка свободных индексов; сбросить номер индекса и файловой системы; убрать индекс из старой хеш-очереди, поместить в новую; считать индекс с диска (алгоритм bread); инициализировать индекс (например, установив счетчик ссылок в 1); return(индекс); } } Рисунок 4.3. Алгоритм выделения индексов в памяти Если ядро знает номера устройства и дискового блока, оно читает блок, используя алгоритм bread (глава 2), затем вычисляет смещение индекса в байтах внутри блока по формуле: ((номер индекса – 1) mod (число индексов в блоке)) * размер дискового индекса Например, если каждый дисковый индекс занимает 64 байта и в блоке помещаются 8 индексов, тогда индекс с номером 8 имеет адрес со смещением 448 байт от начала дискового блока. Ядро убирает индекс в памяти из списка свободных индексов, помещает его в соответствующую хеш-очередь и устанавливает значение счетчика ссылок равным 1. Ядро переписывает поля типа файла и владельца файла, установки прав доступа, число указателей на файл, размер файла и таблицу адресов из дискового индекса в память и возвращает заблокированный в памяти индекс. Ядро манипулирует с блокировкой индекса и счетчиком ссылок независимо один от другого. Блокировка — это установка, которая действует на время выполнения системного вызова и имеет целью запретить другим процессам обращаться к индексу пока тот в работе (и возможно хранит противоречивые данные). Ядро снимает блокировку по окончании обработки системного вызова: блокировка индекса никогда не выходит за границы системного вызова. Ядро увеличивает значение счетчика ссылок с появлением каждой активной ссылки на файл. Например, в разделе 5.1 будет показано, как ядро увеличивает значение счетчика ссылок тогда, когда процесс открывает файл. Оно уменьшает значение счетчика ссылок только тогда, когда ссылка становится неактивной, например, когда процесс закрывает файл. Таким образом, установка счетчика ссылок сохраняется для множества системных вызовов. Блокировка снимается между двумя обращениями к операционной системе, чтобы позволить процессам одновременно производить разделенный доступ к файлу; установка счетчика ссылок действует между обращениями к операционной системе, чтобы предупредить переназначение ядром активного в памяти индекса. Таким образом, ядро может заблокировать и разблокировать выделенный индекс независимо от значения счетчика ссылок. Выделением и освобождением индексов занимаются и отличные от open системные операции, в чем мы и убедимся в главе 5. Возвращаясь к алгоритму iget, заметим, что если ядро пытается взять индекс из списка свободных индексов и обнаруживает список пустым, оно сообщает об ошибке. В этом отличие от идеологии, которой следует ядро при работе с дисковыми буферами, где процесс приостанавливает свое выполнение до тех пор, пока буфер не освободится. Процессы контролируют выделение индексов на пользовательском уровне посредством запуска системных операций open и close и поэтому ядро не может гарантировать момент, когда индекс станет доступным. Следовательно, процесс, приостанавливающий свое выполнение в ожидании освобождения индекса, может никогда не возобновиться. Ядро скорее прервет выполнение системного вызова, чем оставит такой процесс в «зависшем» состоянии. Однако, процессы не имеют такого контроля над буферами. Поскольку процесс не может удержать буфер заблокированным в течение выполнения нескольких системных операций, ядро здесь может гарантировать скорое освобождение буфера, и процесс поэтому приостанавливается до того момента, когда он станет доступным. В предшествующих параграфах рассматривался случай, когда ядро выделяет индекс, отсутствующий в индексном кеше. Если индекс находится в кеше, процесс (A) обнаружит его в хеш-очереди и проверит, не заблокирован ли индекс другим процессом (B). Если индекс заблокирован, процесс A приостанавливается и выставляет флаг у индекса в памяти, показывая, что он ждет освобождения индекса. Когда позднее процесс B разблокирует индекс, он «разбудит» все процессы (включая процесс A), ожидающие освобождения индекса. Когда же наконец процесс A сможет использовать индекс, он заблокирует его, чтобы другие процессы не могли к нему обратиться. Если первоначально счетчик ссылок имел значение, равное 0, индекс также появится в списке свободных индексов, поэтому ядро уберет его оттуда: индекс больше не является свободным. Ядро увеличивает значение счетчика ссылок и возвращает заблокированный индекс. Если суммировать все вышесказанное, можно отметить, что алгоритм iget имеет отношение к начальной стадии системных вызовов, когда процесс впервые обращается к файлу. Этот алгоритм возвращает заблокированную индексную структуру со значением счетчика ссылок, на 1 большим, чем оно было раньше. Индекс в памяти содержит текущую информацию о состоянии файла. Ядро снимает блокировку с индекса перед выходом из системной операции, поэтому другие системные вызовы могут обратиться к индексу, если пожелают. В главе 5 рассматриваются эти случаи более подробно. алгоритм iput /* разрешение доступа к индексу в памяти */ входная информация: указатель на индекс в памяти выходная информация: отсутствует { заблокировать индекс если он еще не заблокирован; уменьшить на 1 счетчик ссылок для индекса; if (значение счетчика ссылок == 0) { if (значение счетчика связей == 0) { освободить дисковые блоки для файла (алгоритм free, раздел 4.7); установить тип файла равным 0; освободить индекс (алгоритм ifree, раздел 4.6); } if (к файлу обращались или изменился индекс или изменилось содержимое файла) скорректировать дисковый индекс; поместить индекс в список свободных индексов; } снять блокировку с индекса; } Рисунок 4.4. Освобождение индекса 4.1.3 Освобождение индексовВ том случае, когда ядро освобождает индекс (алгоритм iput, Рисунок 4.4), оно уменьшает значение счетчика ссылок для него. Если это значение становится равным 0, ядро переписывает индекс на диск в том случае, когда копия индекса в памяти отличается от дискового индекса. Они различаются, если изменилось содержимое файла, если к файлу производилось обращение или если изменились владелец файла либо права доступа к файлу. Ядро помещает индекс в список свободных индексов, наиболее эффективно располагая индекс в кеше на случай, если он вскоре понадобится вновь. Ядро может также освободить все связанные с файлом информационные блоки и индекс, если число ссылок на файл равно 0. 4.2 СТРУКТУРА ФАЙЛА ОБЫЧНОГО ТИПАКак уже говорилось, индекс включает в себя таблицу адресов расположения информации файла на диске. Так как каждый блок на диске адресуется по своему номеру, в этой таблице хранится совокупность номеров дисковых блоков. Если бы данные файла занимали непрерывный участок на диске (то есть файл занимал бы линейную последовательность дисковых блоков), то для обращения к данным в файле было бы достаточно хранить в индексе адрес начального блока и размер файла. Однако, такая стратегия размещения данных не позволяет осуществлять простое расширение и сжатие файлов в файловой системе без риска фрагментации свободного пространства памяти на диске. Более того, ядру пришлось бы выделять и резервировать непрерывное пространство в файловой системе перед выполнением операций, могущих привести к увеличению размера файла. 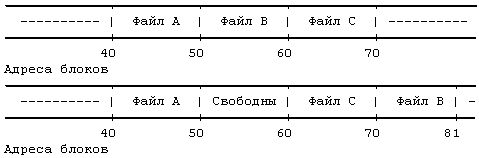 Рисунок 4.5. Размещение непрерывных файлов и фрагментация свободного пространства Предположим, например, что пользователь создает три файла, A, B и C, каждый из которых занимает 10 дисковых блоков, а также что система выделила для размещения этих трех файлов непрерывное место. Если потом пользователь захочет добавить 5 блоков с информацией к среднему файлу, B, ядру придется скопировать файл B в то место в файловой системе, где найдется окно размером 15 блоков. В дополнение к затратам ресурсов на проведение этой операции дисковые блоки, занимаемые информацией файла B, станут неиспользуемыми, если только они не понадобятся файлам размером не более 10 блоков (Рисунок 4.5). Ядро могло бы минимизировать фрагментацию пространства памяти, периодически запуская процедуры чистки памяти, уплотняющие имеющуюся память, но это потребовало бы дополнительного расхода временных и системных ресурсов. В целях повышения гибкости ядро присоединяет к файлу по одному блоку, позволяя информации файла быть разбросанной по всей файловой системе. Но такая схема размещения усложняет задачу поиска данных. Таблица адресов содержит список номеров блоков, содержащих принадлежащую файлу информацию, однако простые вычисления показывают, что линейным списком блоков файла в индексе трудно управлять. Если логический блок занимает 1 Кбайт, то файлу, состоящему из 10 Кбайт, потребовался бы индекс на 10 номеров блоков, а файлу, состоящему из 100 Кбайт, понадобился бы индекс на 100 номеров блоков. Либо пусть размер индекса будет варьироваться в зависимости от размера файла, либо пришлось бы установить относительно жесткое ограничение на размер файла. Для того, чтобы небольшая структура индекса позволяла работать с большими файлами, таблица адресов дисковых блоков приводится в соответствие со структурой, представленной на Рисунке 4.6. Версия V системы UNIX работает с 13 точками входа в таблицу адресов индекса, но принципиальные моменты не зависят от количества точек входа. Блок, имеющий пометку «прямая адресация» на рисунке, содержит номера дисковых блоков, в которых хранятся реальные данные. Блок, имеющий пометку «одинарная косвенная адресация», указывает на блок, содержащий список номеров блоков прямой адресации. Чтобы обратиться к данным с помощью блока косвенной адресации, ядро должно считать этот блок, найти соответствующий вход в блок прямой адресации и, считав блок прямой адресации, обнаружить данные. Блок, имеющий пометку «двойная косвенная адресация», содержит список номеров блоков одинарной косвенной адресации, а блок, имеющий пометку «тройная косвенная адресация», содержит список номеров блоков двойной косвенной адресации. В принципе, этот метод можно было бы распространить и на поддержку блоков четверной косвенной адресации, блоков пятерной косвенной адресации и так далее, но на практике оказывается достаточно имеющейся структуры. Предположим, что размер логического блока в файловой системе 1 Кбайт и что номер блока занимает 32 бита (4 байта). Тогда в блоке может храниться до 256 номеров блоков. Расчеты показывают (Рисунок 4.7), что максимальный размер файла превышает 16 Гбайт, если использовать в индексе 10 блоков прямой адресации и 1 одинарной косвенной адресации, 1 двойной косвенной адресации и 1 тройной косвенной адресации. Если же учесть, что длина поля «размер файла» в индексе — 32 бита, то размер файла в действительности ограничен 4 Гбайтами (2 в степени 32). Процессы обращаются к информации в файле, задавая смещение в байтах. Они рассматривают файл как поток байтов и ведут подсчет байтов, начиная с нулевого адреса и заканчивая адресом, равным размеру файла. Ядро переходит от байтов к блокам: файл начинается с нулевого логического блока и заканчивается блоком, номер которого определяется исходя из размера файла. Ядро обращается к индексу и превращает логический блок, принадлежащий файлу, в соответствующий дисковый блок. На Рисунке 4.8 представлен алгоритм bmap пересчета смещения в байтах от начала файла в номер физического блока на диске. 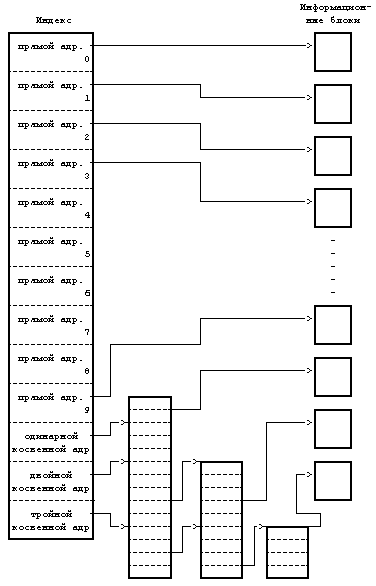 Рисунок 4.6. Блоки прямой и косвенной адресации в индексе 10 блоков прямой адресации по 1 Кбайту каждый = 10 Кбайт 1 блок косвенной адресации с 256 блоками прямой адресации = 256 Кбайт 1 блок двойной косвенной адресации с 256 блоками косвенной адресации = 64 Мбайта 1 блок тройной косвенной адресации с 256 блоками двойной косвенной адресации = 16 Гбайт Рисунок 4.7. Объем файла в байтах при размере блока 1 Кбайт алгоритм bmap /* отображение адреса смещения в байтах от начала логического файла на адрес блока в файловой системе */ входная информация: (1) индекс (2) смещение в байтах выходная информация: (1) номер блока в файловой системе (2) смещение в байтах внутри блока (3) число байт ввода-вывода в блок (4) номер блока с продвижением { вычислить номер логического блока в файле исходя из заданного смещения в байтах; вычислить номер начального байта в блоке для ввода-вывода; /* выходная информация 2 */ вычислить количество байт для копирования пользователю; /* выходная информация 3 */ проверить возможность чтения с продвижением, пометить индекс; /* выходная информация 4 */ определить уровень косвенности; do (пока уровень косвенности другой) { определить указатель в индексе или блок косвенной адресации исходя из номера логического блока в файле; получить номер дискового блока из индекса или из блока косвенной адресации; освободить буфер от данных, полученных в результате выполнения предыдущей операции чтения с диска (алгоритм brelse); if (число уровней косвенности исчерпано) return (номер блока); считать дисковый блок косвенной адресации (алгоритм bread); установить номер логического блока в файле исходя из уровня косвенности; } } Рисунок 4.8. Преобразование адреса смещения в номер блока в файловой системе Рассмотрим формат файла в блоках (Рисунок 4.9) и предположим, что дисковый блок занимает 1024 байта. Если процессу нужно обратиться к байту, имеющему смещение от начала файла, равное 9000, в результате вычислений ядро приходит к выводу, что этот байт располагается в блоке прямой адресации с номером 8 (начиная с 0). Затем ядро обращается к блоку с номером 367; 808-й байт в этом блоке (если вести отсчет с 0) и является 9000-м байтом в файле. Если процессу нужно обратиться по адресу, указанному смещением 350000 байт от начала файла, он должен считать блок двойной косвенной адресации, который на рисунке имеет номер 9156. Так как блок косвенной адресации имеет место для 256 номеров блоков, первым байтом, к которому будет получен доступ в результате обращения к блоку двойной косвенной адресации, будет байт с номером 272384 (256К + 10К); таким образом, байт с номером 350000 будет иметь в блоке двойной косвенной адресации номер 77616. Поскольку каждый блок одинарной косвенной адресации позволяет обращаться к 256 Кбайтам, байт с номером 350000 должен располагаться в нулевом блоке одинарной косвенной адресации для блока двойной косвенной адресации, а именно в блоке 331. Так как в каждом блоке прямой адресации для блока одинарной косвенной адресации хранится 1 Кбайт, байт с номером 77616 находится в 75-м блоке прямой адресации для блока одинарной косвенной адресации, а именно в блоке 3333. Наконец, байт с номером в файле 350000 имеет в блоке 3333 номер 816. 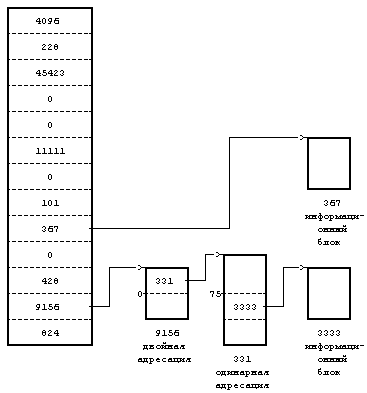 Рисунок 4.9. Размещение блоков в файле и его индексе При ближайшем рассмотрении Рисунка 4.9 обнаруживается, что несколько входов для блока в индексе имеют значение 0 и это значит, что в данных записях информация о логических блоках отсутствует. Такое имеет место, если в соответствующие блоки файла никогда не записывалась информация и по этой причине у номеров блоков остались их первоначальные нулевые значения. Для таких блоков пространство на диске не выделяется. Подобное расположение блоков в файле вызывается процессами, запускающими системные операции lseek и write (см. следующую главу). В следующей главе также объясняется, каким образом ядро обрабатывает системные вызовы операции read, с помощью которой производится обращение к блокам. Преобразование адресов с большими смещениями, в частности с использованием блоков тройной косвенной адресации, является сложной процедурой, требующей от ядра обращения уже к трем дисковым блокам в дополнение к индексу и информационному блоку. Даже если ядро обнаружит блоки в буферном кеше, операция останется дорогостоящей, так как ядру придется многократно обращаться к буферному кешу и приостанавливать свою работу в ожидании снятия блокировки с буферов. Насколько эффективен этот алгоритм на практике? Это зависит от того, как используется система, а также от того, кто является пользователем и каков состав задач, вызывающий потребность в более частом обращении к большим или, наоборот, маленьким файлам. Однако, как уже было замечено [Mullender 84], большинство файлов в системе UNIX имеет размер, не превышающий 10 Кбайт и даже 1 Кбайта![11] Поскольку 10 Кбайт файла располагаются в блоках прямой адресации, к большей части данных, хранящихся в файлах, доступ может производиться за одно обращение к диску. Поэтому в отличие от обращения к большим файлам, работа с файлами стандартного размера протекает быстро. В двух модификациях только что описанной структуры индекса предпринимается попытка использовать размерные характеристики файла. Основной принцип в реализации файловой системы BSD 4.2 [McKusick 84] состоит в том, что чем больше объем данных, к которым ядро может получить доступ за одно обращение к диску, тем быстрее протекает работа с файлом. Это свидетельствует в пользу увеличения размера логического блока на диске, поэтому в системе BSD разрешается иметь логические блоки размером 4 или 8 Кбайт. Однако, увеличение размера блоков на диске приводит к увеличению фрагментации блоков, при которой значительные участки дискового пространства остаются неиспользуемыми. Например, если размер логического блока 8 Кбайт, тогда файл размером 12 Кбайт занимает 1 полный блок и половину второго блока. Другая половина второго блока (4 Кбайта) фактически теряется; другие файлы не могут использовать ее для хранения данных. Если размеры файлов таковы, что число байт, попавших в последний блок, является равномерно распределенной величиной, то средние потери дискового пространства составляют полблока на каждый файл; объем теряемого дискового пространства достигает в файловой системе с логическими блоками размером 4 Кбайта 45% [McKusick 84]. Выход из этой ситуации в системе BSD состоит в выделении только части блока (фрагмента) для размещения оставшейся информации файла. Один дисковый блок может включать в себя фрагменты, принадлежащие нескольким файлам. Некоторые подробности этой реализации исследуются на примере упражнения в главе 5. Второй модификацией рассмотренной классической структуры индекса является идея хранения в индексе информации файла (см. [Mullender 84]). Если увеличить размер индекса так, чтобы индекс занимал весь дисковый блок, небольшая часть блока может быть использована для собственно индексных структур, а оставшаяся часть — для хранения конца файла и даже во многих случаях для хранения файла целиком. Основное преимущество такого подхода заключается в том, что необходимо только одно обращение к диску для считывания индекса и всей информации, если файл помещается в индексном блоке. 4.3 КАТАЛОГИИз главы 1 напомним, что каталоги являются файлами, из которых строится иерархическая структура файловой системы; они играют важную роль в превращении имени файла в номер индекса. Каталог — это файл, содержимым которого является набор записей, состоящих из номера индекса и имени файла, включенного в каталог. Составное имя — это строка символов, завершающаяся пустым символом и разделяемая наклонной чертой («/») на несколько компонент. Каждая компонента, кроме последней, должна быть именем каталога, но последняя компонента может быть именем файла, не являющегося каталогом. В версии V системы UNIX длина каждой компоненты ограничивается 14 символами; таким образом, вместе с 2 байтами, отводимыми на номер индекса, размер записи каталога составляет 16 байт. Смещение в байтах внутри каталога Номер индекса (2 байта) Имя файла
Рисунок 4.10. Формат каталога /etc На Рисунке 4.10 показан формат каталога «etc». В каждом каталоге имеются файлы, в качестве имен которых указаны точка и две точки ("." и «..») и номера индексов у которых совпадают с номерами индексов данного каталога и родительского каталога, соответственно. Номер индекса для файла "." в каталоге «/etc» имеет адрес со смещением 0 и значение 83. Номер индекса для файла «..» имеет адрес со смещением 16 от начала каталога и значение 2. Записи в каталоге могут быть пустыми, при этом номер индекса равен 0. Например, запись с адресом 224 в каталоге «/etc» пустая, несмотря на то, что она когда-то содержала точку входа для файла с именем «crash». Программа mkfs инициализирует файловую систему таким образом, что номера индексов для файлов "." и «..» в корневом каталоге совпадают с номером корневого индекса файловой системы. Ядро хранит данные в каталоге так же, как оно это делает в файле обычного типа, используя индексную структуру и блоки с уровнями прямой и косвенной адресации. Процессы могут читать данные из каталогов таким же образом, как они читают обычные файлы, однако исключительное право записи в каталог резервируется ядром, благодаря чему обеспечивается правильность структуры каталога. Права доступа к каталогу имеют следующий смысл: право чтения дает процессам возможность читать данные из каталога; право записи позволяет процессу создавать новые записи в каталоге или удалять старые (с помощью системных операций creat, mknod, link и unlink), в результате чего изменяется содержимое каталога; право исполнения позволяет процессу производить поиск в каталоге по имени файла (поскольку «исполнять» каталог бессмысленно). На примере Упражнения 4.6 показана разница между чтением и поиском в каталоге. 4.4 ПРЕВРАЩЕНИЕ СОСТАВНОГО ИМЕНИ ФАЙЛА (ПУТИ ПОИСКА) В ИДЕНТИФИКАТОР ИНДЕКСАНачальное обращение к файлу производится по его составному имени (имени пути поиска), как в командах open, chdir (изменить каталог) или link. Поскольку внутри системы ядро работает с индексами, а не с именами путей поиска, оно преобразует имена путей поиска в идентификаторы индексов, чтобы производить доступ к файлам. Алгоритм namei производит поэлементный анализ составного имени, ставя в соответствие каждой компоненте имени индекс и каталог и в конце концов возвращая идентификатор индекса для введенного имени пути поиска (Рисунок 4.11). Из главы 2 напомним, что каждый процесс связан с текущим каталогом (и протекает в его рамках); рабочая область, отведенная под задачу пользователя, содержит указатель на индекс текущего каталога. Текущим каталогом первого из процессов в системе, нулевого процесса, является корневой каталог. Путь к текущему каталогу каждого нового процесса берет начало от текущего каталога процесса, являющегося родительским по отношению к данному (см. раздел 5.10). Процессы изменяют текущий каталог, запрашивая выполнение системной операции chdir (изменить каталог). Все поиски файлов по имени начинаются с текущего каталога процесса, если только имя пути поиска не предваряется наклонной чертой, указывая, что поиск нужно начинать с корневого каталога. В любом случае ядро может легко обнаружить индекс каталога, с которого начинается поиск. Текущий каталог хранится в рабочей области процесса, а корневой индекс системы хранится в глобальной переменной[12]. алгоритм namei /* превращение имени пути поиска в индекс */ входная информация: имя пути поиска выходная информация: заблокированный индекс { if (путь поиска берет начало с корня) рабочий индекс = индексу корня (алгоритм iget); else индекс = индексу текущего каталога (алгоритм iget); выполнить (пока путь поиска не кончился) { считать следующую компоненту имени пути поиска; проверить соответствие рабочего индекса каталогу и права доступа; if (рабочий индекс соответствует корню и компонента имени «..») continue; /* цикл с условием продолжения */ считать каталог (рабочий индекс), повторяя алгоритмы bmap, bread и brelse; if (компонента соответствует записи в каталоге (рабочем индексе)) { получить номер индекса для совпавшей компоненты; освободить рабочий индекс (алгоритм iput); рабочий индекс = индексу совпавшей компоненты (алгоритм iget); } else /* компонента отсутствует в каталоге */ return (нет индекса); } return (рабочий индекс); } Рисунок 4.11. Алгоритм превращения имени пути поиска в индекс Алгоритм namei использует при анализе составного имени пути поиска промежуточные индексы; назовем их рабочими индексами. Индекс каталога, откуда поиск берет начало, является первым рабочим индексом. На каждой итерации цикла алгоритма ядро проверяет совпадение рабочего индекса с индексом каталога. В противном случае, нарушилось бы утверждение, что только файлы, не являющиеся каталогами, могут быть листьями дерева файловой системы. Процесс также должен иметь право производить поиск в каталоге (разрешения на чтение недостаточно). Код идентификации пользователя для процесса должен соответствовать коду индивидуального или группового владельца файла и должно быть предоставлено право исполнения, либо поиск нужно разрешить всем пользователям. В противном случае, поиск не получится. Ядро выполняет линейный поиск файла в каталоге, ассоциированном с рабочим индексом, пытаясь найти для компоненты имени пути поиска подходящую запись в каталоге. Исходя из адреса смещения в байтах внутри каталога (начиная с 0), оно определяет местоположение дискового блока в соответствии с алгоритмом bmap и считывает этот блок, используя алгоритм bread. По имени компоненты ядро производит в блоке поиск, представляя содержимое блока как последовательность записей каталога. При обнаружении совпадения ядро переписывает номер индекса из данной точки входа, освобождает блок (алгоритм brelse) и старый рабочий индекс (алгоритм iput), и переназначает индекс найденной компоненты (алгоритм iget). Новый индекс становится рабочим индексом. Если ядро не находит в блоке подходящего имени, оно освобождает блок, прибавляет к адресу смещения число байтов в блоке, превращает новый адрес смещения в номер дискового блока (алгоритм bmap) и читает следующий блок. Ядро повторяет эту процедуру до тех пор, пока имя компоненты пути поиска не совпадет с именем точки входа в каталоге, либо до тех пор, пока не будет достигнут конец каталога. Предположим, например, что процессу нужно открыть файл «/etc/passwd». Когда ядро начинает анализировать имя файла, оно наталкивается на наклонную черту («/») и получает индекс корня системы. Сделав корень текущим рабочим индексом, ядро наталкивается на строку «etc». Проверив соответствие текущего индекса каталогу («/») и наличие у процесса права производить поиск в каталоге, ядро ищет в корневом каталоге файл с именем «etc». Оно просматривает корневой каталог блок за блоком и исследует каждую запись в блоке, пока не обнаружит точку входа для файла «etc». Найдя эту точку входа, ядро освобождает индекс, отведенный для корня (алгоритм iput), и выделяет индекс файлу «etc» (алгоритм iget) в соответствии с номером индекса в обнаруженной записи. Удостоверившись в том, что «etc» является каталогом, а также в том, что имеются необходимые права производить поиск, ядро просматривает каталог «etc» блок за блоком в поисках записи, соответствующей файлу «passwd». Если посмотреть на Рисунок 4.10, можно увидеть, что запись о файле «passwd» является девятой записью в каталоге. Обнаружив ее, ядро освобождает индекс, выделенный файлу «etc», и выделяет индекс файлу «passwd», после чего — поскольку имя пути поиска исчерпано — возвращает этот индекс процессу. Естественно задать вопрос об эффективности линейного поиска в каталоге записи, соответствующей компоненте имени пути поиска. Ричи показывает (см. [Ritchie 78b], стр.1968), что линейный поиск эффективен, поскольку он ограничен размером каталога. Более того, ранние версии системы UNIX не работали еще на машинах с большим объемом памяти, поэтому значительный упор был сделан на простые алгоритмы, такие как алгоритмы линейного поиска. Более сложные схемы поиска потребовали бы отличной, более сложной, структуры каталога, и возможно работали бы медленнее даже в небольших каталогах по сравнению со схемой линейного поиска. 4.5 СУПЕРБЛОК До сих пор в этой главе описывалась структура файла, при этом предполагалось, что индекс предварительно связывался с файлом и что уже были определены дисковые блоки, содержащие информацию. В следующих разделах описывается, каким образом ядро назначает индексы и дисковые блоки. Чтобы понять эти алгоритмы, рассмотрим структуру суперблока. Суперблок состоит из следующих полей: • размер файловой системы, • количество свободных блоков в файловой системе, • список свободных блоков, имеющихся в файловой системе, • индекс следующего свободного блока в списке свободных блоков, • размер списка индексов, • количество свободных индексов в файловой системе, • список свободных индексов в файловой системе, • следующий свободный индекс в списке свободных индексов, • заблокированные поля для списка свободных блоков и свободных индексов, • флаг, показывающий, что в суперблок были внесены изменения. В оставшейся части главы будет объяснено, как пользоваться массивами, указателями и замками блокировки. Ядро периодически переписывает суперблок на диск, если в суперблок были внесены изменения, для того, чтобы обеспечивалась согласованность с данными, хранящимися в файловой системе. 4.6 НАЗНАЧЕНИЕ ИНДЕКСА НОВОМУ ФАЙЛУДля выделения известного индекса, то есть индекса, для которого предварительно определен собственный номер (и номер файловой системы), ядро использует алгоритм iget. В алгоритме namei, например, ядро определяет номер индекса, устанавливая соответствие между компонентой имени пути поиска и именем в каталоге. Другой алгоритм, ialloc, выполняет назначение дискового индекса вновь создаваемому файлу. Как уже говорилось в главе 2, в файловой системе имеется линейный список индексов. Индекс считается свободным, если поле его типа хранит нулевое значение. Если процессу понадобился новый индекс, ядро теоретически могло бы произвести поиск свободного индекса в списке индексов. Однако, такой поиск обошелся бы дорого, поскольку потребовал бы по меньшей мере одну операцию чтения (допустим, с диска) на каждый индекс. Для повышения производительности в суперблоке файловой системы хранится массив номеров свободных индексов в файловой системе. алгоритм ialloc /* выделение индекса */ входная информация: файловая система выходная информация: заблокированный индекс { do { if (суперблок заблокирован) { sleep (пока суперблок не освободится); continue; /* цикл с условием продолжения */ } if (список индексов в суперблоке пуст) { заблокировать суперблок; выбрать запомненный индекс для поиска свободных индексов; искать на диске свободные индексы до тех пор, пока суперблок не заполнится или пока не будут найдены все свободные индексы (алгоритмы bread и brelse); снять блокировку с суперблока; возобновить выполнение процесса (как только суперблок освободится); if (на диске отсутствуют свободные индексы) return (нет индексов); запомнить индекс с наибольшим номером среди найденных для последующих поисков свободных индексов; } /* список индексов в суперблоке не пуст */ выбрать номер индекса из списка индексов в суперблоке; получить индекс (алгоритм iget); if (индекс после всего этого не свободен) { /*!!! */ переписать индекс на диск; освободить индекс (алгоритм iput); continue; /* цикл с условием продолжения */ } /* индекс свободен */ инициализировать индекс; переписать индекс на диск; уменьшить счетчик свободных индексов в файловой системе; return (индекс); } } Рисунок 4.12. Алгоритм назначения новых индексов На Рисунке 4.12 приведен алгоритм ialloc назначения новых индексов. По причинам, о которых пойдет речь ниже, ядро сначала проверяет, не заблокировал ли какой-либо процесс своим обращением список свободных индексов в суперблоке. Если список номеров индексов в суперблоке не пуст, ядро назначает номер следующего индекса, выделяет для вновь назначенного дискового индекса свободный индекс в памяти, используя алгоритм iget (читая индекс с диска, если необходимо), копирует дисковый индекс в память, инициализирует поля в индексе и возвращает индекс заблокированным. Затем ядро корректирует дисковый индекс, указывая, что к индексу произошло обращение. Ненулевое значение поля типа файла говорит о том, что дисковый индекс назначен. В простейшем случае с индексом все в порядке, но в условиях конкуренции делается необходимым проведение дополнительных проверок, на чем мы еще кратко остановимся. Грубо говоря, конкуренция возникает, когда несколько процессов вносят изменения в общие информационные структуры, так что результат зависит от очередности выполнения процессов, пусть даже все процессы будут подчиняться протоколу блокировки. Здесь предполагается, например, что процесс мог бы получить уже используемый индекс. Конкуренция связана с проблемой взаимного исключения, описанной в главе 2, с одним замечанием: различные схемы блокировки решают проблему взаимного исключения, но не могут сами по себе решить все проблемы конкуренции. Если список свободных индексов в суперблоке пуст, ядро просматривает диск и помещает в суперблок как можно больше номеров свободных индексов. При этом ядро блок за блоком считывает индексы с диска и наполняет список номеров индексов в суперблоке до отказа, запоминая индекс с номером, наибольшим среди найденных. Назовем этот индекс «запомненным»; это последний индекс, записанный в суперблок. В следующий раз, когда ядро будет искать на диске свободные индексы, оно использует запомненный индекс в качестве стартовой точки, благодаря чему гарантируется, что ядру не придется зря тратить время на считывание дисковых блоков, в которых свободные индексы наверняка отсутствуют. После формирования нового набора номеров свободных индексов ядро запускает алгоритм назначения индекса с самого начала. Всякий раз, когда ядро назначает дисковый индекс, оно уменьшает значение счетчика свободных индексов, записанное в суперблоке. Рассмотрим две пары массивов номеров свободных индексов (Рисунок 4.13). Если список свободных индексов в суперблоке имеет вид первого массива на Рисунке 4.13(а) при назначении индекса ядром, то значение указателя на следующий номер индекса уменьшается до 18 и выбирается индекс с номером 48. Если же список выглядит как первый массив на Рисунке 4.13(б), ядро заметит, что массив пуст и обратится в поисках свободных индексов к диску, при этом поиск будет производиться, начиная с индекса с номером 470, который был ранее запомнен. Когда ядро заполнит список свободных индексов в суперблоке до отказа, оно запомнит последний индекс в качестве начальной точки для последующих просмотров диска. Ядро производит назначение файлу только что выбранного с диска индекса (под номером 471 на рисунке) и продолжает прерванную обработку. 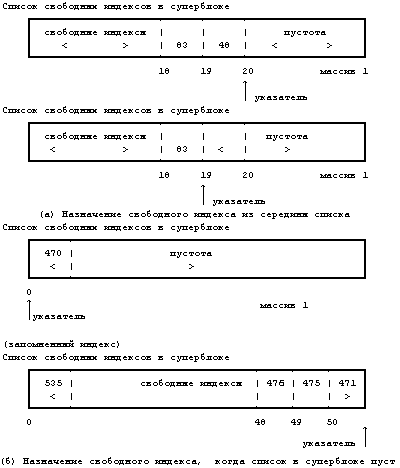 Рисунок 4.13. Два массива номеров свободных индексов алгоритм ifree /* освобождение индекса */ входная информация: номер индекса в файловой системе выходная информация: отсутствует { увеличить на 1 счетчик свободных индексов в файловой системе; if (суперблок заблокирован) return; if (список индексов заполнен) { if (номер индекса меньше номера индекса, запомненного для последующего просмотра) запомнить для последующего просмотра номер введенного индекса; } в противном случае сохранить номер индекса в списке индексов; return; } Рисунок 4.14. Алгоритм освобождения индекса Алгоритм освобождения индекса построен значительно проще. Увеличив на единицу общее количество доступных в файловой системе индексов, ядро проверяет наличие блокировки у суперблока. Если он заблокирован, ядро, чтобы предотвратить конкуренцию, немедленно сообщает: номер индекса отсутствует в суперблоке, но индекс может быть найден на диске и доступен для переназначения. Если список не заблокирован, ядро проверяет, имеется ли место для новых номеров индексов и если да, помещает номер индекса в список и выходит из алгоритма. Если список полон, ядро не сможет в нем сохранить вновь освобожденный индекс. Оно сравнивает номер освобожденного индекса с номером запомненного индекса. Если номер освобожденного индекса меньше номера запомненного, ядро запоминает номер вновь освобожденного индекса, выбрасывая из суперблока номер старого запомненного индекса. Индекс не теряется, поскольку ядро может найти его, просматривая список индексов на диске. Ядро поддерживает структуру списка в суперблоке таким образом, что последний номер, выбираемый им из списка, и есть номер запомненного индекса. В идеале не должно быть свободных индексов с номерами, меньшими, чем номер запомненного индекса, но возможны и исключения. Рассмотрим два примера освобождения индексов. Если в списке свободных индексов в суперблоке еще есть место для новых номеров свободных индексов (как на Рисунке 4.13(а)), ядро помещает в список новый номер, переставляет указатель на следующий свободный индекс и продолжает выполнение процесса. Но если список свободных индексов заполнен (Рисунок 4.15), ядро сравнивает номер освобожденного индекса с номером запомненного индекса, с которого начнется просмотр диска в следующий раз. Если вначале список свободных индексов имел вид, как на Рисунке 4.15(а), то когда ядро освобождает индекс с номером 499, оно запоминает его и выталкивает номер 535 из списка. Если затем ядро освобождает индекс с номером 601, содержимое списка свободных индексов не изменится. Когда позднее ядро использует все индексы из списка свободных индексов в суперблоке, оно обратится в поисках свободных индексов к диску, при этом, начав просмотр с индекса с номером 499, оно снова обнаружит индексы 535 и 601. 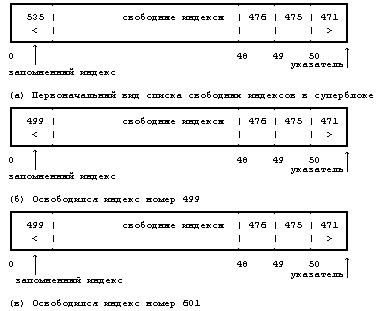 Рисунок 4.15. Размещение номеров свободных индексов в суперблоке  Рисунок 4.16. Конкуренция в назначении индексов В предыдущем параграфе описывались простые случаи работы алгоритмов. Теперь рассмотрим случай, когда ядро назначает новый индекс и затем копирует его в память. В алгоритме предполагается, что ядро может и обнаружить, что индекс уже назначен. Несмотря на редкость такой ситуации, обсудим этот случай (с помощью Рисунков 4.16 и 4.17). Пусть у нас есть три процесса, A, B и C, и пусть ядро, действуя от имени процесса A[13], назначает индекс I, но приостанавливает выполнение процесса перед тем, как скопировать дисковый индекс в память. Алгоритмы iget (вызванный алгоритмом ialloc) и bread (вызванный алгоритмом iget) дают процессу A достаточно возможностей для приостановления своей работы. Предположим, что пока процесс A приостановлен, процесс B пытается назначить новый индекс, но обнаруживает, что список свободных индексов в суперблоке пуст. Процесс B просматривает диск в поисках свободных индексов, и начинает это делать с индекса, имеющего меньший номер по сравнению с индексом, назначенным процессом A. Возможно, что процесс B обнаружит индекс I на диске свободным, так как процесс A все еще приостановлен, а ядро еще не знает, что этот индекс собираются назначить. Процесс B, не осознавая опасности, заканчивает просмотр диска, заполняет суперблок свободными (предположительно) индексами, назначает индекс и уходит со сцены. Однако, индекс I остается в списке номеров свободных индексов в суперблоке. Когда процесс A возобновляет выполнение, он заканчивает назначение индекса I. Теперь допустим, что процесс C затем затребовал индекс и случайно выбрал индекс I из списка в суперблоке. Когда он обратится к копии индекса в памяти, он обнаружит из установки типа файла, что индекс уже назначен. Ядро проверяет это условие и, обнаружив, что этот индекс назначен, пытается назначить другой. Немедленная перепись скорректированного индекса на диск после его назначения в соответствии с алгоритмом ialloc снижает опасность конкуренции, поскольку поле типа файла будет содержать пометку о том, что индекс использован. 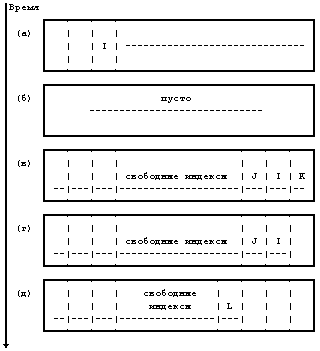 Рисунок 4.17. Конкуренция в назначении индексов (продолжение) Блокировка списка индексов в суперблоке при чтении с диска устраняет другие возможности для конкуренции. Если суперблок не заблокирован, процесс может обнаружить, что он пуст, и попытаться заполнить его с диска, время от времени приостанавливая свое выполнение до завершения операции ввода-вывода. Предположим, что второй процесс так же пытается назначить новый индекс и обнаруживает, что список пуст. Он тоже попытается заполнить список с диска. В лучшем случае, оба процесса продублируют друг друга и потратят энергию центрального процессора. В худшем, участится конкуренция, подобная той, которая описана в предыдущем параграфе. Сходным образом, если процесс, освобождая индекс, не проверил наличие блокировки списка, он может затереть номера индексов уже в списке свободных индексов, пока другой процесс будет заполнять этот список информацией с диска. И опять участится конкуренция вышеописанного типа. Несмотря на то, что ядро более или менее удачно управляется с ней, производительность системы снижается. Установка блокировки для списка свободных индексов в суперблоке устраняет такую конкуренцию. 4.7 ВЫДЕЛЕНИЕ ДИСКОВЫХ БЛОКОВКогда процесс записывает данные в файл, ядро должно выделять из файловой системы дисковые блоки под информационные блоки прямой адресации и иногда под блоки косвенной адресации. Суперблок файловой системы содержит массив, используемый для хранения номеров свободных дисковых блоков в файловой системе. Сервисная программа mkfs («make file system» — создать файловую систему) организует информационные блоки в файловой системе в виде списка с указателями так, что каждый элемент списка указывает на дисковый блок, в котором хранится массив номеров свободных дисковых блоков, а один из элементов массива хранит номер следующего блока данного списка. Когда ядру нужно выделить блок из файловой системы (алгоритм alloc, Рисунок 4.19), оно выделяет следующий из блоков, имеющихся в списке в суперблоке. Выделенный однажды, блок не может быть переназначен до тех пор, пока не освободится. Если выделенный блок является последним блоком, имеющимся в кеше суперблока, ядро трактует его как указатель на блок, в котором хранится список свободных блоков. Ядро читает блок, заполняет массив в суперблоке новым списком номеров блоков и после этого продолжает работу с первоначальным номером блока. Оно выделяет буфер для блока и очищает содержимое буфера (обнуляет его). Дисковый блок теперь считается назначенным и у ядра есть буфер для работы с ним. Если в файловой системе нет свободных блоков, вызывающий процесс получает сообщение об ошибке. Если процесс записывает в файл большой объем информации, он неоднократно запрашивает у системы блоки для хранения информации, но ядро назначает каждый раз только по одному блоку. Программа mkfs пытается организовать первоначальный связанный список номеров свободных блоков так, чтобы номера блоков, передаваемых файлу, были рядом друг с другом. Благодаря этому повышается производительность, поскольку сокращается время поиска на диске и время ожидания при последовательном чтении файла процессом. На Рисунке 4.18 номера блоков даны в настоящем формате, определяемом скоростью вращения диска. К сожалению, очередность номеров блоков в списке свободных блоков перепутана в связи с частыми обращениями к списку со стороны процессов, ведущих запись в файлы и удаляющих их, в результате чего номера блоков поступают в список и покидают его в случайном порядке. Ядро не предпринимает попыток сортировать номера блоков в списке. 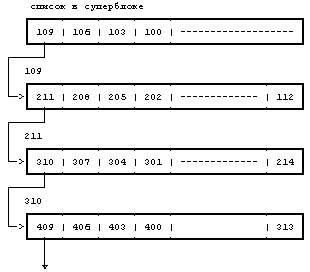 Рисунок 4.18. Список номеров свободных дисковых блоков с указателями Алгоритм освобождения блока free — обратный алгоритму выделения блока. Если список в суперблоке не полон, номер вновь освобожденного блока включается в этот список. Если, однако, список полон, вновь освобожденный блок становится связным блоком; ядро переписывает в него список из суперблока и копирует блок на диск. Затем номер вновь освобожденного блока включается в список свободных блоков в суперблоке. Этот номер становится единственным номером в списке. На Рисунке 4.20 показана последовательность операций alloc и free для случая, когда в исходный момент список свободных блоков содержал один элемент. Ядро освобождает блок 949 и включает номер блока в список. Затем оно выделяет этот блок и удаляет его номер из списка. Наконец, оно выделяет блок 109 и удаляет его номер из списка. Поскольку список свободных блоков в суперблоке теперь пуст, ядро снова наполняет список, копируя в него содержимое блока 109, являющегося следующей связью в списке с указателями. На Рисунке 4.20(г) показан заполненный список в суперблоке и следующий связной блок с номером 211. алгоритм alloc /* выделение блока файловой системы */ входная информация: номер файловой системы выходная информация: буфер для нового блока { do (пока суперблок заблокирован) sleep (до того момента, когда с суперблока будет снята блокировка); удалить блок из списка свободных блоков в суперблоке; if (из списка удален последний блок) { заблокировать суперблок; прочитать блок, только что взятый из списка свободных (алгоритм bread); скопировать номера блоков, хранящиеся в данном блоке, в суперблок; освободить блочный буфер (алгоритм brelse); снять блокировку с суперблока; возобновить выполнение процессов (после снятия блокировки с суперблока); } получить буфер для блока, удаленного из списка (алгоритм getblk); обнулить содержимое буфера; уменьшить общее число свободных блоков; пометить суперблок как «измененный»; return буфер; } Рисунок 4.19. Алгоритм выделения дискового блока Алгоритмы назначения и освобождения индексов и дисковых блоков сходятся в том, что ядро использует суперблок в качестве кеша, хранящего указатели на свободные ресурсы — номера блоков и номера индексов. Оно поддерживает список номеров блоков с указателями, такой, что каждый номер свободного блока в файловой системе появляется в некотором элементе списка, но ядро не поддерживает такого списка для свободных индексов. Тому есть три причины. Ядро устанавливает, свободен ли индекс или нет, проверяя: если поле типа файла очищено, индекс свободен. Ядро не нуждается в другом механизме описания свободных индексов. Тем не менее, оно не может определить, свободен ли блок или нет, только взглянув на него. Ядро не может уловить различия между маской, показывающей, что блок свободен, и информацией, случайно имеющей сходную маску. Следовательно, ядро нуждается во внешнем механизме идентификации свободных блоков, в качестве него в традиционных реализациях системы используется список с указателями. Сама конструкция дисковых блоков наводит на мысль об использовании списков с указателями: в дисковом блоке легко разместить большие списки номеров свободных блоков. Но индексы не имеют подходящего места для массового хранения списков номеров свободных индексов. Пользователи имеют склонность чаще расходовать дисковые блоки, нежели индексы, поэтому кажущееся запаздывание в работе при просмотре диска в поисках свободных индексов не является таким критическим, как если бы оно имело место при поисках свободных дисковых блоков. 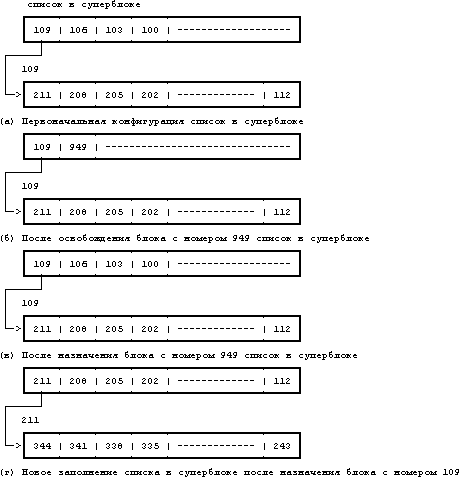 Рисунок 4.20. Запрашивание и освобождение дисковых блоков 4.8 ДРУГИЕ ТИПЫ ФАЙЛОВ В системе UNIX поддерживаются и два других типа файлов: каналы и специальные файлы. Канал, иногда называемый fifo (сокращенно от «first-in-first-out» — «первым пришел — первым вышел» — поскольку обслуживает запросы в порядке поступления), отличается от обычного файла тем, что содержит временные данные: информация, однажды считанная из канала, не может быть прочитана вновь. Кроме того, информация читается в том порядке, в котором она была записана в канале, и система не допускает никаких отклонений от данного порядка. Способ хранения ядром информации в канале не отличается от способа ее хранения в обычном файле, за исключением того, что здесь используются только блоки прямой, а не косвенной, адресации. Конкретное представление о каналах можно будет получить в следующей главе. Последним типом файлов в системе UNIX являются специальные файлы, к которым относятся специальные файлы устройств ввода-вывода блоками и специальные файлы устройств посимвольного ввода-вывода. Оба подтипа обозначают устройства, и поэтому индексы таких файлов не связаны ни с какой информацией. Вместо этого индекс содержит два номера — старший и младший номера устройства. Старший номер устройства указывает его тип, например, терминал или диск, а младший номер устройства — числовой код, идентифицирующий устройство в группе однородных устройств. Более подробно специальные файлы устройств рассматриваются в главе 10. 4.9 ВЫВОДЫ Индекс представляет собой структуру данных, в которой описываются атрибуты файла, в том числе расположение информации файла на диске. Существует две разновидности индекса: копия на диске, в которой хранится информация индекса, пока файл находится в работе, и копия в памяти, где хранится информация об активных файлах. Алгоритмы ialloc и ifree управляют назначением файлу дискового индекса во время выполнения системных операций creat, mknod, pipe и unlink (см. следующую главу), а алгоритмы iget и iput управляют выделением индексов в памяти в момент обращения процесса к файлу. Алгоритм bmap определяет местонахождение дисковых блоков, принадлежащих файлу, используя предварительно заданное смещение в байтах от начала файла. Каталоги представляют собой файлы, которые устанавливают соответствие между компонентами имен файлов и номерами индексов. Алгоритм namei преобразует имена файлов, с которыми работают процессы, в идентификаторы индексов, с которыми работает ядро. Наконец, ядро управляет назначением файлу новых дисковых блоков, используя алгоритмы alloc и free. Структуры данных, рассмотренные в настоящей главе, состоят из связанных списков, хеш-очередей и линейных массивов, и поэтому алгоритмы, работающие с рассмотренными структурами данных, достаточно просты. Сложности появляются тогда, когда возникает конкуренция, вызываемая взаимодействием алгоритмов между собой, и некоторые из этих проблем синхронизации рассмотрены в тексте. Тем не менее, алгоритмы не настолько детально разработаны и могут служить иллюстрацией простоты конструкции системы. Вышеописанные структуры и алгоритмы работают внутри ядра и невидимы для пользователя. С точки зрения общей архитектуры системы (Рисунок 2.1), алгоритмы, рассмотренные в данной главе, имеют отношение к нижней половине подсистемы управления файлами. Следующая глава посвящена разбору обращений к операционной системе, обеспечивающих функционирование пользовательского интерфейса, и описанию верхней половины подсистемы управления файлами, из которой вызывается выполнение рассмотренных здесь алгоритмов. 4.10 УПРАЖНЕНИЯ1. В версии V системы UNIX разрешается использовать не более 14 символов на каждую компоненту имени пути поиска. Алгоритм namei отсекает лишние символы в компоненте. Что нужно сделать в файловой системе и в соответствующих алгоритмах, чтобы стали допустимыми имена компонент произвольной длины? 2. Предположим, что пользователь имеет закрытую версию системы UNIX, причем он внес в нее такие изменения, что имя компоненты теперь может состоять из 30 символов; закрытая версия системы обеспечивает тот же способ хранения записей каталогов, как и стандартная операционная система, за исключением того, что записи каталогов имеют длину 32 байта вместо 16. Если пользователь смонтирует закрытую файловую систему в стандартной операционной среде, что произойдет во время работы алгоритма namei, когда процесс обратится к файлу? *3. Рассмотрим работу алгоритма namei по преобразованию имени пути поиска в идентификатор индекса. В течение всего просмотра ядро проверяет соответствие текущего рабочего индекса индексу каталога. Может ли другой процесс удалить (unlink) каталог? Каким образом ядро предупреждает такие действия? В следующей главе мы вернемся к этой проблеме. *4. Разработайте структуру каталога, повышающую эффективность поиска имен файлов без использования линейного просмотра. Рассмотрите два способа: хеширование и n-арные деревья. *5. Разработайте алгоритм сокращения количества просмотров каталога в поисках имени файла, используя запоминание часто употребляемых имен. *6. В идеальном случае в файловой системе не должно быть свободных индексов с номерами, меньшими, чем номер «запомненного» индекса, используемый алгоритмом ialloc. Как случается, что это утверждение бывает ложным? 7. Суперблок является дисковым блоком и содержит кроме списка свободных блоков и другую информацию, как показано в данной главе. Поэтому список свободных блоков в суперблоке не может содержать больше номеров свободных блоков, чем может поместиться в одном дисковом блоке в связанном списке свободных дисковых блоков. Какое число номеров свободных блоков было бы оптимальным для хранения в одном блоке из связанного списка? Примечания:1 Организации, получившие права на перепродажу с надбавкой к цене за дополнительные услуги, оснащают вычислительную систему прикладными программами, касающимися конкретных областей применения, стремясь удовлетворить требования рынка. Такие организации чаще продают прикладные программы, нежели операционные системы, под управлением которых эти программы работают. 11 На примере 19978 файлов Маллендер и Танненбаум говорят, что приблизительно 85 % файлов имеют размер менее 8 Кбайт и 48 % — менее 1 Кбайта. Несмотря на то, что эти данные варьируются от одной реализации системы к другой, для многих реализаций системы UNIX они показательны. 12 Чтобы изменить для себя корневой каталог файловой системы, процесс может запустить системную операцию chroot. Новое значение корня сохраняется в рабочей области процесса. 13 Как и в предыдущей главе, здесь под «процессом» имеется ввиду «ядро, действующее от имени процесса». |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||