|
||||
|
|
-e) форматы -сили -u Часть IVСообщество 17Переносимость: переносимость программ и соблюдение стандартов
Unix была первой действующей операционной системой, переносимой между различными семействами процессоров (Version 6 Unix, 1976 - 1977). В настоящее время Unix регулярно переносится на все новые машины, мощность которых достаточна для поддержки блока управления памятью. Unix-приложения просто переносятся между Unix-системами, работающими на различном аппаратном обеспечении; фактически, неудачные попытки переноса не известны. Переносимость всегда была одним из принципиальных преимуществ Unix. Unix-программисты склонны писать программы, основываясь на предположении, что аппаратное обеспечение изменчиво, а стабилен только Unix API, и делая как можно меньше предположений о специфических характеристиках машин, таких как длина машинного слова, порядок следования байтов или архитектура памяти. Фактически код, так или иначе зависящий от аппаратного обеспечения, который выходит за пределы абстрактной машинной модели языка С, считается в Unix-кругах плохим и действительно допускается только в очень специфических случаях, таких, например, как ядра операционных систем. Unix-программисты знают по опыту, что очень легко ошибиться, предрекая короткую жизнь программному проекту[136]. Поэтому они склонны избегать создания программного обеспечения, зависимого от специфических и недолговечных технологий, и в большой степени полагаются на открытые стандарты. Привычка писать программы с учетом переносимости уже стала одной из традиций Unix, так что теперь она относится даже к мелким проектам, которые задумывались как однократно используемый код. Она оказала влияние на всю конструкцию инструментария Unix-разработчика, а также на языки программирования, такие как Perl, Python и Tcl, которые создавались в Unix-среде. Непосредственный выигрыш от переносимости заключается в том, что для Unix-программ является нормой пережить свою исходную аппаратную платформу, поэтому не требуется каждые несколько лет заново изобретать инструменты и приложения. Сегодня приложения, первоначально написанные для Version 7 Unix (1979), регулярно используются не только на Unix-системах, "генетически" происходящих от V7, но и на таких вариантах системы, как Linux, в которой API-интерфейс операционной системы был написан на основании Unix-спецификации и не содержит кода, заимствованного у Bell Labs. Косвенная выгода менее очевидна, но, возможно, более важна. Дисциплина переносимости склонна упрощать архитектуры, интерфейсы и реализации. Это увеличивает вероятность успешного проекта и сокращает затраты на обслуживание в течение жизненного цикла программ. В данной главе рассматривается диапазон и история Unix-стандартов. Ниже обсуждается, какие стандарты до сих пор актуальны, и описываются области большего или меньшего расхождения в Unix API. Кроме того, здесь рассматриваются инструменты и практические приемы, которые используются Unix-разработчиками для сохранения переносимости кода, а также формулируются некоторые важные принципы хорошей практики. 17.1. Эволюция СГлавным фактом практики Unix-программирования всегда была стабильность языка С и небольшого количества служебных интерфейсов, которые всегда ему сопутствовали (особенно стандартная I/O-библиотека и подобные ей). Тот факт, что язык, созданный в 1973 году, в течение тридцати лет интенсивного использования потребовал небольших изменений, является действительно примечательным, в этом отношении язык С не имеет аналогов в компьютерной науке. В главе 4 приводились аргументы в пользу того, что С достиг успеха, благодаря тому, что он выполняет роль тонкого связующего уровня над аппаратным обеспечением компьютера, приближающимся к "стандартной архитектуре" [4]. Однако для того чтобы понять другие факторы, необходимо кратко рассмотреть историю данного языка. 17.1.1. Ранняя история СЯзык С родился в 1971 году как язык системного программирования для PDP-11-варианта Unix и основывался на раннем интерпретаторе языка В, разработанного Кеном Томпсоном. Язык В, в свою очередь, был смоделирован с базового языка общего программирования (Basic Common Programming Language — BCPL), разработанного в Кембриджском университете в 1966–1967 годах[137]. Первоначальный C-компилятор Денниса Ритчи (который часто называли "DMR" по инициалам его создателя) обслуживал сообщество, быстро разрастающееся вокруг операционной системы Unix версий 5, 6 и 7. От шестой версии С языка произошла версия С компании Whitesmiths, повторная реализация, которая стала первым коммерческим C-компилятором и ядром IDRIS, первого клона Unix. Однако самые современные реализации С смоделированы на основе "переносимого C-компилятора" (Portable С Compiler — PCC) Стивена Джонсона (Steven С. Johnson), который дебютировал в седьмой версии и полностью заменил компилятор DMR как в ветви System V, так и в BSD-версиях четвертого поколения. В 1976 году в шестой версии С были представлены объявления typedef, unionи unsigned int. Также подверглись изменениям утвержденный синтаксис для инициализации переменных и некоторые составные операторы. Оригинальным описанием языка С была книга Брайана Кернигана и Денниса Ритчи "The С Programming Language", которую также называли "Белой книгой" [42]. Она была опубликована в 1978 году, в том же году появился C-компилятор Whitemiths. Белая книга описывала усовершенствованную шестую версию языка С с одним значительным исключением, которое касалось обработки общедоступных переменных. Первоначально Ритчи намеревался смоделировать правила С с COMMON- объявлений языка FORTRAN, основываясь на теоретическом соображении, что любая машина, способная поддерживать FORTRAN, будет готова к использованию С. В модели с общим блоком общедоступная переменная может быть объявлена несколько раз; идентичные объявления объединяются компоновщиком. Однако два ранних варианта С (для мэйнфреймов Honeywell и IBM 360) работали на машинах с очень ограниченной общей памятью или примитивным компоновщиком, или имели оба недостатка. Таким образом, компилятор Version 6 С был перенесен в боле строгую модель определения (которая требовала максимум одно определение любой заданной общедоступной переменной и ключевого слова extern, задающего на нее ссылки), описанную в [42]. Это решение было отменено в C-компиляторе, который поставлялся с Version 7, после выяснения того, что большое количество существующего исходного кода зависело от более свободных правил. Под давлением обратной совместимости закончилась неудачей еще одна попытка перестроиться (в версии System V Release 1 1983 года), перед тем как в 1988 году в проекте стандарта ANSI (ANSI Draft Standard) окончательно установились правила определения. Общий блок внешних переменных до сих пор является общепризнанным отклонением от стандарта. В седьмой версии С была введена конструкция enum, а значения structи unionинтерпретировались как объекты первого класса, которые можно назначать, передавать в качестве аргументов и возвращать из функций (вместо передачи по адресу).
Версия System III С компилятора PCC (которая также поставлялась с BSD 4.1с) изменила обработку объявлений structтак, чтобы члены с одинаковыми именами в различных структурах не конфликтовали. Также были внесены объявления voidи unsigned char. Область действия extern-объявлений локальных для функций была ограничена данной функцией и более не включала всего следующего за ней кода. В проекте стандарта ANSI С (ANSI С Draft Proposed Standard) были добавлены определения const(для памяти только для чтения) и volatile(для таких ячеек, как отображаемые на память регистры ввода/вывода, которые можно модифицировать асинхронно из потока управления программы). В целях применения к любому типу был обобщен модификатор типа unsigned, а также добавлен идентификатор signed. Был добавлен синтаксис для auto-массива, инициализаторов структур, а также типов union. Наиболее важно то, что были добавлены прототипы функций. Самыми важными изменениями в раннем С был переход к определению и введение прототипов функций в проекте стандарта ANSI С. Язык по существу остается стабильным с тех пор, как в 1985 - 1986 годах копии рабочих документов комитета X3J11 по проекту стандарта довели намерения комитета до сведения разработчиков компиляторов. Более подробно история раннего С описана создателем языка в статье [70]. 17.1.2. Стандарты СРазработка стандартов С была консервативным процессом, в котором серьезное внимание уделялось "сохранению духа" оригинального С, а акцент был сделан скорее на утверждении экспериментов в существующих компиляторах, чем на создании новых функций. Документ-хартия C9X (C9X charter)[138] является превосходным выражением данной миссии. Работа над первым официальным стандартом С началась в 1983 году при содействии комитета X3J11 ANSI. Главные функциональные дополнения к языку были утверждены к концу 1986 года, и с этого момента программисты стали различать "K&R С" и "ANSI С".
Несмотря на то, что основа ANSI С была согласована достаточно рано, споры о содержимом стандартных библиотек продолжались в течение нескольких лет. Формальный стандарт не был опубликован до конца 1989 года, сразу после этого в большинстве компиляторов были реализованы рекомендации 1985 года. Данный стандарт первоначально назывался ANSI Х3.159, но был переименован в ISO/IEC 9899:1990, когда Международная организация по стандартизации (International Standards Organization — ISO) приняла на себя спонсорские обязательства. Описываемый в стандарте вариант языка обычно называется C89 или C90. Первая книга по С и практической реализации переносимости, "Portable С and Unix Systems Programming" [44], была опубликована в 1987 году. (Я написал ее под корпоративным псевдонимом, навязанным мне моими тогдашними работодателями.) Второе издание книги Кернигана и Ритчи [42] вышло в 1988 году. Очень незначительная модификация C89, названная Amendment 1 (поправка 1), AM1, или C93, появилась в 1993 году. В ней было добавлено больше возможностей по поддержке широких символов и Unicode. Данный стандарт получил название ISO/IEC 9899-1:1994. Пересмотр стандарта C89 начался в 1993 году. В 1999 году организация ISO приняла стандарт ISO/IEC 9899 (обычно называемый C99). Он включал в себя Amendment 1 и большое количество мелких функций. Возможно, наиболее значительной из них для большинства программистов является возможность объявлять переменные в любом месте блока, а не только в начале (аналогичная языку С++). Кроме того, в стандарте были добавлены макросы с переменным числом аргументов. Рабочая группа C9X имеет Web-страницу <http://anubis.dkuug.dk/JTC1/SC22/WG14/www/projеcts>, но к середине 2003 года планов на третий проект стандарта не было. Члены рабочей группы разрабатывают дополнения к С для встроенных систем. Стандартизации С значительно способствовал тот факт, что работающие и почти полностью совместимые реализации языка функционировали на множестве различных систем до того, как началась работа по стандартизации. Это сильно ограничило споры о том, какие функции должны присутствовать в стандарте. 17.2. Стандарты UnixТот факт, что в 1973 году Unix была переписана на С, беспрецедентно упростил переносимость и модификацию операционной системы. В результате исходная Unix вскоре разделилась на семейство операционных систем. Unix-стандарты первоначально разрабатывались в целях согласования API-интерфейсов различных ветвей фамильного дерева. Unix-стандарты, развившиеся после 1985 года, были весьма успешными в этом отношении — настолько успешными, что легли в основу высоко ценимой документации по API современных реализаций Unix. Фактически реальные Unix-системы так близко придерживаются опубликованных стандартов, что разработчики могут (а часто так и делают) узнать больше, изучая такие документы, как спецификация POSIX, чем официальные справочные руководства для используемого варианта Unix. Действительно, в наиболее новых Unix-системах с открытым исходным кодом (таких как Linux) широко распространена практика проектирования функций операционной системы с использованием опубликованных стандартов как спецификации. Этот момент рассматривается в ходе изучения стандартов RFC далее в настоящей главе. 17.2.1. Стандарты и Unix-войныПервоначальным мотивом для разработки Unix-стандартов было расхождение линий разработки AT&T и Университета Беркли, которое рассматривалось в главе 7. Unix-системы 4.x BSD происходили от Version 7, вышедшей в 1979 году. После выхода 4.1 BSD в 1980 году BSD-линия быстро приобрела репутацию революционной Unix-системы. В число важных дополнений входили визуальный редактор vi, средства контроля заданий для управления с одной консоли многочисленными высокоприоритетными и фоновыми задачами, а также усовершенствование сигналов (см. главу 7). Несравненно более важным дополнением была поддержка TCP/IP-сетей, но хотя Университет Беркли получил контракт на их реализацию в 1980 году, протокол TCP/IP в течение трех лет не включался в состав внешних версий. Однако другая версия, System III, появившаяся в 1981 году, стала основой дальнейшей разработки в корпорации AT&T. В System III интерфейс терминалов версии 7 был переработан в более четкую и изящную форму, которая была абсолютно несовместимой с усовершенствованиями Беркли. В ней сохранялась (необратимая) семантика сигналов (см. главу 7). В состав январской версии System V Release 1 в 1983 году вошли некоторые BSD-утилиты (такие как vi(1)). Первая попытка заполнить разрыв была предпринята в феврале 1983 года влиятельной группой Unix-пользователей, UniForum. Вышедший в 1983 году проект стандарта Uniforum (Uniforum 1983 Draft Standard — UDS 83) описывал "основную Unix систему", состоящую из подмножества ядра System III и библиотек плюс примитив блокировки файлов. AT&T объявила о поддержке UDS 83, однако данный стандарт представлял собой неадекватный набор разрабатываемых практических приемов 4.1BSD. Проблема обострилась с выходом в июле 1983 года 4.2BSD, в которой было добавлено множество новых функций (включая TCP/IP-сети) и введена некоторая неочевидная несовместимость с исходной версией 7. Лишение прав компаний Bell в 1984 году и начало Unix-войн (см. главу 2) значительно усложнило проблемы. Sun Microsystems лидировала в индустрии рабочих станций в BSD-направлении; AT&T пыталась внедриться в компьютерный бизнес и использовать контроль над Unix как стратегическое оружие, даже продолжая лицензировать операционную систему таким конкурентам, как Sun. Все поставщики принимали бизнес-решения дифференцировать свои версии Unix для получения конкурентного преимущества. В ходе Unix-войн техническая стандартизация стала точкой зрения, которую отстаивали сотрудничающие технические специалисты, а большинство менеджеров по продуктам принимали ее неохотно или активно сопротивлялись. Одним крупным и важным исключением была корпорация AT&T, которая, анонсируя в январе 1984 года System V Release 2 (SVr2), объявила о намерении сотрудничать с группами пользователей по формированию стандартов. Второй пересмотр проекта стандарта UniForum в 1984 году проложил путь и одновременно повлиял на API SVr2. Позднее Unix-стандарты также стремились следовать System V, кроме тех областей, где BSD-средства имели очевидное функциональное превосходство (поэтому, например, современные стандарты Unix описывают средства управления терминалами System V, вместо BSD-интерфейса к тем же средствам). В 1985 году AT&T опубликовала документ System V Interface Definition (SVID), в котором содержалось более формальное описание SVr2 API, включающего стандарт UDS 84. Более поздние модификации SVID2 и SVID3 наметили курс на создание интерфейсов System V версий 3 и 4. Документ SVID стал основой POSIX-стандартов, которые в конечном итоге склонили большую часть спора Беркли/АТ&Т по поводу системных и библиотечных вызовов С в сторону подхода AT&T. Однако это не стало очевидным в течение еще нескольких лет. Тем временем Unix-войны были в разгаре. Например, в 1985 году вышли два конкурирующих API-стандарта для файловой системы с совместным доступом по сети: Network File System (NFS) корпорации Sun и АТ&Т-система Remote File System (RFS). NFS-система выиграла, поскольку Sun была готова разделить с другими не только спецификации, но и открытый исходный код. Это был настоящий успех, потому что по своему логическому построению система RFS была все-таки лучшей моделью. Она поддерживала лучшую семантику блокировки файлов и лучшую идентификацию пользователей в различных системах и, в отличие от NFS, как правило, была направлена на точное получение более мелких деталей семантики файловой системы Unix. Однако данный урок был проигнорирован, даже когда в 1987 году его повторила система X Window с открытым исходным кодом, победив частную систему Sun Networked Window System (NeWS). После 1985 года главные вопросы по Unix-стандартизации решались Институтом инженеров электротехники и электроники (Institute of Electrical and Electronic Engineers — IEEE). Комитет 1003 IEEE разработал серию стандартов, которые широко известны как POSIX[139]. Данные стандарты выходили за рамки простых системных вызовов и библиотечных средств С. Они определяли подробную семантику оболочки и минимальный набор команд, а также детальные привязки для различных языков программирования, отличных от С. Первая версия появилась в 1990 году, а вторая редакция была опубликована в 1996 году. Международная организация по стандартизации (International Standards Organization — ISO) приняла данные стандарты под названием ISO/IEC 9945. Ниже перечислены некоторые из ключевых POSIX-стандартов. 1003.1 (опубликован в 1990 году) Библиотечные процедуры. Описание API системных вызовов С, очень похожее на Version 7, кроме сигналов и интерфейса управления терминалами. 1003.2 (опубликован в 1992 году) Стандартная оболочка и утилиты. Семантика оболочки строго повторяет семантику Bourne shell в System V. 1003.4 (опубликован в 1993 году) Unix-система реального времени. Бинарные семафоры, блокировка памяти процесса, файлы с распределением памяти, приоритетное расписание, сигналы реального времени, циклы и таймеры, передача IPC-сообщений, синхронизированный I/O, асинхронный I/O, файлы реального времени. Во втором издании 1996 года стандарт 1003.4 был разделен на 1003.1b (система реального времени) и 1003.1с (параллельные процессы). Несмотря на то, что некоторые ключевые области, такие как семантика обработки сигналов и упущение BSD-сокетов, были недоопределены, первоначальные POSIX-стандарты стали основой всей последующей работы по стандартизации Unix. Они до сих пор цитируются как авторитетные, хотя и косвенно, посредством таких справочников, как "POSIX Programmer's Guide" [47]. Де-факто стандарт Unix API до сих пор остается "POSIX плюс сокеты", более поздние стандарты, главным образом, добавляют функции и более точно определяют согласование в необычных крайних случаях. Следующим игроком на этом поле была группа X/Open (позднее переименованная в Open Group), консорциум поставщиков Unix, сформированный в 1984 году. Стандарты данной организации X/Open Portability Guides (XPGs) первоначально развивались параллельно с проектами POSIX, а затем после 1990 года стандарты XPGs были включены в POSIX и расширили его. В отличие от POSIX, который представлял собой попытку сбора надежного подмножества из всех Unix-систем, стандарты XPGs больше склонялись к общей практике в наиболее развитом участке исследований; даже XPG1 в 1985 году, охватывающий системы SVr2 и 4.2BSD, включал в себя сокеты. В 1987 году в стандарт XPG2 был добавлен API-интерфейс поддержки терминалов, которым, по существу, была библиотека curses(3) системы System V. XPG3 в 1990 году влился в X11 API. XPG4 в 1992 году полностью утвердил полное соответствие стандарту 1989 года ANSI С. В стандартах XPG2, 3 и 4 интенсивно рассматривалась поддержка интернационализации и описывался сложный API для обработки наборов кодов и каталогов сообщений. В материалах по стандартам Unix могут встретиться ссылки на стандарты "Spec 1170" (1993 года), "Unix 95" (1995 года) и "Unix 98" (1998 года). Это были сертификационные знаки стандартов X/Open, и в настоящее время они представляют только исторический интерес. Однако работа над стандартом XPG4 превратилась в спецификацию Spec 1170, которая стала первой версией Единой спецификации Unix (Single Unix Specification, SUS). В 1993 году 75 поставщиков систем и программного обеспечения, включая все главные Unix-компании, поставили окончательную точку в Unix-войнах, когда объявили о финансовой поддержке X/Open в разработке общего определения Unix. Как часть данного соглашения X/Open приобрела права на торговую марку Unix. Объединенный стандарт стал называться Single Unix Standard (Единый стандарт Unix) версии 1. Версия 2 вышла в 1997 году. В 1999 году деятельность по стандарту POSIX перешла к X/Open. В 2001 году группа X/Open (сейчас The Open Group) выпустил Единый стандарт Unix версии 3 (Single Unix Standard version 3) <http://www.Unix.org/version3/>. Все "потоки" стандартизации Unix API были, наконец, объединены в одно целое. Различные вариации Unix воссоединились на основе общего API. И это было встречено с большим энтузиазмом, по крайней мере, среди давних поклонников Unix, которые помнили о бурях 80-х годов. 17.2.2. Влияние новых Unix-системК сожалению, была одна неудобная деталь — поставщики Unix старой школы, финансирующие данный проект, находились под сильным влиянием со стороны Unix-систем новой школы с открытым исходным кодом, а в некоторых случаях они даже отказывались (в пользу Linux) от коммерческих Unix-систем, ради которых они потратили так много усилий для достижения надежного соответствия. Тестирование соответствия, необходимое для проверки соответствия Единой спецификации Unix, — дорогая проблема. Оно должно осуществляться для каждого дистрибутива, но не учитывает многообразия дистрибьюторов операционных систем с открытым исходным кодом. В любом случае, Linux изменяется столь быстро, что любая версия дистрибутива, вероятно, устарела бы к моменту окончания сертификации[140]. Стандарты, подобные Single Unix Specification, не утратили полностью своей значимости. Они все еще являются ценными руководящими принципами для разработчиков Unix. Однако далее стоит рассмотреть то, как "The Open Group" и другие организации, связанные с процессом стандартизации Unix старой школы, будут приспосабливаться к быстрому темпу выхода версий с открытым исходным кодом (а также к малобюджетному или безбюджетному функционированию групп разработчиков программного обеспечения с открытым исходным кодом). 17.2.3. Стандарты Unix в мире открытого исходного кодаВ середине 1990-х годов сообщество открытого исходного кода начало собственную работу по стандартизации. Эти усилия основывались на совместимости на уровне кода, закрепленной стандартом POSIX и его потомками. В частности Linux, была написана с нуля способом, который зависел от доступности таких стандартов Unix API, как POSIX[141]. В 1998 году компания Oracle перенесла на Linux свой лидирующий на рынке баз данных продукт, этот шаг справедливо рассматривается как главный прорыв в движении принятия Linux. Ответственный инженер проекта, в подтверждение того, что API-стандарты выполнили свою задачу, на вопрос репортера о том, какие технические трудности пришлось преодолеть Oracle ответил: "Мы вводили make". Таким образом, проблемой для Unix-систем новой школы была не API-совместимость на уровне исходного кода. Все принимают как должное возможность переносить исходный код между различными Linux, BSD и коммерческими дистрибутивами Unix без необходимости тратить серьезные усилия на обеспечение переносимости кода. Новой проблемой была не совместимость исходного кода, а бинарная совместимость. Почва под Unix неожиданно зашаталась вследствие массового спроса на аппаратное обеспечение PC. В прежние времена каждая Unix-система работала на той аппаратной платформе, которая фактически была ее собственной. Было достаточно много различных наборов инструкций процессоров и аппаратных архитектур, на которые необходимо было переносить приложения на уровне исходного кода, чтобы вообще их перенести. С другой стороны, существовало сравнительно небольшое число основных версий Unix, каждая с относительно длительным сроком службы. Поставщики приложений, такие как Oracle, могли позволить себе затраты на компиляцию и распространение отдельных бинарных дистрибутивов для каждой из трех или четырех комбинаций аппаратно-программного обеспечения, поскольку они могли распределить затраты на перенос исходного кода среди большого числа клиентов и в течение достаточно долгого жизненного цикла продуктов. Но затем поставщиков мини-компьютеров и рабочих станций захлестнул волна недорогих персональных компьютеров на основе процессоров 386-й серии, и Unix-системы с открытым исходным кодом изменили правила игры. Поставщики обнаружили, что они более не имеют стабильной платформы для поставки своих бинарных дистрибутивов. Внешней проблемой, на первый взгляд, было большое количество дистрибутивов Unix, но по мере консолидации рынка Linux-дистрибутивов, становилось ясно, что реальной проблемой была скорость изменения. API-интерфейсы были стабильны, но ожидаемое расположение файлов системного администрирования, утилит, и таких элементов, как префиксы путей к пользовательским почтовым ящикам и файлам системных журналов, продолжало изменяться. Первым проектом по стандартизации, который развился внутри нового сообщества Linux и BSD (начиная с 1993 года) был Стандарт иерархии файловой системы (Filesystem Hierarchy Standard — FHS). Он был включен в состав Базы стандартов Linux (Linux Standards Base — LSB), которая также стандартизировала ожидаемый набор служебных библиотек и вспомогательных приложений. Оба стандарта стали результатом деятельности Группы свободных стандартов (Free Standards Group) <http://www.freestandards.org/>, которая к 2001 году стала играть роль аналогичную позиции консорциума X/Open среди Unix-поставщиков старой школы. 17.3. IETF и процесс RFC-стандартизацииКогда Unix-сообщество соединилось с культурой Internet-инженеров, в него также проникло мышление, сформированное процессом RFC-стандартизации IETF (Internet Engineering Task Force — Инженерная группа по решению конкретной задачи в Internet). Согласно традиции IETF, стандарты должны возникать из опыта с работающим прототипом, но как только они становятся стандартами, код, который им не соответствует, считается нерабочим и безжалостно уничтожается. К сожалению, обычно стандарты разрабатываются иначе. История вычислительной техники полна примеров того, как технические стандарты создавались в ходе процесса, объединявшего в себе худшие черты "грубой" философии и темной закулисной политики, что приводило к созданию спецификаций, которые не способны были повторить какие-либо существующие реализации. Еще хуже то, что многие из них были либо настолько требовательными, что практически не могли быть реализованными, либо настолько недоработанными, что создавали больше проблем, чем решали. Затем они пропагандировались среди поставщиков, которые при любом удобном случае игнорировали их, если они создавали неудобства. Одним из самых печально известных примеров абсурдной стандартизации были сетевые протоколы Открытого взаимодействия систем (Open Systems Interconnect, OSI), которые недолго конкурировали с TCP/IP в 1980-х годах — семиуровневая модель на расстоянии выглядела изящной, но оказалась чрезмерно сложной и нереализуемой на практике[142]. Другим широко известным негативным примером является стандарт ANSI Х3.64 для средств видеотерминалов, испорченный едва различимой несовместимостью между юридически согласованными реализациями. Даже после того, как символьные терминалы почти были вытеснены растровыми дисплеями, несовместимость продолжала создавать проблемы (в частности, именно поэтому функциональные и специальные клавиши в программе xterm(1) иногда нарушают ее работу). Стандарт RS232 для последовательных соединений был настолько недоопределенным, что иногда казалось, будто не существует двух одинаковых последовательных кабелей. Для описания всех подобных отрицательных примеров стандартов, возможно, потребовалась бы книга такого же объема. Существует известная фраза, которая обобщает философию IETF: "Мы отвергаем королей, президентов и голосование. Мы верим в суровое единодушие и работающий код"[143]. Данное требование существования работающей реализации предохранило ее от грубейших ошибок. В действительности критерий еще строже.
Все IETF-стандарты проходят стадию документов RFC (Requests for Comment — запросы на комментарии). Процесс подачи RFC умышленно неформален. RFC-документы могут предлагать стандарты, результаты исследований, формулировать философские обоснования для последующих RFC-документов или даже представлять собой шутки. Появление ежегодного первоапрельского RFC является ближайшим эквивалентом соблюдения "религиозного праздника" среди Internet-хакеров, что привело к возникновению таких перлов, как "A Standard for the Transmission of IP Datagrams on Avian Carriers" (RFC 1149, стандарт для передачи IP-дейтаграмм с голубиной почтой)[144], "The Hyper Text Coffee Pot Control Protocol" (RFC 2324, гипертекстовый протокол управления кофеваркой)[145] и "The Security Flag in the IPv4 Header" (RFC3514, защитный флаг в заголовке IPv4)[146]. Однако шуточные RFC-документы — единственный вид документов, которые немедленно становятся RFC. Серьезные предложения в действительности начинают свой путь как "Internet-Drafts" (Internet-черновики), которые распространяются для публичного комментирования через IETF-каталоги на нескольких широко известных узлах. Отдельные Internet-черновики не имеют формального статуса и могут быть изменены или удалены их создателями в любое время. Черновики, которые не были отозваны, но и не получили статус RFC, удаляются по истечении шести месяцев. Internet-черновики не являются спецификациями, и разработчики, а также поставщики программного обеспечения особенно отказываются соглашаться с ними. Internet-черновики являются центральными точками обсуждения, обычно в рабочей группе, члены которой сообщаются посредством почтовой рассылки. Когда руководство рабочей группы сочтет целесообразным, Internet-черновик представляется на рассмотрение RFC-редактору для присвоения номера RFC. Internet-черновик, опубликованный с RFC-номером, является спецификацией, с которой могут согласиться разработчики. Ожидается, что авторы RFC-документа и сообщество в целом начнут корректировать данную спецификацию на основании практического опыта. Некоторые RFC-документы не продвигаются дальше этой стадии. Спецификация, которая не смогла привлечь внимание и не прошла реальных испытаний, может быть быстро позабыта, и в конечном счете маркируется RFC-редактором как "Not recommended" (не рекомендуется) или "Superseded" (отменено). Неудачные предложения принимаются как издержки процесса, и не считается зазорным быть связанным с таким предложением. Управляющий комитет IETF (IESG или Internet Engineering Steering Group — группа технического управления Internet) отвечает за продвижение успешных RFC-документов в виде стандартов путем присвоения им грифа "Proposed Standard" (предложенный стандарт). Для того чтобы RFC квалифицировался как стандарт, спецификация должна быть стабильной, пройти экспертную оценку и привлечь значительный интерес Internet-сообщества. Опыт реализации не является абсолютно необходимым, прежде чем RFC получит обозначение Proposed Standard, но считается весьма желательным, и IESG может его потребовать, если RFC затрагивает основные протоколы или иным образом способен дестабилизировать Internet. Предложенные стандарты постоянно пересматриваются и даже могут быть отозваны, если IESG и IETF найдут лучшее решение. Их не рекомендуется использовать в "средах, чувствительных к нарушениям", поэтому не следует применять их в системах управления авиатранспортом или в оборудовании для интенсивной терапии. Когда существует как минимум две работающие, полные, независимо созданные и способные к взаимодействию реализации предложенного стандарта, IESG может повысить стандарт до статуса "Draft Standard" (проект стандарта). RFC 2026 гласит: "Повышение до проекта стандарта является главным повышением статуса и подтверждает уверенность в том, что данная спецификация сформировалась и будет полезной". RFC-документ, получивший статус Draft Standard, будет изменяться только в целях исправления ошибок логики спецификации. Ожидается, что спецификации, имеющие такой статус, готовы для внедрения в чувствительные к нарушениям среды. Когда проект стандарта прошел тест широко распространенной реализации и получил общее одобрение, он может быть назван Internet Standard (Стандарт Internet). Такие стандарты сохраняют свои RFC-номера и, кроме того, получают номер STD-серии. На момент написания данной книги существовало более 3 тыс. RFC и только 60 STD-стандартов. RFC, отклоняющиеся от схемы стандартизации, могут быть обозначены как Experimental (экспериментальные), Informational (информационные; шуточные RFC тоже получают такое обозначение) или Historic (имеющие историческое значение). Последнее обозначение применимо к вышедшим из употребления стандартам. Цитата из RFC 2026: "Борцы за чистоту литературного языка предложили использовать слово Historical (исторически сложившийся); однако в данном случае "исторически сложившимся" является использование слова Historic." Процесс создания стандартов IETF направлен на поощрение стандартизации, вызванной скорее практикой, чем теорией, и гарантирует, что стандартные протоколы подверглись скрупулезной экспертной оценке и тестированию. Успех данной модели подтверждается ее результатами — всемирной сетью Internet. 17.4. Спецификации — ДНК, код — РНКДаже в давние времена PDP-7 Unix-программисты всегда (больше чем их коллеги, работающие с другими системами) были склонны рассматривать старый код как непригодный к повторному использованию. Это, несомненно, было продуктом Unix-традиции, которая акцентировала внимание на модульности, облегчающей выбраковку и замену небольших блоков систем без потери целого. Unix-программисты уяснили из опыта, что попытки сохранения плохого кода или плохого дизайна часто являются более трудоемкими, чем создание проекта заново. Там, где в других культурах программирования инстинкт подсказывал бы исправлять неповоротливые монолиты, потому что в них вложено много труда, инстинкт Unix-программиста обычно ведет к выбрасыванию старого кода и созданию нового. Традиция IETF усилила этот инстинкт, научив нас считать код вторичным по отношению к стандартам. Стандарты являются тем, что позволяет программам взаимодействовать; они связывают технологии в единое целое. Опыт IETF показывает, что тщательная разработка стандартов, стремящаяся к сбору лучшего из существующей практики, является той формой сдержанности, которая достигает гораздо большего, чем претенциозные попытки переделать мир по образу нереализуемого идеала. После 1980 года влияние данного урока стало более заметно в Unix-сообществе. Поэтому, несмотря на то, что стандарт ANSI/ISO С 1989 года не был абсолютно безупречным, он был исключительно четким и практичным для стандарта такого размера и важности. Единая спецификация Unix содержит "атавизмы" трех десятилетий экспериментов и фальстартов в более сложной области и, следовательно, является более беспорядочной, чем ANSI С. Однако компонентные стандарты, из которых она собрана, весьма хороши; твердым доказательством этого является тот факт, что, читая ее, Линус Торвальдс успешно создал Unix с нуля. Скромный, но мощный пример IETF создал один из критически важных блоков среды, которая сделала возможным подвиг Торвальдса. Уважение к опубликованным стандартам и процессу IETF глубоко проникло в Unix-культуру. Умышленное нарушение Internet STD-стандартов просто невыполнимо. Это может иногда создавать пропасть взаимного непонимания между людьми с Unix-опытом и другими, склонными предполагать, что наиболее популярная или широко распространенная реализация протокола по определению является верной — даже если она нарушает стандарт так жестко, что не способна взаимодействовать с тщательно согласованным программным обеспечением. Для Unix-программиста характерно уважение к опубликованным стандартам, поэтому он, скорее всего, будет враждебно относиться к спецификациям других видов. К тому времени, когда "водопадная модель" (исчерпывающая спецификация, затем реализация, затем отладка без возврата к любой стадии) утратила популярность в литературе по программной инженерии, она уже в течение многих лет была предметом насмешек среди Unix-программистов. Опыт и сильная традиция совместной разработки уже научили их, что лучший способ заключается в создании прототипов и повторных циклах тестирования и развития. Традиция Unix четко определяет, что спецификации могут иметь большую ценность, но требует, чтобы они интерпретировались как временные и постоянно пересматривались в процессе практического использования так же, как пересматриваются стандарты Internet-Drafts и Proposed Standards. В лучшей практике Unix документация на программу используется как спецификация, подлежащая пересмотру, аналогично предложенному стандарту Internet.
Частичная автоматизация создания тестовых комплектов обоснованно считается главным преимуществом. Практический опыт и достижения в области графического искусства побудили многих критиковать систему X относительно конструкции, а различные ее части (такие как безопасность и модели пользовательских ресурсов) кажутся неповоротливыми и слишком усложненными. Но несмотря на это реализация X достигла выдающегося уровня стабильности и совместимости систем, создаваемых различными поставщиками. В главе 9 обсуждалось значение переноса программирования на как можно более высокий уровень в целях минимизации влияния постоянной плотности ошибок. Цитата Кита Паккарда скрывает в себе идею о том, что документация системы X представляет собой не просто перечень пожеланий, а некоторую форму высокоуровневого кода. Другой ведущий разработчик X подтверждает это мнение.
Далее Джим отмечает, что процесс развития X фактически весьма похож на процесс IETF. Его польза не ограничивается конструированием хороших тестовых комплектов; это означает, что спорить о поведении системы можно на функциональном уровне по отношению к спецификации, предотвращая слишком большую путаницу в вопросах реализации.
Позиция предшествующих стандартов имеет свои преимущества также и для конечных пользователей. Тогда как уже не маленькая компания восточнее Белвю имеет проблемы, сохраняя совместимость офисного набора с его предыдущими версиями, GUI-приложения, написанные в 1988 году, до сих пор работают без изменений на нынешних реализациях системы X. В мире Unix подобное долголетие является нормой, а причиной этого является позиция "стандарт как ДНК". Таким образом, опыт показывает, что культура Unix, культивирующая уважение к стандартам, а также отбрасывание и переделку ошибочного кода, часто приводит к большей возможности взаимодействия в течение более продолжительного периода времени, чем постоянное исправление базы кода без стандарта, который обеспечивает управление и непрерывность. Это, несомненно, может быть одним из наиболее важных уроков Unix. Последнее замечание Кита непосредственно приводит к вопросу, который выдвигается на передний план благодаря успеху Unix-систем с открытым исходным кодом — связь между открытыми стандартами и открытым исходным кодом. Данная проблема рассматривается в конце главы, но перед этим необходимо изучить практический вопрос: каким образом Unix-программисты могут действительно использовать огромную массу накопленных стандартов и как овладеть практическими знаниями для достижения переносимости программного обеспечения? 17.5. Программирование, обеспечивающее переносимостьПереносимость программ обычно рассматривается в квази-пространственных понятиях: возможно ли перенести данный код на существующее аппаратно-программное обеспечение, отличное от того, для которого код создавался? Однако десятки лет опыта Unix подсказывают, что долговечность во времени важна в той же степени, если не в большей. Если бы можно было подробно предсказать будущее программного обеспечения, то оно, вероятно, было бы настоящим. Тем не менее, в программировании, обеспечивающем переносимость, следует пытаться обдумывать варианты построения программ на основе тех функций окружающей системы, которые, вероятнее всего, сохранятся, и избегать технологий, которые, скорее всего, в обозримом будущем прекратят свое существование. Что касается Unix, два десятка лет изучения вопросов определения переносимых API-интерфейсов позволили полностью решить данную проблему. Средства, описанные в Единой спецификации Unix, вероятно, будут присутствовать во всех современных Unix-платформах и вряд ли не будут поддерживаться в будущем. Однако не все зависимости от платформы разрешаются с помощью системных или библиотечных API-интерфейсов. Язык реализации также имеет значение; кроме того, проблемы могут быть обусловлены структурой файловой системы и конфигурационными отличиями между исходной и целевой системой. Однако практика Unix уже подтвердила способы решения данных проблем. 17.5.1. Переносимость и выбор языкаПервым вопросом в программировании, обеспечивающем переносимость, является выбор языка реализации. Все основные языки, рассмотренные в главе 14, являются высоко переносимыми в том смысле, что совместимые реализации доступны на всех современных Unix-системах, а для большинства из них также доступны реализации для Windows и MacOS. Проблемы переносимости часто возникают не в основных языках, а в библиотеках поддержки и степени интеграции с локальным окружением (особенно в IPC-методах и управлении параллельными процессами, включая инфраструктуру для GUI-интерфейсов). 17.5.1.1. Переносимость СБазовый язык С в высшей степени переносим. Его стандартной реализацией в Unix является GNU C-компилятор, который повсеместно распространен не только Unix-системах с открытым исходным кодом, но и современных коммерческих вариантах операционной системы. GNU С был перенесен на Windows и классическую MacOS, но ни в одной из этих сред не стал широко распространенным, поскольку испытывает недостаток в переносимых привязках к собственным GUI-интерфейсам данных систем. Стандартная библиотека ввода/вывода, математические подпрограммы и поддержка интернационализации переносимы во всех реализациях С. Файловый ввод/вывод, сигналы и управление процессами являются переносимыми между вариантами Unix, при условии, что используются только современные API-интерфейсы, описанные в Единой спецификации Unix; более старый C-код часто содержит нагромождения условных операторов препроцессора, направленных на достижение переносимости, но они поддерживают интерфейсы, появившиеся до стандарта POSIX, из старых коммерческих Unix-систем, которые по состоянию на 2003 год устарели или близки к этому. Более серьезные проблемы с переносимостью С начинаются в области IPC, параллельных процессов и GUI-интерфейсов. Вопросы переносимости IPC и параллельных процессов обсуждались в главе 7. Реальную практическую проблему создают GUI-инструментарии. Большое количество GUI-инструментариев с открытым исходным кодом универсально переносятся между современными вариантами Unix, а также в Windows и классическую MacOS — Tk, wxWindows, GTK и Qt — четыре хорошо известных вида инструментария с открытым исходным кодом и документацией, которую нетрудной найти в Web. Однако ни один из них не распространяется со всеми платформами, и (по причинам более юридическим, чем техническим) ни один из них не предоставляет на всех платформах естественный вид и восприятие GUI-интерфейса. В главе 15 даны некоторые рекомендации, позволяющие справиться с данной проблемой. По теме разработки переносимого C-кода написаны целые тома. Эта книга не входит в их число, и авторы рекомендуют внимательно изучить "Recommended С Style and Coding Standards" [11], а также главу о переносимости из книги "The Practice of Programming" [40]. 17.5.1.2. Переносимость С++Для С++ на уровне операционной системы характерны те же проблемы переносимости, что и для С, а также ряд собственных. Одной из дополнительных проблем является то, что GNU компилятор с открытым исходным кодом для С++ значительно отстает от коммерческих реализаций; поэтому к середине 2003 года не существовало универсально внедряемого эквивалента GNU С, на котором можно основывать стандарт де-факто. Более того, ни один из компиляторов С++ не реализовывает полностью ISO-стандарт C++99, хотя GNU С++ подошел к этому очень близко. 17.5.1.3. Переносимость shellПереносимость shell-сценариев, к сожалению, является низкой. Проблема заключается не в самой оболочке; bash(1) (Bourne Again shell с открытым исходным кодом) распространена достаточно широко, для того чтобы малоразвитые shell-сценарии могли выполняться почти в любой среде. Проблема заключается в том, что в большинстве shell-сценариев интенсивно используются другие команды и фильтры, которые являются менее переносимыми, и их присутствие на какой-либо определенной целевой машине никоим образом не гарантируется. Данную проблему можно преодолеть героическими усилиями, как в инструментах autoconf(1). Однако это действительно достаточно трудно, и большинство сложнейших случаев программирования, которые обычно реализовались в shell, переместились к языкам сценариев второго поколения, таким как Perl, Python и Tcl. 17.5.1.4. Переносимость PerlPerl отличается хорошей переносимостью. В стандартном варианте языка даже предоставляется переносимый набор привязок к Tk-инструментарию, который поддерживает переносимые GUI-интерфейсы в Unix, MacOS и Windows. Однако этому мешает одна проблема. Perl-сценарии часто требуют добавочных библиотек из архива CPAN (Comprehensive Perl Archive Network — полный сетевой архив Perl), которые не обязательно присутствуют в любой реализации Perl. 17.5.1.5. Переносимость PythonPython имеет превосходную переносимость. Как и Perl, стандартный вариант Python предоставляет переносимый набор привязок к Tk-инструментарию, который поддерживает переносимые GUI-интерфейсы в Unix, MacOS и Windows. Стандартный Python обладает более развитой стандартной библиотекой, чем Perl и не имеет эквивалента архиву CPAN, на который могли бы полагаться программисты. Вместо этого важные модули расширения регулярно встраиваются в стандартный дистрибутив Python в ходе выпуска второстепенных версий. Это заменяет пространственную проблему временной — Python менее подвержен влиянию эффекта недостающих модулей. За это приходится расплачиваться тем, что второстепенные версии Python отчасти более важны, чем главные версии Perl. На практике этот компромисс благоприятствует Python. 17.5.1.6. Переносимость TclTcl демонстрирует хорошую переносимость в целом, но она сильно различается в зависимости от сложности проекта. Tk-инструментарий для кроссплатформенного GUI-программирования является естественным для Tcl. Как и в случае с Python, развитие основного языка проходит относительно гладко с немногими проблемами перекоса версий. К сожалению, Tcl даже более, чем Perl, зависит от средств расширения, которые не обязательно поставляются с каждой реализацией языка, а кроме того, не существует эквивалента CPAN-архива для централизованного их распространения. Таким образом, для мелких проектов, не зависящих от расширений, переносимость Tcl превосходна. Однако крупные проекты часто сильно зависят как от расширений, так и (как в случае с shell-программированием) от вызываемых внешних команд, которые могут отсутствовать на целевой машине; часто они имеют слабую переносимость. Парадоксально, но Tcl может страдать от простоты добавления в него расширений. К тому моменту, когда определенное расширение становится интересным в качестве части стандартного дистрибутива, существует, как правило, несколько различных его версий. На симпозиуме разработчиков Tcl/Tk (Tcl/Tk Workshop 1995 года) Джон Аустерхоут (John Ousterhout) объяснил, почему в стандартном дистрибутиве Tcl отсутствует поддержка ОО-средств, так:
17.5.1.7. Переносимость JavaПереносимость Java превосходна — в конце концов, основной целью создания языка был девиз "написанное однажды работает везде". Вместе с тем переносимость Java не идеальна. Трудности в основном связаны с проблемами перекоса версий между JDK 1.1 и более старым GUI-инструментарием AWT (с одной стороны) и JDK 1.2 и более новым Swing. Это обусловлено несколькими важными причинами. • Конструкция AWT Sun была настолько неадекватной, что ее необходимо было заменить инструментарием Swing. • Отказ Microsoft от поддержки Java-разработки на Windows и попытка заменить данный язык С#. • Решение Microsoft удерживать поддержку аплетов в Internet Explorer на уровне JDK 1.1. • Лицензионные положения Sun, которые делают невозможной реализацию JDK 1.2 с открытым исходным кодом, замедляя внедрение пакета (особенно в мире Linux). Разрабатывая программы, в которых задействованы GUI-интерфейсы, Java-разработчики, ищущие переносимости, в обозримом будущем окажутся перед лицом выбора: для сохранения максимальной переносимости (включая Microsoft Windows) остановиться на JDK1.1/AWT со слабо спроектированным инструментарием или получить лучший инструментарий и средства JDK 1.2, жертвуя некоторой переносимостью. Наконец, как отмечалось выше, поддержка параллельных процессов в Java имеет проблемы переносимости. В отличие от менее претенциозных привязок к операционной системе для других языков, Java API действительно мог послужить в качестве моста между расходящимися моделями процессов, предоставляемыми различными операционными системами. Но это не решает проблему в полной мере. 17.5.1.8. Переносимость Emacs LispEmacs Lisp отлично переносится на разные платформы. Инсталляции Emacs обновляются часто, поэтому действительно устаревшие среды встречаются редко. Lisp одного расширения поддерживается везде, и фактически все расширения поставляются с самим Emacs. Кроме того, также весьма стабилен набор примитивов Emacs. Он достиг завершенности для задач, которые в течение многих лет возлагались на редактор (манипуляция буферами, обработка текста). Только введение системы X нарушило эту картину, и очень немногие режимы Emacs должны иметь сведения об X. Проблемы переносимости обычно являются проявлением капризов средств операционной системы на C-уровне привязок; управление подчиненными процессами в таких режимах в качестве почтовых агентов — почти единственная область, где такие проблемы проявляются с непредсказуемой частотой. 17.5.2. Обход системных зависимостейПосле выбора языка и библиотек поддержки следующим вопросом переносимости обычно является расположение ключевых системных файлов и каталогов: почтовых спулов, каталогов журнальных файлов и т.д. Прообразом данного типа проблем является то, где расположен каталог почтового спула — /var/spool/mailили /var/mail. Часто можно избежать этого вида зависимости, отступив и воссоздав проблему. Зачем, так или иначе, открывать файл в каталоге почтового спула? Если запись в него необходима, то, возможно, лучшим решением будет просто вызов локального почтового транспортного клиента, с тем чтобы блокировка файла была выполнена верно. Если выполняется чтение из почтового каталога, то, вероятно, лучше будет обратиться к нему посредством POP3- или IMАР-сервера. Подобные вопросы применимы и к другим системным файлам. Не лучше ли, например, вместо ручного открытия журнальных файлов воспользоваться средствами syslog(3). Интерфейсы вызова функций через библиотеку С стандартизированы лучше, чем расположение системных файлов, и этим следует пользоваться. Если параметры расположения системных файлов должны присутствовать в коде, то наилучшая альтернатива зависит от способа распространения дистрибутива: исходный код или бинарная форма. Если распространяется исходный код, то могут помочь инструменты autoconf, которые рассматриваются в следующем разделе. В случае распространения бинарных файлов хорошей практикой будет заставить программу получать начальные параметры системы и выяснять, возможно ли автоматически настроиться на локальные условия, например, путем проверки существования каталогов /var/mailи /var/spool/mail. 17.5.3. Инструменты, обеспечивающие переносимостьЧасто для разрешения вопросов переносимости, обследования системной конфигурации и настройки make-файлов можно использовать GNU-утилиту с открытым исходным кодом autoconf(1), которая рассматривалась в главе 15. Пользователи, которые сегодня предпочитают компилировать программы из исходного кода, рассчитывают на возможность ввести команды configure; make; make installи получить чистую сборку. На странице <http://seul.org/docs/autotut/> публикуется хорошее учебное пособие по использованию данных инструментов. Даже если программа распространяется в бинарном виде, инструменты autoconf(1) способны помочь автоматизировать решение проблемы подстройки кода под условия различных платформ. Существуют другие инструменты, которые решают данную проблему. Двумя из наиболее широко известных средств являются утилита Imake(1), связанная с системой X Window и инструмент Configure, созданный Ларри Уоллом (Larry Wall, создавшим позднее язык Perl) и приспособленный для многих различных проектов. Все они, как минимум, также сложны как набор autoconf, и используются в настоящее время не чаще. Они не охватывают такой же широкий диапазон целевых систем как autoconf. 17.6. ИнтернационализацияДетальное рассмотрение интернационализации кода — разработки программы так, чтобы ее интерфейс легко вмещал в себя несколько языков и справлялся с причудами различных наборов символов — выходит за рамки тематики данной книги. Однако опыт Unix предлагает несколько уроков хорошей практики. Во-первых, рекомендуется разделять базу сообщений и код. Хорошая Unix-практика заключается в отделении строк сообщений, которые использует программа, от ее кода так, чтобы словари сообщений на других языках можно было подключать без модификации кода. Наиболее известным инструментом для решения данной задачи является GNU-утилита gettext, которая требует заключать в специальный макрос строки исходного языка, которые необходимо интернационализировать. Макрос использует каждую строку как ключ в словарях всех языков, которые могут поставляться в виде отдельных файлов. Если такие словари не доступны (или доступны, но в процессе поиска соответствие не было найдено), то макрос просто возвращает свой аргумент, безоговорочно отступая к собственному языку в коде. Несмотря на то, что сама по себе программа gettext к середине 2003 года являлась хрупкой и беспорядочно организованной, ее общая философия вполне логична. Для многих проектов вполне возможно создать легковесную версию данной идеи с хорошими результатами. Во-вторых, в современных Unix-системах прослеживается отчетливая тенденция избавляться от всего "исторического мусора", связанного с множеством таблиц символов, и делать естественным языком приложений UTF-8, 8-битовое кодирование Unicode-символов со смещением (в противоположность, например, использованию в качестве такого языка 16-битовые широкие символы). Нижние 128 символов UTF-8 представляют собой символы ASCII, а нижние 256 символов — Latin-1, что означает обратную совместимость с двумя наиболее широко используемыми таблицами символов. Этому способствует тот факт, что XML и Java сделали данный выбор, но движущая сила уже определена, даже если бы не было XML и Java. В-третьих, необходимо внимательно относиться к диапазонам символов в регулярных выражениях. Элемент [a-z]не обязательно охватывает все строчные буквы, если сценарий или программа разрабатывается, например, для Германии, где острая буква "s" или символ "ß" считается строчным, но не входит в данный диапазон. Подобные проблемы возникают с французскими буквами под ударением. Надежнее использовать элемент [[:lower:]]и другие символьные диапазоны, описанные в стандарте POSIX. 17.7. Переносимость, открытые стандарты и открытый исходный кодПереносимость требует стандартов. Эталонные реализации с открытым исходным кодом являются наиболее эффективным из известных методов, как для распространения стандарта, так и для того, чтобы вынудить коммерческих поставщиков согласиться со стандартом. Для разработчика реализация опубликованного стандарта в открытом исходном коде может одновременно сокращать объем работ по кодированию и позволяет создаваемому продукту извлечь преимущества (как ожидаемые, так и неожиданные) из труда других разработчиков. Рассмотрим, например, разработку программы захвата изображений для цифровой камеры. Зачем создавать собственный формат для сохранения изображений или покупать коммерческий код, когда (как было сказано в главе 5) существует многократно проверенная, полнофункциональная библиотека для записи PNG-изображений, реализованная в открытом исходном коде? Создание (или воссоздание) открытого исходного кода также оказало значительное влияние на процесс стандартизации. Несмотря на то, что это не является официальным требованием, IETF приблизительно с 1997 года все больше сопротивляется превращать в стандарты документы RFC, которые не имеют по крайней мере одной эталонной реализации с открытым исходным кодом. В будущем кажется вполне вероятным, что степень соответствия любому определенному стандарту будет все больше измеряться соответствием реализациям с открытым исходным кодом, которые были одобрены авторами стандарта.
В завершение следует подчеркнуть, что самый эффективный шаг, который можно предпринять для обеспечения переносимости разрабатываемого кода заключается в том, чтобы не полагаться на частную технологию. Не известно, когда закрытая библиотека, инструмент, генератор кода или сетевой протокол, от которого зависит программа, прекратит существование, или, когда интерфейс будет изменен каким-либо обратно несовместимым путем, который разрушит разрабатываемый проект. Используя открытый исходный код, можно обеспечить проекту будущее, даже если ведущая версия изменится так, что разрушит проект; ввиду того, что существует доступ к исходному коду, можно будет в случае необходимости перенести его на новую платформу. До конца 90-х годов данная рекомендация была бы невыполнимой. Несколько альтернатив частных операционных систем и средств разработки были "благородными экспериментами", подтверждениями академических идей или "игрушками". Но Internet изменил все. В середине 2003 года Linux и другие Unix-системы с открытым исходным кодом доказали свою стойкость как платформы для создания программного обеспечения промышленного качества. В настоящее время разработчики имеют лучшую альтернативу, чем зависимость от краткосрочных бизнес- решений, направленных на защиту чужой монополии. Применяйте защищенные конструкции — создавайте программы на основе открытого исходного кода и вы не попадете в безвыходное положение. 18Документация: объяснение кода в Web-сообществе
Первым применением Unix в 1971 году была платформа для компоновки документов — Bell Labs использовала ее для подготовки патентных документов в целях составления картотеки. Фотонабор, управляемый компьютером, все еще оставался тогда новой идеей, и на несколько лет после своего дебюта в 1973 году форматер, который создал Джо Оссана (Joe Ossana), troff(1), определил уровень техники. С тех пор сложные форматеры документов, программное обеспечение для набора, а также различные программы макетирования страниц занимают важное место в традициях Unix. Хотя troff(1) доказал свою удивительную долговечность, в Unix также поддерживается значительная работа в данной прикладной области. Сегодня Unix-разработчики и Unix-инструменты находятся на передовом рубеже далеко идущих перемен в практике создания документов, началом которой послужило появление World Wide Web. На уровне пользовательских представлений с середины 1990-х годов практика сообщества Unix быстро смещается в направлении идеи "все документы — HTML, все ссылки — URL". Более того, современные программы для просмотра справочной информации в Unix являются просто Web-браузерами, которые способны осуществлять синтаксический анализ определенных видов URL-адресов (например, URL "man:ls(1)" интерпретирует man-страницу ls(1) в HTML-страницу). Это облегчает проблемы, вызванные существованием множества различных форматов для главных документов, но не решает их полностью. Составители документов до сих пор вынуждены решать проблему выбора главного формата, который удовлетворит их специфические потребности. В данной главе рассматривается весьма неудачное разнообразие различных форматов документов и инструментов, которые остались позади за десятилетия экспериментов. Кроме того, в этой главе формулируются несколько определяющих правил хорошей практики и удачного стиля. 18.1. Концепции документацииВ первую очередь необходимо определить различия между WYSIWYG-программами (WYSIWYG, "What You See Is What You Get" — "что видишь, то и получаешь") и инструментами разметки (Markup-Centered Tools). Большинство настольных издательских программ и текстовых процессоров входят в первую категорию; они имеют GUI-интерфейсы, в которых вводимый пользователем текст вставляется непосредственно в экранное представление документа, которое задумано как наиболее точное подобие окончательной печатаемой версии. Напротив, в системе, ориентированной на разметку, документ обычно является простым текстовым документом, содержащим явные, видимые управляющие теги и вообще не имеет сходства с ожидаемой выходной версией. Размеченный исходный документ можно модифицировать с помощью обычного текстового редактора, но необходимо передать программе-форматеру, создающей визуализированный вывод для печати или отображения на экране. Визуальный интерфейс, или WYSIWYG-стиль, был чрезмерно затратным для ранних компьютеров и использовался редко вплоть до появления в 1984 году персонального компьютера Macintosh. В настоящее время этот стиль полностью доминирует в не-Unix операционных системах. С другой стороны, собственные инструменты форматирования документов в Unix почти все основаны на разметке. Unix-программа troff(1) 1971 года была форматером разметки и, вероятно, является старейшей из подобных программ, которая используется до сих пор. Инструменты разметки до сих пор играют значительную роль, поскольку имеющиеся реализации WYSIWYG часто приводят к различным сбоям — некоторые из них поверхностные, а некоторые глубокие. WYSIWYG-процессоры имеют одну общую проблему с GUI-интерфейсами, которая рассматривалась в главе 11. Тот факт, что пользователь может визуально манипулировать любым объектом, часто означает то, что пользователь должен управлять всем. Данная проблема осталась бы, даже если WYSIWIG-соответствие между экранным выводом и распечаткой было бы идеальным, но это почти всегда не так. В действительности WYSIWYG-процессоры не являются полностью WYSIWYG. Большинство из них имеют интерфейсы, скрывающие от пользователя различия между экранным представлением и выводом принтера, фактически не устраняя эти различия. Таким образом, нарушается правило наименьшей неожиданности: визуальный аспект подталкивает к использованию программы как печатной машинки, даже если она таковой не является, а входные данные время от времени приводят к неожиданному и нежелательному результату. Верно также и то, что WYSIWIG-системы фактически опираются на код разметки, но "делают все возможное", для того чтобы он стал невидимым при обычном использовании программы. Следовательно, нарушается правило прозрачности: пользователю не видна вся разметка, поэтому трудно привести в порядок документы, которые испорчены в результате несоответствующей разметки. Несмотря на свои проблемы, WYSIWYG-процессоры могут приносить пользу, если все потребности пользователя сводятся к перемещению картинки на обложке четырехстраничной брошюры вправо на три пункта. Однако они способны ограничивать пользователя всякий раз, когда необходимо внести глобальные изменения в макет 300-страничной рукописи. Пользователи WYSIWYG-процессоров, столкнувшиеся с данной проблемой, вынуждены сдаться или тысячи раз щелкать мышью. В подобных ситуациях действительно ничто не может заменить возможность редактирования явной разметки, и Unix-инструменты, ориентированные на разметку, предлагают лучшие решения. Сегодня в мире, находящемся под влиянием Web и XML, становится общепринятым разграничивать разметку представления и структурную разметку в документах. Первую составляют инструкции о том, как должен выглядеть документ, а вторую — инструкции о том, как он организован и что означает. Такое разграничение не было очевидно понятным или соблюдаемым в ранних Unix-инструментах, однако оно важно для понимания вынуждающих факторов проектирования, которые привели к их современным потомкам. Разметка уровня представления хранит всю информацию для форматирования (например, о желаемом расположении пустых мест и изменении шрифтов) в самом документе. В системах структурной разметки документ должен быть соединен с таблицей стилей (stylesheet), которая дает форматеру указания о том, как преобразовывать структурную разметку документа в физическую компоновку. Оба вида разметки, в конечном итоге, управляют внешним видом печатаемого или просматриваемого документа, однако структурная разметка делает это посредством еще одного уровня преобразования, которое оказывается необходимым, если требуется обеспечить хорошие результаты, как для печати документа, так и для его представления в Web-среде. Большинство систем разметки документов поддерживают макросредства. Макросы являются определяемыми пользователями командами, которые с помощью подстановки текста разворачиваются во встроенные запросы разметки. Обычно данные макросы добавляют в язык разметки структурные функции (такие как возможность объявлять заголовки разделов).
Наконец, следует отметить, что существует значительные различия между тем, что составители хотят сделать с небольшими документами (деловыми и личными письмами, брошюрами, бюллетенями), и тем, что они хотят делать с "крупными" документами (книгами, длинными статьями, техническими докладами и руководствами). В таких документах часто имеется более развитая структура, они часто составляются из частей, которые, возможно, требуется редактировать по отдельности, а кроме того, они нуждаются в автоматически генерируемых возможностях, таких как оглавления. Все это характерные особенности, которые поддерживают инструменты, ориентированные на разметку. 18.2. Стиль UnixСтиль документации в Unix (и инструментов для подготовки документов) имеет несколько технических и культурных особенностей, которые обособляют его от способа создания документации в других системах. Понимание данных характерных особенностей, во-первых, создаст основу для понимания того, почему программы и практические приемы выглядят именно так, и во-вторых, почему документация читается именно таким способом. 18.2.1. Склонность к большим документамСредства подготовки документов в Unix всегда были предназначены, главным образом, для разрешения трудностей, связанных с компоновкой крупных и сложных документов. Первоначально такими документами были патентные заявки и техническая документация. Позднее — научные и технические статьи и техническая документация всех видов. В результате большинство Unix-разработчиков научились ценить средства разметки документов. В отличие от PC-пользователей того времени, Unix-культура не была под впечатлением WYSIWYG текстовых процессоров, когда они стали широко доступными в конце 80-х годов и в начале 90-х годов прошлого века. Даже среди молодых современных Unix-хакеров достаточно необычно встретить того, кто действительно отдает предпочтение WYSIWYG-системам. Неприятие трудных для понимания двоичных форматов документов и особенно непонятных частных двоичных форматов также сыграло свою роль в отклонении WYSIWYG-инструментов. С другой стороны, Unix-программисты с энтузиазмом ухватились за PostScript (современный стандарт языка для управления графическими принтерами) как только документация на язык стала доступной. Данный стандарт точно вписывается в Unix-традиции узкоспециальных языков. Современные Unix-системы с открытым исходным кодом имеют превосходные инструменты для работы с форматами PostScript и PDF (Portable Document Format). Другим последствием этой истории является то, что Unix-инструменты для работы с документами часто имеют сравнительно слабую поддержку включения изображений, но хорошо поддерживают диаграммы, таблицы, графики и математические формулы, т.е. то, что часто требуется в технических документах. Привязанность Unix к системам разметки часто высмеивается как предубеждение или характерная черта замкнутых хакеров, но не является ни тем, ни другим. Так же как считающийся "примитивным" CLI-стиль, Unix во многих случаях лучше, чем GUI-интерфейсы, адаптируется к потребностям опытных пользователей, ориентированная на разметку конструкция таких инструментов, как troff(1), подходит для потребностей опытных компоновщиков документов лучше, чем WYSIWYG-программы. Уклон традиции Unix в сторону больших документов не только привязывает разработчиков к форматерам на основе разметки, подобным troff, но также и заинтересовывает их в использовании структурной разметки. История развития документирующих средств Unix является историей прерывистого, запутанного и непостоянного движения в общем направлении от разметки уровня представления к структурной разметке. В середине 2003 года данная миграция все еще не была закончена, но ее конец близок Развитие World Wide Web означало, что способность отображать документы в различных средах (или, по крайней мере, печатать и отображать HTML-документы) стало после 1993 года главной задачей для инструментов документирования. В то же время даже обычные пользователи под влиянием HTML более комфортно стали воспринимать системы, ориентированные на разметку. Это привело непосредственно к росту заинтересованности в структурной разметке и изобретению XML после 1996 года. Внезапно давняя склонность Unix к системам разметки стала восприниматься скорее как перспективная, нежели реакционная. Сегодня для Unix характерна наиболее передовая разработка основанных на XML средствах документирования с использованием структурной разметки. Но в то же время Unix-культура еще должна освободиться от прежней традиции систем разметки уровня представления. "Скрипучий, лязгающий, бронированный динозавр", каковым является troff, только частично был вытеснен языками HTML и XML. 18.2.2. Культурный стильБольшая часть документации по программному обеспечению написана "техническими писателями", стремящимися найти наименьший общий знаменатель незнания — "умное написание для неосведомленных". Документация, которая поставляется с Unix-системами, традиционно пишется программистами для коллег. Даже если документация не написана программистами для программистов, то она часто находится под влиянием стиля и формата огромной массы такой документации, поставляемой с Unix-системами. Данные различия можно объединить одним замечанием: man-страницы в Unix обычно содержат раздел, который называется "BUGS" (ошибки). В других культурах "технические писатели" пытаются придать продукту лучший вид, минуя известные ошибки или касаясь их вскользь. В культуре операционной системы Unix разработчики беспощадно описывают известные недостатки своего программного обеспечения, а пользователи рассматривают краткий, но информативный раздел "BUGS" как обнадеживающий знак качественной работы. Коммерческие дистрибутивы Unix, нарушившие данное соглашение, либо исключив раздел "BUGS", либо заменив его название более мягкими формулировками "LIMITATIONS" (ограничения) или "ISSUES" (проблемы), или "APPLICATION USAGE" (использование приложения), неизменно приходят в упадок. Тогда как большая часть остальной программной документации часто колеблется между "непонятностью" и чрезмерно упрощенным, снисходительным изложением, классическая Unix-документация пишется в сжатом стиле, но вместе с тем является полной. Она "не ведет читателя за руку", а обычно указывает верное направление. Данный стиль предполагает активное чтение, при котором читатель способен сделать очевидный, но не высказанный вывод, на основе написанного и обладает достаточной уверенностью, чтобы доверять своим заключениям. Unix-программисты склонны хорошо писать справочники, и большинство документации в Unix имеют вид справочников или памяток для тех, кто думает подобно создателю документа, но еще не является экспертом в данном программном обеспечении. Результаты часто выглядят гораздо более загадочными и редкими, чем являются в действительности. Каждое слово документации необходимо читать очень внимательно, поскольку все, что необходимо знать, в ней, вероятно, имеется, а недостающие выводы можно сделать самостоятельно. Необходимо вдумчиво читать каждое слово, так как сведения редко повторяются дважды. 18.3. Многообразие форматов документации в UnixВсе основные форматы Unix-документации, кроме самых новых, являются разметками уровня представления, созданными с помощью макропакетов. Ниже они рассматриваются в порядке их возникновения. 18.3.1. troff и инструментарий Documenter's WorkbenchСтруктура и инструменты Documenter's Workbench рассматривались в главе 8 как пример интеграции системы, состоящей из нескольких мини-языков. Здесь рассматривается функциональная роль данного инструментария как системы форматирования документов. Форматер troff интерпретирует язык разметки уровня представления. Последние реализации данной программы, такие как GNU-проект groff(1), по умолчанию на выходе создают PostScript-представление, хотя существует возможность получать другие формы вывода путем выбора подходящего драйвера. В примере 18.1 приводится несколько troff-кодов, которые можно встретить в исходных текстах документов. troff(1) имеет множество других запросов, но большинство из них вряд ли можно увидеть немедленно. Весьма немногие документы написаны на чистом troff. Он поддерживает макросредства, и в нем более или менее широко используются около десятка макропакетов. Среди них наибольшее распространение получил макропакет man(7), который используется для написания man-страниц Unix. См. пример 18.2. Две из почти десяти исторических библиотек макросов troff, ms(7) и mm(7) используются до сих пор. В BSD Unix имеется собственный замысловатый расширенный набор макросов, mdoc(7). Все они предназначены для написания технических руководств и длинных документов. Они имеют подобный стиль, но более сложны, чем man-макросы, и ориентированы на создание форматированного вывода. Сокращенный вариант troff(1), который называется nroff(1), генерирует вывод для устройств, поддерживающих только моноширинные шрифты, например, для построчно-печатающих устройств и символьных терминалов. Отображаемая для пользователя внутри терминального окна man-страница Unix форматируется с помощью nroff. Пример 18.1. Разметка groff(1)Это непрерывный текст. .\" Комментарии начинаются с обратной косой черты и двойных кавычек. .ft В Данный текст будет выделен жирным шрифтом. .ft R Данный текст будет выведен снова стандартным шрифтом (Roman). Данные строки снова, как и "Это непрерывный текст", будут отформатированы как заполненный абзац. .bp Запрос bp приводит к созданию новой страницы и разрыву абзаца. Эта строка будет частью второго заполненного абзаца. .sp 3 Запрос .sp выводит заданное аргументом количество пустых строк, .nf Запрос nf отключает заполнение абзаца. До тех пор, пока оно снова не будет включено запросом fi, пустые места и макет страницы будут сохраняться. Одно слово данной строки будет выделено \fBbold\fR жирным шрифтом. .fi Снова включено заполнение абзаца. Средства инструментария Documenter's Workbench очень хорошо решают задачи по форматированию технических документов, для которых они и предназначены, именно поэтому они непрерывно используются в течение более чем 30 лет, тогда как производительность компьютеров возросла в тысячи раз. Они создают форматированный текст приемлемого качества на графических принтерах и способны корректно отображать форматированные man-страницы на экране. Однако в некоторых областях они плохо применимы. Их стандартный выбор доступных шрифтов ограничен. Они слабо обрабатывают изображения. Сложно обеспечить точное управление позиционированием текста, изображений или диаграмм внутри страницы. Поддержка многоязычных документов отсутствует. Существует множество других проблем. Некоторые из них хронические, но незначительные, другие абсолютно затрудняют специфическое применение. Но наиболее серьезная причина заключается в том, что, ввиду того, что большая часть разметки осуществляется на уровне представления, создавать хорошие Web-страницы из немодифицированных troff-текстов очень трудно. Тем не менее, на момент написания книги man-страницы остаются единственной наиболее важной формой Unix-документации. Пример 18.2. Разметка man-страниц.SH ПРИМЕР РАЗДЕЛА Макрос SH начинает раздел, выделяя его заголовок жирным шрифтом. .Р Запрос Р начинает новый абзац. Запрос I форматирует свой аргумент .I курсивом. .IP * Данный запрос начинает абзац с отступом, отмеченным звездочкой. Дополнительный текст для первого абзаца списка. .TP Эта первая строка станет меткой абзаца Данная строка будет первой строкой в абзаце, с отступом по отношению к метке. Пустая строка выше интерпретируется почти так же, как разрыв абзаца (фактически как troff-запрос .sp 1). .SS Подраздел Это текст подраздела. 18.3.2. TEXTEX (произносится как "теХ") представляет собой очень мощную программу подготовки документов, которая, подобно редактору Emacs, возникла за пределами Unix-культуры, но теперь "прижилась" в ней. Она была создана видным компьютерным ученым Дональдом Кнуттом (Donald Knuth), когда ему надоело качество доступной в конце 70-х годов прошлого века типографской разметки текста и особенно форматирования математических выражений. TEX, подобно утилите troff(1), является системой, ориентированной на разметку. TEX имеет гораздо более мощный язык запросов, чем troff. Среди прочего, данная программа лучше приспособлена для обработки изображений, точного позиционирования содержимого страницы и интернационализации. особенно хорошо проявляет себя в форматировании математических выражений и является непревзойденным инструментом для решения базовых задач форматирования, таких как кернинг, заполнение строк и расстановка переносов. ТEХ стал стандартным форматом для представления материалов в большинство математических журналов. В настоящее время TEX курируется как программа с открытым исходным кодом рабочей группой Американского математического общества (American Mathematical Society). Программа также широко используется для создания научных документов. Как и в случае с troff(1), пользователь обычно не пишет вручную множество чистых TEX-макросов. Вместо этого используются макро-пакеты и различные вспомогательные программы. Один особый макропакет, TEX является почти универсальным, и большинство пользователей, которые говорят о том, что создают документы в TEX, почти всегда фактически имеют в виду написание LATEX-макросов. Как и макропакеты troff, множество запросов LATEX являются полуструктурными. Одно важное применение TEX, которое обычно скрыто от пользователя, заключается в том, что другие инструменты обработки документов часто генерируют LATEX-код, преобразуемый впоследствии в PostScript, вместо того, чтобы самостоятельно пытаться выполнять гораздо более трудную работу по созданию PostScript-документа. Такой прием используется в управляющем сценарии xmlto(1), который рассматривался в главе 14 в качестве учебного примера shell-программирования. Аналогично данная проблема решается в инструментарии XML-DocBook, который описывается ниже в настоящей главе. TEX имеет более широкий диапазон применений, чем troff(1), и в основном лучшую конструкцию. Во все более связанном с Web мире рассматриваемая программа имеет те же фундаментальные проблемы, что и troff. Ее разметка сильно привязана к уровню представления, и автоматическое создание хороших Web-страниц из исходных текстов TEX затруднено и чревато сбоями. Программа TEX никогда не используется для создания Unix-документации и только иногда используется для документирования приложений. Для таких целей достаточно использовать troff. Однако некоторые программные пакеты, которые возникли в академических учреждениях за пределами Unix-сообщества, заимствовали использование TEX как главного формата документации; одним из примеров является язык Python. Как было сказано выше, он также интенсивно используется для создания математических и научных документов и, вероятно, будет доминировать в этой нише еще несколько лет. 18.3.3. TexinfoTexinfo — разметка документации, разработанная Фондом свободного программного обеспечения. Она используется главным образом для документирования GNU-проектов, включая создание документации для таких важнейших инструментов, как Emacs и коллекция GNU-компиляторов. Texinfo была первой системой разметки, специально предназначенной для поддержки вывода форматированного текста на бумагу и гипертекстового вывода для просмотра на экране. Однако используемым в ней гипертекстовым форматом был не HTML, а более примитивная разновидность, которая называется "info", первоначально предназначенная для просмотра из Emacs. Для печати документов Texinfo преобразуется в TEX-макрос, а затем из него в PostScript-представление. Texinfo-инструменты в настоящее время способны генерировать HTML-документы. Однако качество и полнота данной операции оставляют желать лучшего, а поскольку множество Texinfo-разметки находится на уровне представления, вряд ли эта ситуация улучшится. В середине 2003 года Фонд свободного программного обеспечения еще продолжал работу над эвристическим преобразованием Texinfo в DocBook. Вероятно, формат Texinfo на какое-то время сохранится. 18.3.4. PODPOD или Plain Old Documentation (простая старая документация) представляет собой систему разметки, применяемую кураторами проекта Perl. Данная система генерирует страницы руководства и имеет все известные проблемы разметок уровня представления, включая проблемы при создании хороших HTML-документов. 18.3.5. HTMLС момента широкого распространения World Wide Web в начале 90-х годов прошлого века документация небольшой, но возрастающей части Unix-проектов пишется непосредственно на HTML. Проблема данного подхода заключается в том, что генерировать из HTML высококачественный типографский вывод трудно. Кроме того, существуют определенные проблемы с индексированием; необходимая для создания индексов информация в HTML отсутствует. 18.3.6. DocBookDocBook представляет собой определение типов SGML- и XML-документов, предназначенное для крупных, сложных технических документов. Данный формат является единственным исключительно структурированным среди форматов разметки, используемых в Unix-сообществе. Инструмент xmlto(1), описанный в главе 14, поддерживает преобразование в HTML, XHTML, PostScript, PDF, разметку справочной системы Windows и несколько менее важных форматов. Несколько главных проектов с открытым исходным кодом (включая Linux Documentation Project, FreeBSD, Apache, Samba, GNOME и KDE) уже используют DocBook в качестве главного формата. Данная книга была написана в XML-DocBook. Изучение DocBook — большая тема. Ее рассмотрение будет продолжено после обобщения проблем, связанных с современным состоянием подготовки документов в Unix. 18.4. Современный хаос и возможный выход из положенияВ настоящее время Unix-документация является "неорганизованной смесью". Главные файлы документации в современных Unix-системах разбросаны по восьми различным форматам разметки: man, ms, mm, TEX, Texinfo, POD, HTML и DocBook. He существует унифицированного способа просматривать все сформированные версии. Они не доступны в Web и не снабжены перекрестными ссылками. Многие представители Unix-сообщества осознают данную проблему. Во время написания данной книги большинство усилий, направленных на ее разрешение, исходит от разработчиков открытого исходного кода, которые более активно заинтересованы в конкуренции за предпочтения нетехнических конечных пользователей, чем разработчики частных Unix-систем. С 2000 года практика движется в направлении использования XML-DocBook как формата обмена документацией. Ясная, но требующая больших усилий для достижения цель заключается в том, чтобы снабдить каждую Unix-систему программным обеспечением, которые будет функционировать как общесистемный реестр документации. Когда системные администраторы устанавливают пакеты, одним из этапов будет ввод в данный реестр XML-DocBook-документации для этих пакетов. Затем документация будет преобразована в общедоступное дерево HTML-документов и снабжена перекрестными ссылками с уже имеющейся документацией. Ранние версии программ регистрации документов уже работают. Проблема преобразования других форматов в XML-DocBook является большой и запутанной, однако инструменты преобразования появляются в поле зрения. Другие политические и технические проблемы остаются нерешенными, однако их можно решить. Несмотря на то, что к середине 2003 года сообщество в целом не пришло к общему мнению о том, что более старые форматы необходимо постепенно прекратить использовать, это событие кажется самым вероятным. Соответственно, далее формат DocBook и соответствующий инструментарий рассматривается более подробно. Данное описание следует читать как введение в XML в контексте Unix, практическое руководство для применения и как основной учебный пример. Оно является хорошим примером того, как в контексте сообщества Unix, вокруг общих стандартов развивается взаимодействие между различными проектными группами разработчиков. 18.5. DocBookБольшое количество главных проектов с открытым исходным кодом сходятся в том, что DocBook является стандартным форматом их документации. Сторонники разметки, основанной на XML, видимо, выиграли теоретический спор против разметки уровня представления и в пользу разметки структурного уровня, а эффективный XML-DocBook-инструментарий доступен в виде программ с открытым исходным кодом. Тем не менее, DocBook и программы, поддерживающие данный формат, окружает большая неразбериха. Его приверженцы используют непонятный и неприступный даже с точки зрения стандартов компьютерной науки жаргон, привязанный к аббревиатурам, которые не имеют очевидной связи с тем, что необходимо сделать для написания разметки и создания из нее HTML- или PostScript-представления. XML-стандарты и технические документы печально известны своей невразумительностью. В оставшейся части данного раздела предпринимается попытка прояснить жаргон. 18.5.1. Определения типов документов(Необходимо отметить: для того чтобы сохранить простоту изложения, большая часть данного раздела содержит несколько искаженные сведения, т.е. опускается большая часть истории. Справедливость будет полностью восстановлена в последующем разделе.) DocBook является языком разметки структурного уровня, а именно диалектом XML. DocBook-документ представляет собой блок XML-кода, в котором используются XML-теги для структурной разметки. Форматеру для применения к документу таблицы стилей и придания ему соответствующего внешнего вида требуется сведения об общей структуре данного документа. Например, для того чтобы соответствующим образом физически отформатировать заголовки глав, необходимо сообщить форматеру о том, что рукопись книги обычно состоит из титульных элементов, последовательности глав и выходных данных. Для того чтобы сообщить эти сведения, необходимо предоставить форматеру определение типа документа (Document Type Definition — DTD). DTD сообщает форматеру о том, какие элементы могут содержаться в структуре документа и в каком порядке они могут появляться. Называя DocBook "диалектом" XML, автор фактически имел в виду, что DocBook является DTD, причем довольно большим DTD, содержащим около 400 тегов[147]. В тени DocBook работает определенный вид программ, который называется анализатором корректности (validating parser). Первым этапом при форматировании DocBook-документа является его обработка анализатором корректности (клиентская часть DocBook-форматера). Данная программа сравнивает документ с DocBook DTD, для того чтобы гарантировать, что пользователь не нарушает структурных правил DTD (в противном случае серверная часть форматера, т.е. та часть, которая применяет таблицу стилей, может быть поставлена в тупик). Анализатор корректности либо перехватывает ошибку, отправляя пользователю сообщение о тех местах, где структура документа нарушена, либо транслирует документ в поток XML-элементов и текста, которые будут скомбинированы сервером с информацией из таблицы стилей для создания отформатированного вывода. Данный процесс в целом схематически изображен на рис. 18.1. 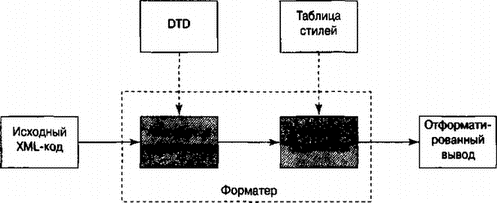 Рис. 18.1. Обработка структурированных документов Часть диаграммы внутри пунктирного блока соответствует форматирующему программному обеспечению или инструментальной связке (toolchain). Для того чтобы понять процесс, необходимо кроме очевидного и видимого ввода данных в форматер (исходного текста документа) учитывать два вида скрытого ввода форматера (DTD и таблица стилей). 18.5.2. Другие DTD-определенияНебольшое отступление к другим DTD-определениям поможет прояснить, какие сведения предыдущего раздела являются специфичными для DocBook, а какие являются общими для всех языков структурированной разметки. TEI (Text Encoding Initiative, <http://www.tei-c.org/>)— крупное, сложное DTD-определение, которое используется главным образом в академических учреждениях для компьютерной перезаписи литературных текстов. Применяемые в TEI связки Unix-инструментов состоят из множества тех же инструментов, которые задействованы в DocBook, но используются другие таблицы стилей и (естественно) другое DTD-определение. XHTML, последняя версия HTML, также является XML-приложением, описанным DTD, что объясняет "родовое сходство" между XHTML- и DocBook-тегами. Инструментальная связка XHTML состоит из Web-браузеров, которые способны форматировать HTML как простой ASCII-текст, а также любого количества узкоспециальных утилит для печати HTML-текста. Для того чтобы облегчить обмен структурированной информацией в других областях, таких как биоинформатика и банковское дело, поддерживаются также многие другие XML DTD-определения. Для того чтобы получить представление о доступном многообразии DTD-определений, можно воспользоваться списком репозитариев <http://www.xml.com/pub/rg/DTD_Repositories>. 18.5.3. Инструментальная связка DocBookОбычно для создания XHTML-документа из исходного DocBook-текета используется интерфейсный сценарий xmlto(1). Ниже приводятся примерные команды. bash$ xmlto xhtml foo.xml bash$ ls *.html ar01s02.html ar01s03.html ar01s04.html index.html В данном примере XML-DocBook-документ с именем fоо.xml, содержащий три раздела верхнего уровня, преобразовывается в индексную страницу и три части. Также просто создать одну большую страницу. bash$ xmlto xhtml-nochunks foo.xml bash$ ls *.html foo.html Наконец, ниже приводятся команды для создания PostScript-представления для печати. bash$ xmlto ps foo.xml # Создание PostScript bash$ ls *.ps foo.ps Для того чтобы превратить существующие документы в HTML или PostScript, необходимо ядро, которое способно применить к данным документам комбинацию DocBook DTD и подходящей таблицы стилей. На рис. 18.2 показано, как для данной цели совместно используются инструменты с открытым исходным кодом. 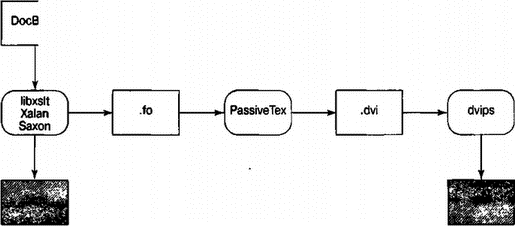 Рис. 18.2. Современная инструментальная связка XML-DocBook Синтаксический анализ документа и его трансформация на основе таблицы стилей будет осуществляться одной из трех программ. Вероятнее всего, программой xsltproc, которая представляет собой синтаксический анализатор, поставляемый с Red Hat Linux. Два другие варианта представлены Java-программами Saxon и Xalan. Сгенерировать высококачественный XHTML-документ из любого DocBook-текста сравнительно просто. Большую роль в данном случае играет тот факт, что XHTML является просто другим XML DTD-определением. Преобразование в HTML-документ осуществляется путем применения довольно простой таблицы стилей. Данный способ позволяет также просто генерировать RTF-документы, а из XHTML или RTF легко создать простой ASCII-текст. Сложный случай представляет собой печать. Создание высококачественного распечатываемого вывода, что на практике означает преобразование в формат Adobe PDF (Portable Document Format), затруднено. Правильное решение данной задачи требует алгоритмического воспроизведения способа мышления наборщика (человека) при переходе от содержания к уровню представления. Таким образом, прежде всего, с помощью таблицы стилей структурированная разметка DocBook преобразовывается в другой диалект XML — FO (Formatting Objects — объекты форматирования). FO-разметка является ярко выраженной разметкой уровня представления. Ее можно представить как некоторый функциональный XML-эквивалент troff. Данную разметку необходимо преобразовывать в PostScript для упаковки в PDF. В инструментальной связке, поставляемой с Red Hat Linux, данная задача решается с помощью TEX-макропакета, который называется PassiveTeX. Данный макрос преобразовывает объекты форматирования, генерируемые xsltproc, в язык TEX Дональда Кнутта. Затем вывод TEX, называемый форматом DVI (DeVice Independent), преобразовывается в PDF. Сложная цепь XML, TEX-макрос, DVI, PDF — неуклюжая конструкция. Она "гремит, хрипит и имеет уродливые наросты". Шрифты являются значительной проблемой, поскольку XML, TEX и PDF имеют очень разные модели. Кроме того, серьезные трудности связаны с поддержкой интернационализации и локализации. Единственной привлекательной особенностью данной конструкции является то, что она работает. Изящным способом разрешения описываемой проблемы будет использование FOP, непосредственного преобразования FO в PostScript, разрабатываемого проектом Apache. С помощью FOP проблема интернационализации даже если и не будет решена полностью, то, по крайней мере, будет определена. XML-инструменты поддерживают Unicode на всем пути к FOP. Преобразование глифов Unicode в PostScript-шрифт является также исключительно проблемой FOP. Единственным недостатком данного подхода является то, что он пока не работает. В середине 2003 года FOP находился в незаконченной альфа-стадии. FOP-преобразование можно использовать, однако оно содержит множество "необработанных углов" и характеризуется недостатком функций. На рис. 18.3 иллюстрируется схема инструментальной связки FOP. 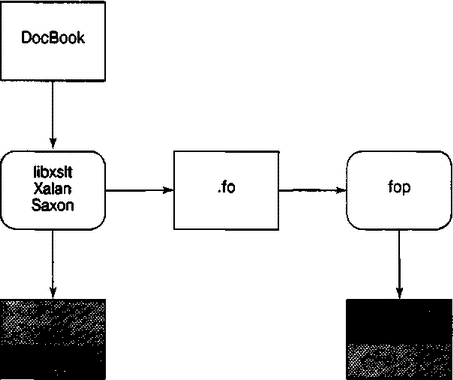 Рис. 18.3. Будущая инструментальная связка XML-DocBook с использованием FOP У FOP есть конкурент. Другой проект, который называется xsl-fo-proc, предназначен для решения тех же задач, что и FOP, но написан на С++ (и, следовательно, работает быстрее, чем Java, и не зависит от Java-окружения). В середине 2003 года проект xsl-fo-proc находился в незавершенной альфа-стадии и продвинулся не дальше, чем FOP. 18.5.4. Средства преобразованияВторая крупнейшая проблема, связанная с DocBook, состоит в необходимости преобразования старой разметки уровня представления в разметку DocBook. Человек обычно может автоматически преобразовать представление документа в логическую структуру, поскольку (например) из контекста можно понять, когда курсив означает "акцентирование мысли", а когда он означает что-нибудь другое, например, "иноязычный оборот". Так или иначе, при конвертировании документов в DocBook данные различия должны быть указаны явно. Иногда они присутствуют в старой разметке. Часто их нет, и отсутствующая структурная информация должна быть либо выведена с помощью развитой эвристики, либо задана человеком. Ниже приводится сводное описание инструментов преобразования из других форматов. Ни один из описанных ниже инструментов не выполняет данную работу идеально; после преобразования требуется проверка, а возможно, и некоторое редактирование со стороны человека. GNU Texinfo Фонд свободного программного обеспечения намеревается поддерживать DocBook как общий формат для обмена информацией. Texinfo имеет достаточную структуру для того, чтобы сделать возможным довольно точное автоматическое преобразование (после преобразования требуются немногочисленные исправления пользователем), а в версиях 4.x makeinfo представлен ключ --docbook, который генерирует DocBook-документ. Более подробная информация представлена на странице проекта makeinfo <http://www.gnu.org/directory/texinfo.html>. POD Модуль POD::DocBook, <http://www.cpan.org/modules/by-module/Pod/> преобразовывает разметку POD (Plain Old Documentation) в DocBook. Утверждается, что модуль преобразовывает каждый POD-тег, кроме курсивного тега L<>. На странице руководства также сказано: "Вложенные списки =over/=backвнутри DocBook не поддерживаются", однако, следует отметить, что модуль интенсивно тестируется. LATEX Проект, который называется TeX4ht, <http://www.lrz-muenchen.de/services/software/sonstiges/tex4ht/mn.html>, способен, по утверждению автора PassiveTEX, генерировать DocBook из LATEX. man-страницы и другая troff-разметка Как правило, считается, что преобразование таких документов представляет крупнейшую и труднейшую проблему. Действительно, базовая разметка troff(1) находится на слишком низком уровне представления для инструментов автоматического преобразования. Однако ситуация значительно прояснятся, если рассмотреть преобразование из исходных текстов документов, написанных в таких макропакетах, как man(7). Они имеют достаточно структурных элементов, для того чтобы улучшить автоматическое преобразование. Я сам написал инструмент для troff-DocBook преобразования, поскольку не находил другого, который выполнял бы такую работу с приемлемым качеством. Программа называется doclifter, <http://www.catb.org/~esr/doclifter/>. Она транслирует либо в SGML, либо в XML DocBook из макросов man(7), mdoc(7), ms(7) или me(7). Подробности описаны в документации. 18.5.5. Инструменты редактированияК середине 2003 года отсутствовал один компонент — хорошая программа с открытым исходным кодом для редактирования структуры SGML/XML-документов. LyX (<http://www.lyx.org/>) представляет собой текстовый процессор с графическим пользовательским интерфейсом, в котором для печати используется LATEX, а также поддерживается структурное редактирование LATEX-разметки. Существует LATEX-пакет, который генерирует DocBook, а также how-to-документ <http://bgu.chez.tiscali.fr/doc/db4lyx/>, описывающий методику написания SGML и XML в LyX GUI. GNU TeXMacs <http://www.math.u-psud.fr/~anh/TeXmacs/TeXmacs.html> — проект, направленный на создание хорошего редактора для технических и математических материалов, включая отображаемые формулы. Версия 1.0 была выпущена в апреле 2002 года. Разработчики планируют в будущем включить поддержку XML, но в настоящее время ее пока нет. Большинство пользователей до сих пор редактируют DocBook-теги вручную, используя vi или emacs. 18.5.6. Связанные стандарты и практические приемыДля редактирования и форматирования DocBook-разметки инструменты объединяются. Однако сам по себе формат DocBook является средством, а не целью. Кроме DocBook необходимы другие стандарты для достижения поставленной цели — базы данных документации с возможностью поиска. Существует два больших вопроса: каталогизация документов и метаданные. Непосредственно на достижение данной цели направлен проект ScrollKeeper <http://scrollkeeper.sourceforge.net/>. Данный проект предоставляет набор сценариев, которые могут использоваться в правилах инсталляции и деинсталляции пакетов для регистрации и удаления их документации. Программа ScrollKeeper использует открытый формат метаданных (Open Metadata Format) <http://www.ibiblio.org/osrt/omf/>. Данный формат является стандартом для индексирования документации по программам с открытым исходным кодом, аналогичный библиотечной карточно-каталоговой системе. Идея заключается в поддержке развитых средств поиска, в которых используются карточно-каталоговые метаданные, а также исходные тексты документации. 18.5.7. SGMLВ предыдущих разделах умышленно опускалась большая часть истории развития формата DocBook. Язык XML имеет "старшего брата", SGML (Standard Generalized Markup Language — стандартный обобщенный язык разметки). До середины 2002 года любая дискуссия о DocBook была бы неполной без длинного экскурса в SGML, объяснения различий между SGML и XML, а также подробного описания инструментальной связки SGML DocBook. Теперь все значительно проще. Инструментальная связка XML DocBook доступна в виде открытого исходного кода, работает так же, как работала связка SGML, и является более простой в использовании. 18.5.8. Справочные ресурсы по XML-DocBookОдним из факторов, который затрудняет изучение DocBook, является то, что сайты, связанные с данной темой, часто перегружают новичков длинными списками W3C-стандартов, массивными упражнениями по SGML-идеологии и абстрактной терминологией. Хорошее общее введение представляет собой книга "XML in a Nutshell" [32]. Книга Нормана Уолша (Norman Walsh) "DocBook: The Definitive Guide" доступна в печатном виде <http://www.oreilly.com/catalog/docbook/> и в Web — <http://www.docbook.org/tdg/en/html/docbook.html>. Книга представляет собой действительно полный справочник, но в качестве вводного курса или учебного пособия неудобна. Вместо нее рекомендуются материалы, перечисленные ниже. Написание документов с помощью DocBook (Writing Documents Using DocBook) <http://xml.Web.cern.ch/XML/goossens/dbatcern/> — превосходное учебное пособие. Существует также одинаково полезный список часто задаваемых вопросов (DocBook FAQ), <http://www.dpawson.co.uk/docbook/> с большим количеством материалов по форматированию HTML-вывода. Кроме того, функционирует DocBook-форум (DocBookwiki) <http://docbook.org/wiki/moin.cgi>. Наконец, в документе "The XML Cover Pages" <http://xml.coverpages.org/> представлены описания XML-стандартов. 18.6. Лучшие практические приемы написания Unix-документацииРекомендацию, данную в начале главы, можно рассмотреть с противоположной точки зрения. Создавая документацию для пользователей внутри Unix-культуры, не следует "оглуплять" ее. Автор документации, написанной для идиотов, сам будет "списан со счетов" как идиот. "Оглупление" документации резко отличается от создания доступной документации. В первом случае автор документации ленив и опускает важные сведения, тогда как во втором требуется глубокое осмысление и безжалостное редактирование. Не следует, однако, полагать, что объем является ошибкой с точки зрения качества. И что особенно важно — никогда не следует опускать функциональные детали, опасаясь, что они могут запутать читателя. Не стоит также опускать предупреждения об имеющихся проблемах, чтобы продукт не выглядел плохо. Именно неожиданные проблемы, а не проблемы, которые разработчик признает открыто, будут стоить ему доверия и пользователей. Пытайтесь найти золотую середину при подаче информации. Слишком малая насыщенность так же неудачна, как и слишком большая. Расчетливо используйте снимки с экранов; часто они несут мало информации, выходящей за рамки восприятия пользовательского интерфейса, и никогда полностью не заменят хорошего текстового описания. Если разрабатываемый проект имеет значительные размеры, следует, вероятно, поставлять документацию в трех видах: man-страницы в качестве справочного материала, учебный материал, а также список часто задаваемых вопросов (Frequently Asked Questions — FAQ). Также следует создать Web-сайт, который будет служить центральной точкой распространения продукта (основные принципы взаимодействия с другими разработчиками изложены в главе 19). Большие man-страницы несколько раздражают пользователей; навигация в них может быть затруднена. Если man-страницы получаются большими, следует рассмотреть возможность написания справочного руководства, а в man-страницах предоставить краткое обобщение и указатели на справочный материал, а также подробности вызова программы (или программ). В исходный код следует включать стандартные файлы метаинформации, такие как README, которые описаны в разделе главы 19, касающемся практических приемов выпуска программ с открытым исходным кодом. Даже если предполагается, что разрабатываемый код будет закрытым, эти файлы подчиняются соглашениям Unix и будущие кураторы, приходящие из Unix-среды, быстро вникнут в суть. man-страницы должны быть авторитетными справочниками в традиционном Unix-стиле для обычной Unix-аудитории. Учебные пособия должны быть документацией в развернутой форме для нетехнических пользователей. FAQ-списки должны быть развивающимися ресурсами, которые растут по мере того, как группа поддержки программы выясняет часто задаваемые вопросы и ответы на них. Существуют более специфические привычки, которые необходимо развить современному разработчику. 1. Поддержка главных документов в XML-DocBook. Даже тап-страницы могут быть документами DocBook RefEntry. Существует очень хорошее методическое руководство (HOWTO) <http://www.linux.doc.org/HOWTO/mini/Man-Page.html> по созданию man-страниц, в котором описана общая организация, ожидаемая пользователями. 2. Поставка документации с главными XML-файлами. На случай, если системы пользователей не имеют xmlto(1), поставляйте исходные тексты troff, которые можно получить, выполнив команду xmlto manнад главными документами. Процедура установки дистрибутива должна устанавливать их обычным способом, однако следует направить пользователей к XML-файлам, если они хотят создавать или редактировать документацию. 3. Создание ScrollKeeper-совместимого инсталляционного пакета проекта. 4. Создание XHTML-документов из главных документов (с помощью команды xmlto xhtml) и предоставление к ним доступа с Web-страницы проекта. Независимо от того используется ли в качестве главного формата XML-DocBook, необходимо найти способ конвертирования документации проекта в HTML. Независимо от того, как поставляется разрабатываемое программное обеспечение — как открытый исходный код или как частная программа, — растет вероятность того, что пользователи найдут ее посредством Web. Непосредственный эффект от размещения документации в Web-среде заключается в том, что это упрощает ее чтение и изучение для потенциальных пользователей и клиентов, знающих о существовании программы. Кроме того, возникает косвенный эффект — повышается вероятность появления программы в результатах Web-поиска. 19Открытый исходный код: программирование в новом Unix-сообществе
Глава 2 заканчивалась формулировкой самого значительного закона в истории Unix. Операционная система Unix "расцветала", когда ее практика наиболее близко приближалась к открытому исходному коду, и приходила в упадок, когда этого не было. Затем в главе 16 утверждалось, что инструменты разработки с открытым исходным кодом часто характеризуются высоким качеством исполнения. Данная глава начинается с общего объяснения того, как и почему действует разработка открытого исходного кода. Большая часть ее поведения является просто усилением общепринятых практических приемов в традиции Unix. Затем дискуссия выходит из области абстракции, и описываются некоторые из наиболее важных народных традиций, которые Unix заимствовала из сообщества открытого исходного кода, особенно развившиеся в сообществе основные правила относительно того, как должен выглядеть хороший код. Многие из данных традиций могут быть также успешно заимствованы разработчиками в других современных операционных системах. Данные традиции описываются в предположении, что читатели разрабатывают открытый исходный код. Большинство традиций представляют собой хорошие идеи даже при написании частного программного обеспечения. Предположение об открытом исходном коде является исторически целесообразным, поскольку многие из описываемых традиций через вездесущие инструменты с открытым исходным кодом, такие как patch(1), Emacs и GCC, "уходят корнями" в частные лаборатории разработки Unix. 19.1. Unix и открытый исходный кодВ разработке открытого исходного кода используется тот факт, что выяснение и исправление ошибок, в отличие от, например, реализации определенного алгоритма, является задачей, которая допускает ее разделение на несколько параллельных подзадач. Исследование совокупности возможностей, связанных с конструкцией прототипа, также может осуществляться параллельно. При наличии верного технологического и социального аппарата весьма крупные коллективы разработчиков, которые тесно связаны сетью, способны выполнять поразительно хорошую работу. Поразительно хорошей она является для тех людей, которые развили в себе ментальную привычку рассматривать секретность процесса и частный контроль как непременное условие. Со времени выхода книги "The Mythical Man-Month" [8] и до возникновения Linux ортодоксальными в программной инженерии были все мелкие, четко управляемые коллективы внутри тяжеловесных организаций, таких как корпорации и правительство. Чаще всего это были строго управляемые крупные коллективы. Раннее Unix-сообщество до лишения прав AT&T было образцовым примером открытого исходного кода в действии. Несмотря на то, что код операционной системы Unix до лишения прав AT&T был технически и юридически частным, он рассматривался как общая часть внутри сообщества пользователей и разработчиков. Добровольные усилия координировались людьми, наиболее сильно заинтересованными в решении проблем. Такая возможность выбора привела к возникновению многих полезных последствий. Действительно, методика разработки открытого исходного кода развивалась как неосознанная народная практика в Unix-сообществе более чем четверть века, за много лет до того, как она была проанализирована и получила свое название в конце 1990-х годов (см. "The Cathedral and the Bazaar" [67] и "Understanding Open Source Software Development" [18]). Оглядываясь в прошлое, поразительно отмечать, как все мы были склонны забывать последствия нашего поведения. Некоторые подошли весьма близко к пониманию данного феномена. Например, Ричард Габриель (Richard Gabriel) в своей статье "Worse Is Better" [25] в 1990 году, однако прообразы можно найти в книге Брукса [8] (1975 год) и еще более ранних размышлениях Виссотски (Vyssotsky) и Корбати (Corbaty) о конструкции Multics (1965 год). Мне не удавалось это сделать в течение более чем 20 лет наблюдения за разработкой программного обеспечения, пока меня в середине 1990-х годов "не разбудила" Linux. Этот опыт должен заставить любого вдумчивого и сдержанного человека заинтересоваться тем, какие другие важные унифицирующие концепции в нашем поведении до сих пор остаются неявными и проходят незамеченными нашим коллективным разумом, скрытые не из-за своей сложности, а из-за крайней простоты. Перечислим весьма простые правила разработки открытого исходного кода. 1. Пусть код будет открытым. Никаких секретов. Сделайте код и процесс его создания достоянием общественности. Поощряйте экспертную оценку третьей стороны. Убедитесь, что другие могут свободно модифицировать и распространять код. Выращивайте как можно большее сообщество разработчиков-соавторов. 2. Выпускайте первую версию быстро, выпускайте последующие версии часто. Быстрый темп выхода версий означает быструю и эффективную обратную связь. Когда каждая следующая версия является небольшой, изменение курса в ответ на отзывы реальных пользователей будет проще. Просто убедитесь, что первая версия программы компилируется, работает и демонстрирует перспективы. Обычно первоначальная версия программы с открытым исходным кодом демонстрирует перспективы, выполняя, по крайней мере, некоторую часть своей окончательной работы, достаточную для иллюстрации того, что разработчик может действительно продолжать работу над проектом. Например, первоначальная версия текстового процессора может поддерживать ввод текста и его отображение на экране. Первая версия, которую невозможно скомпилировать или использовать, может погубить проект (что, как известно, почти произошло с браузером Mozilla). Некомпилирующиеся версии наводят на мысль, что разработчики проекта не способны завершить его. Кроме того, неработающие программы усложняют сотрудничество для других разработчиков, поскольку сложно определить, улучшили ли программу какие-либо внесенные ими изменения. 3. Поощряйте сотрудничество похвалой. Если нет возможности материально вознаградить вносящих свой вклад разработчиков, поощряйте их морально. Даже если возможно наградить человека материально, помните, что люди часто для собственной репутации работают интенсивнее, чем работали бы за деньги.
Необходимо помнить, что причиной для частого выхода новых версий является необходимость сокращения и ускорения цикла обратной связи, который соединяет пользовательскую аудиторию с разработчиками. Следовательно, не следует думать о следующей версии, как о безупречном драгоценном камне, который нельзя показывать до тех пор, пока он не станет идеальным. Не следует создавать длинных перечней пожеланий. Делайте прогресс постепенным, признавайте текущие ошибки и объявляйте о них, и будьте уверены, что совершенство придет со временем. Согласитесь с тем, что придется выпустить десятки мелких версий, и не огорчайтесь, когда номера версий растут. В разработке открытого исходного кода задействованы большие коллективы программистов, рассеянных по всему миру и общающихся главным образом с помощью электронной почты и Web-страниц. Как правило, большинство соавторов в любом проекте являются добровольцами, вносящими свой вклад ради повышения полезности программы для них самих. Управляет проектом главный разработчик или центральная группа. Другие соавторы могут время от времени подключаться к проекту и выбывать из него. Для того чтобы поощрять соавторов-любителей, важно не допустить появления социальных барьеров между ними и основным коллективом. Необходимо минимизировать привилегированный статус основного коллектива и упорно работать над тем, чтобы сохранить границы незаметными. Проекты с открытым исходным кодом следуют традиционному для Unix-сообщества совету автоматизировать работу при любой возможности. Разработчики используют утилиту patch(1) для распространения последовательных изменений. Во многих проектах (и во всех крупных) имеются доступные по сети репозитории кода, использующие системы контроля версий, подобные CVS (эта тема подробно рассматривается в главе 15). Использование автоматизированных систем отслеживания ошибок и исправлений также является широко распространенной практикой. В 1997 году за пределами хакерской культуры почти никто не понимал, что таким способом можно разрабатывать крупные проекты, позволяя единицам добиваться высококачественных результатов. Проекты, подобные Linux, Apache и Mozilla, одновременно добились успеха и высокой общественной заинтересованности. Отказ от привычки к секретности в пользу прозрачности процесса и экспертной оценки, был ключевым этапом, который превратил "алхимию" в "химию". Также начали появляться признаки того, что разработка открытого исходного кода может сигнализировать о долгожданном формировании разработки программного обеспечения как дисциплины. 19.2. Лучшие практические приемы при взаимодействии с разработчиками открытого исходного кодаОсновной составляющей лучшей практики в сообществе открытого исходного кода является естественная адаптация к распределенной разработке. В оставшейся части данной главы представлены сведения о поведении, при котором поддерживается хорошая связь с другими разработчиками. Там, где соглашения Unix являются условными (такие как стандартные имена файлов, передающие метаинформацию об исходном дистрибутиве), часто прослеживается их происхождение либо из Usenet (начало 1980-х годов), либо из соглашений и стандартов проекта GNU. 19.2.1. Хорошая практика обмена исправлениямиБольшинство людей вовлекаются в создание программного обеспечения с открытым исходным кодом, создавая заплаты для чужих программ, прежде чем создают собственные проекты. Предположим, некто создал набор исправлений исходного кода для основной части чужой программы. Если встать на место разработчика программы, то каким образом можно решить, включать ли данную заплату или нет? Очень сложно судить о качестве кода, поэтому разработчики склонны оценивать исправления по качеству их подачи. Они анализируют ход мыслей в стиле подачи исправлений и манере общения лица, присылающего заплату. За много лет работы с заплатами, полученными от сотен незнакомых людей, автор данной книги редко встречал какое-либо исправление, которое было представлено продуманно, с уважением моего времени, но технически было нефункциональным. С другой стороны, опыт свидетельствует, что исправления, которые выглядят неаккуратными или небрежно и поспешно упакованными, скорее всего, являются неработоспособными. Ниже приводятся некоторые рекомендации для того, чтобы созданная вами заплата была принята. 19.2.1.1. Отправляйте заплаты, а не целые архивы или файлыЕсли изменения включают в себя новый файл, который отсутствует в коде, то, естественно, приходится отправлять данный файл целиком. Однако если изменяются только уже существующие файлы, отправлять их полностью не следует. Вместо этого следует отправить diff-файл, а именно вывод команды diff(1), выполненной для сравнения основной распространяемой версии с модифицированной. Команда diff(1) и обратная ей команда patch(1) являются основными инструментами разработки открытого исходного кода. Diff-файлы лучше, чем целые файлы, поскольку разработчик, которому отсылается заплата, мог изменить основной код с момента получения копии создателем заплаты. Отправляя разработчику diff-файл, создатель заплаты предотвращает дополнительную работу по разделению изменений, которую придется выполнить разработчику, и демонстрирует таким образом, что он ценит его время. 19.2.1.2. Отправляйте исправления к текущей версии кодаНе стоит отправлять куратору заплаты к коду, который существовал за несколько версий до этого, и ожидать, что он сделает всю работу по определению того, какие исправления дублируются с изменениями, уже внесенными им самим, а какие действительно являются новыми. Ответственность за отслеживание состояния исходного кода и отправку куратору минимальных заплат, которые выражают то, что их создатель хочет изменить в основном коде главной линии разработки, лежит на самом создателе заплаты. Это означает отправку исправлений к текущей версии. 19.2.1.3. Не следует включать заплаты для генерируемых файловПрежде чем отправить заплату, необходимо просмотреть ее и удалить все диапазоны кода, предназначенные для файлов, которые должны генерироваться автоматически после применения куратором исправлений и перекомпиляции программы. Классическим примером данной ошибки являются C-файлы, сгенерированные инструментами Bison или Flex. В настоящее время наиболее распространенной разновидностью данной ошибки является отправка diff-файлов с большим диапазоном, который не содержит ничего, кроме отличий между сценариями configureсоздателя заплаты и куратора. Такой файл создается с помощью autoconf. Такой подход является необдуманным и означает, что получатель будет вынужден отделять действительное содержание заплаты от большого количества шума. Данная ошибка незначительна, она не настолько важна, как некоторые из рассматриваемых далее, однако она не делает чести создателю заплаты. 19.2.1.4. Не отправляйте заплат, которые только убирают $-идентификаторы систем RCS или SCCSНекоторые разработчики вносят специальные метки в свои исходные файлы, распространяемые с помощью системы контроля версий, когда возвращают отредактированные файлы, например, конструкции $Id$, используемые в системах RCS и CVS. Если используется локальная система контроля версий, то изменения могут модифицировать данные метки. Это не представляет реальной опасности, поскольку когда получатель снова зарегистрирует исправленный код после применения заплаты, метки будут переназначены снова в соответствии с состоянием системы контроля версий куратора. Однако такие диапазоны исправлений являются излишними и отвлекают внимание. Лучше их не отправлять. Данная ошибка также является незначительной, и вас простят, если более важные изменения сделаны верно, однако ее следует в любом случае избегать. 19.2.1.5. Используйте вместо формата по умолчанию ( |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||