|
|||||||||||||||||||||||||||||||||||||||||
|
|
Глава 13. Управление Непрерывностью ИТ-сервисов13.1. ВведениеМногие руководители считают Процесс Управления Непрерывностью ИТ-сервисов (IT Service Continuity Management – ITSCM) роскошью, на которую у них нет средств. Однако, как показывает статистика, чрезвычайные ситуации стали часто встречающимся явлением.
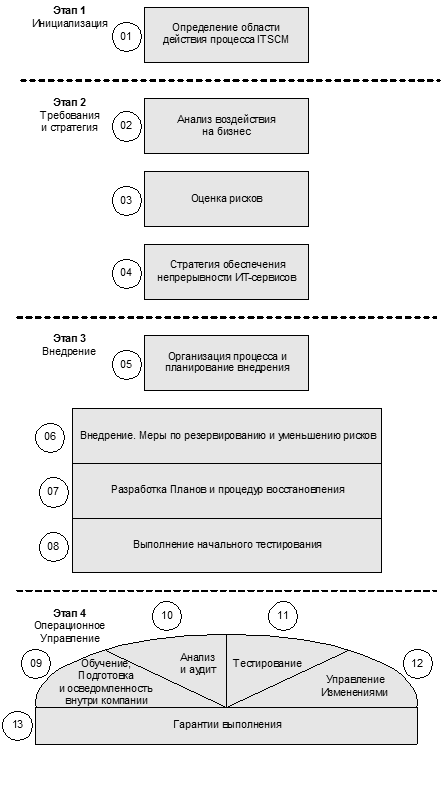
Как следует из данного определения, чрезвычайная ситуация намного серьезнее инцидента. Чрезвычайная ситуация – это приостановка бизнеса. Это означает, что весь бизнес или его часть будет находиться «вне бизнеса» после возникновения чрезвычайной ситуации. Известны такие примеры чрезвычайных ситуаций, как пожары, удары молнии, наводнения, кражи, вандализм и акты насилия, широкомасштабное нарушение электроснабжения и сбои в работе аппаратного обеспечения. Атаки террористов, например, нападение на Всемирный торговый центр в Нью-Йорке, становятся реальностью. Чрезвычайные ситуации возможны также и в Интернете, например, отказ сервиса (DoS)[210] может разрушить связь внутри всей организации. Некоторые организации могли бы предотвратить серьезные проблемы, если бы в свое время разработали План обеспечения непрерывности бизнеса. Бизнес все больше и больше зависит от ИТ-услуг, а это означает, что последствия потери сервиса становятся все более ощутимыми и все менее допустимыми. Фактически, сейчас во многих организациях ведение бизнеса эквивалентно использованию информационных технологий (ИТ), и без них бизнес едва ли будет существовать. Поэтому необходимо решать, как защитить непрерывность бизнеса. Со времени опубликования модуля Планирование на случай чрезвычайных обстоятельств (Contingency Planning Module) ассоциацией CCTA многое изменилось в области информационных технологий и в том, как они используются в организациях. Ранее это планирование касалось только ИТ. В настоящий момент информационные технологии уже значительно интегрированы во многие аспекты бизнеса. Если раньше традиционный процесс планирования непрерывности работы и восстановления функционирования в основном носил реактивный характер (что делать в случае возникновения чрезвычайной ситуации), то теперь Процесс Управления Непрерывностью ИТ-сервисов выполняет превентивную роль, т. е. работает над предотвращением катастроф. 13.2. Цель процессаЦель Процесса Управления Непрерывностью ИТ-сервисов — оказывать поддержку Процессу Управления Непрерывностью Бизнеса (Business Continuity Management – ВСМ). Такая поддержка означает, что необходимая инфраструктура и ИТ-услуги, включая службу поддержки и службу Service Desk, могут быть восстановлены за заданный период времени после возникновения чрезвычайной ситуации. У данного процесса может быть и ряд других целей. Поскольку процесс ITSCM является составной частью Процесса Управления Непрерывностью Бизнеса, сфера действия Процесса Управления Непрерывностью ИТ-сервисов (ITSCM) должна определяться, исходя из целей бизнеса. В результате при оценке рисков можно потом определить, попадают ли они в сферу действия данного процесса. Преимущества использования процесса[211] Поскольку бизнес во все большей степени зависит от ИТ-услуг, определить, во что может обойтись недостаточное планирование непрерывности предоставления ИТ-услуг и какие преимущества даст должное планирование этих вопросов, можно только с помощью анализа рисков. После того, как определен возможный риск для бизнеса, а не только для ИТ-сервиса, можно выделять средства для принятия превентивных мер и мер по борьбе с чрезвычайными ситуациями, например, разработка Плана восстановления после катастрофы. Если чрезвычайная ситуация все же произошла, то использование процесса ITSCM даст бизнесу следующие преимущества: • возможность управлять восстановлением своих систем; • уменьшить простои в работе; • свести к минимуму перерывы в ведении бизнеса. 13.3. ПроцессПроцесс Управления Непрерывностью ИТ-сервисов отвечает за: • оценку воздействия нарушений в работе ИТ-сервисов после возникновения чрезвычайной ситуации; • определение критичных для бизнеса сервисов, которые требуют дополнительных превентивных мер; • определение периода времени, в течение которого сервис должен быть восстановлен; • принятие мер по предотвращению, обнаружению, подготовке к чрезвычайным ситуациям или по уменьшению степени их воздействия; • определение общего подхода к восстановлению услуг; • разработку, тестирование и поддержку плана восстановления с достаточным Уровнем Детализации, который поможет пережить чрезвычайную ситуацию и восстановить нормальную работу за заданный период времени. Поскольку наблюдается все большее взаимопроникновение бизнес-операций и информационных технологий, то эти две области вместе описываются в рамках ITIL: • Процесс Управления Непрерывностью Бизнеса (Business Continuity Management – ВСМ) обеспечивает анализ и Управление Рисками, что позволяет организации во все времена гарантировать сохранение минимально требуемых производственных мощностей и Уровня Сервисов. Процесс ВСМ помогает уменьшить степень риска до приемлемого уровня и разработать Планы восстановления бизнес-деятельности на случай, если она пострадает во время чрезвычайной ситуации. • Процесс Управления Непрерывностью ИТ-сервисов (ITSCM) – это процесс, предназначенный для противодействия на случай чрезвычайных обстоятельств, затрагивающих ИТ-услуги, и восстановления сервисов, необходимых для возобновления бизнес-операций. Процесс Управления Непрерывностью ИТ-сервисов является частью общего процесса Управления Непрерывностью Бизнеса, и он зависит от информации, которую предоставляет процесс ВСМ. Доступность ИТ-сервисов обеспечивается благодаря сочетанию мер по уменьшению степени риска (например, использование высоконадежных систем) и способов восстановления (например, запасные и параллельно работающие системы). Для успешной реализации процесса требуются поддержка со стороны всей организации, твердое намерение руководства реализовать данный процесс и участие всего персонала. Процесс Управления Непрерывностью ИТ-сервисов взаимодействует со всеми другими процессами ИТ Сервис-менеджмента, особенно с такими как: • Управление Уровнем Сервиса: предоставляет информацию об обязательствах во предоставлению ИТ-услуг. • Управление Доступностью: поддерживает процесс ITSCM в части разработки и внедрения превентивных мер. • Управление Конфигурациями: определяет базисные конфигурации и элементы ИТ-инфраструктуры, информация о которых используется при восстановлении после чрезвычайной ситуации. • Управление Возможностями: гарантирует поддержку требований бизнеса соответствующими ИТ-ресурсами. • Управление Изменениями: обеспечивает правильность и актуальность всех планов в рамках процесса ITSCM благодаря вовлечению ITSCM в работу над всеми изменениями, которые могут повлиять на превентивные меры и Планы восстановления. 13.4. Виды деятельностиНа рис 13.1 показаны виды работ, выполняемые в рамках процесса ITSCM. Цифры обозначают подразделы раздела 13.4, в которых описывается тот или иной вид деятельности.
Рис. 13.1. Модель Процесса Управления Непрерывностью ИТ-Сервисов (на основе модели OGC) 13.4.1. Определение охвата (области действия)[212] Процесса Управления Непрерывностью ИТ-сервисов При инициализации процесса ITSCM необходимо рассмотрение всей организации в целом и выполнение следующих действий: • Определение политики – определение политики организации в отношении Управления Непрерывностью ИТ-сервисов следует осуществить по возможности быстрее и довести ее до сведения каждого сотрудника организации, чтобы все знали о необходимости процесса ITSCM. Руководство должно продемонстрировать свое твердое намерение реализовать данный процесс. • Определение области действия процесса и других важных для процесса областей – при выборе подхода к оценке риска и Анализу воздействия на бизнес (Business Impact Analysis) и методов их выполнения используются страховые требования, стандарты качества, такие как серия ISO-9000, стандарты Управления Безопасностью, например, BS7799 и общие принципы определения политики в области бизнеса. На этом этапе также определяются соответствующая структура менеджмента и процессов на случай чрезвычайной ситуации. • Выделение ресурсов – развертывание ИТ-среды на случай чрезвычайных обстоятельств потребует значительных затрат на персонал и ресурсы. Должно быть проведено обучение персонала для подготовки к выполнению второго этапа процесса ITSCM (Требования и стратегия). • Подготовка проектной организации – рекомендуется использовать формальные методы Управления Проектом, такие как PRINCE 2, совместно с программным обеспечением, предназначенным для целей планирования. 13.4.2. Анализ воздействия на бизнес[213] Перед проведением анализа ИТ-услуг рекомендуется установить причины, почему компании необходимо включать Процесс Управления Непрерывностью ИТ-сервисов в общий Процесс Управления Непрерывностью Бизнеса, и определить потенциальное воздействие серьезных сбоев услуг. В некоторых случаях при возникновении чрезвычайной ситуации бизнес некоторое время еще может функционировать, и тогда основное внимание уделяется восстановлению услуг, в других случаях бизнес не может работать без ИТ-услуг, поэтому основное внимание уделяется предотвращению чрезвычайных ситуаций. В большинстве случаев необходимо найти баланс между этими двумя крайностями. Среди возможных причин внедрения этого процесса могут быть следующие: • защита бизнес-процессов; • быстрое восстановление сервиса; • необходимость выдержать конкуренцию; • сохранение позиций на рынке; • сохранение прибыльности; • защита репутации компании. Эти причины могут быть комбинированы. В финансовой сфере, например, в торговле валютными средствами, отсутствие информации о рынке ведет к приостановке торговли (основного бизнес-процесса), что означает потерю денег. Более того, если существует государственное требование регистрировать все валютные операции с использованием специализированной системы, то можно продолжать ведение бизнеса даже в случае повреждения этой системы, но рано или поздно это требование все равно будет нарушено, и тогда возможно наложение штрафа. В обоих случаях компания может потерять заказчиков и свои позиции на рынке. Анализ сервисов После того, как определена необходимость внедрения Процесса Управления Непрерывностью ИТ-сервисов, следует провести анализ ИТ-услуг, необходимых для бизнеса (например, информационные системы, офисные приложения, бухгалтерские приложения, электронная почта и т. д.), которые должны быть доступны в соответствии Соглашениям об Уровне Сервиса. Для некоторых услуг невысокой значимости могут быть достигнуты договоренности о предоставлении экстренного сервиса с ограниченными возможностями и доступностью. Уровни Сервиса во время восстановления могут быть изменены только по договоренности с заказчиком. Для критически важных услуг необходимо найти компромисс между превентивными мерами и способами восстановления. Инфраструктура После анализа сервисов выполняется оценка зависимостей между сервисами и ИТ-ресурсами. Информация из Процесса Управления Доступностью используется для анализа степени критичности ИТ-ресурсов для поддержки описанных ранее ИТ-услуг. Процесс Управления Возможностями предоставляет информацию о необходимых мощностях, а также помогает определить, на какое время эти услуги могут быть приостановлены с момента сбоя сервиса до его восстановления. В последствии такая информация может быть использована для определения способов восстановления по каждой услуге. 13.4.3. Оценка рисков Официальная статистика по чрезвычайным ситуациям отсутствует, но во всем мире известны такие катастрофы, как:
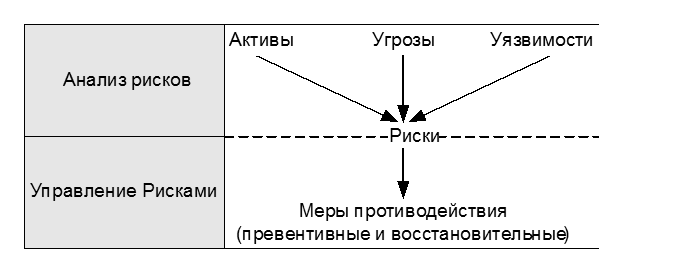
Анализ рисков способен помочь в определении рисков, угрожающих бизнесу. Такой анализ дает ценную информацию руководству, т. к. он позволяет выявить вероятные угрозы и виды уязвимости и определить соответствующие превентивные меры. Поскольку поддержка Плана восстановления после чрезвычайной ситуации является относительно дорогим мероприятием, то сначала можно воспользоваться превентивными мерами. После того, как такие меры предприняты против наиболее серьезных рисков, следует определить, остались ли еще риски, для которых необходим План обеспечения непрерывности работы (Contingency Plan). На рис. 13.2 показаны связи между Анализом рисков и Управлением Рисками; они основываются на методе Анализа и Управления Рисками, разработанного ассоциацией CCTA (CCTA Risk Analysis and Management Method – CRAMM).
Рис. 13.2. Метод оценки рисков ассоциации CCTA (источник: OGC) Данная модель позволяет поддерживать эффективное планирование на случай чрезвычайных обстоятельств путем реализации поэтапного подхода. Анализ рисков • Во-первых, должны быть определены вовлеченные компоненты (активы), такие как здания, системы, данные и т. д. Эффективная идентификация активов требует определения владельцев и назначения активов. • Следующий этап – анализ угроз и зависимостей, а также оценка вероятности возникновения чрезвычайной ситуации (высокая, средняя, низкая), например, комбинация ненадежной системы энергоснабжения и района с большим количеством бурь и гроз. • Далее – идентификация и классификация (высокая, средняя, низкая) уязвимостей. Молниеотвод может дать некоторую защиту от ударов молний, но они все же могут серьезно повлиять на работу сети и систем. • И последний этап – оценка угроз и уязвимостей в контексте ИТ-компонентов для получения оценки риска. При оценке риска следует учитывать область действия[214] процесса; фактически такая оценка является частью начала внедрения Процесса Управления Непрерывностью ИТ-сервисов (этап 1). Например, незначительные проблемы можно решить с помощью мер, принимаемых Процессом Управления Доступностью, в то время как другие риски для бизнеса могут выходить за сферу действия процесса ITSCM. 13.4.4. Стратегия обеспечения непрерывности ИТ-сервисов Многие направления бизнеса стараются найти равновесие между сокращением степени риска и планированием работ по восстановлению. Следует понимать разницу между такими понятиями, как сокращение риска, работы по восстановлению бизнес-деятельности и способы восстановления ИТ. Ниже обсуждается связь между сокращением степени риска (предотвращение) и планированием восстановления (способы восстановления). Угрозы никогда нельзя устранить полностью. Например, пожар в соседнем здании может повредить ваше здание. Уменьшение одного вида риска может вызвать повышение другого. Например, аутсорсинг может привести к повышению рисков в области безопасности. Превентивные меры Превентивные меры можно принимать на основе анализа рисков при тщательном учете затрат и рисков. Такие меры могут помочь в уменьшении вероятности непредвиденных обстоятельств или степени их воздействия, и тем самым сократить сферу действия Плана восстановления. Превентивные меры действенны против пыли, чрезвычайно высоких или низких температур, пожаров, утечек воды, прекращения энергоснабжения и воровства. Остальные виды рисков будут учтены в Плане восстановления. Метод «Неприступной крепости»[215] является самой дорогой превентивной мерой. Он позволяет устранить большинство видов уязвимости, например, путем строительства бункера с собственным энерго- и водоснабжением. Однако такой подход может привести к появлению других уязвимых мест, например, риску сбоя сети или появлению пробок на дорогах, что только затруднит восстановление. Подход «Неприступной крепости» пригоден для крупных вычислительных центров, которые слишком сложны для разработки для них Плана восстановления. В наше время важно дополнять данный подход возможностью быстрого реагирования[216], т. е. возможностью направляться туда, где есть проблема, и быстро ее решать, пока она не вышла из-под контроля. Выбор способов восстановления[217] Если остались еще виды рисков, которые не удалось устранить с помощью превентивных мер, тогда для них производится планирование восстановления. Способы восстановления должны включать в себя: • Персонал и размещение – помещение, мебель, транспорт, способ перемещения и т. д. • ИТ-системы и сети – способы восстановления будут обсуждаться ниже. • Вспомогательные службы – электро- и водоснабжение, телефон, почта и курьерская связь. • Архивы – дела, документы, архив на бумажных носителях и справочные материалы. • Услуги сторонних организаций – таких, как поставщиков услуг электронной почты и Интернета. Существует несколько способов для быстрого восстановления ИТ-услуг: • Ничего не делать – лишь немногие бизнес-организации могут себе это позволить. Это больше напоминает стремление уйти от проблем, устраниться от решения. Подразделения, которые думают, что могут обойтись без средств восстановления ИТ-сервиса, создают о себе впечатление, как о структурах, ничего не значащих для целей бизнеса, которые могут не потребоваться в случае чрезвычайной ситуации. Тем не менее для каждого ИТ-сервиса должна быть рассмотрена такая возможность. • Возврат к ручной (на основе бумажных носителей) системе – этот способ обычно не подходит для услуг, критически важных для бизнеса, поскольку трудно найти достаточное количество персонала, имеющего опыт работы с традиционными системами. Более того, бумажные системы, существовавшие в прошлом, теперь могут уже не существовать. Тем не менее такие системы можно использовать для менее важных, второстепенных услуг. Большинство планов восстановления включают в себя процедуры резервного копирования на бумажные носители. Например, способом восстановления для терминала кредитных карт может быть использование бумажных оттисков (слипов) с кредитных карт. • Взаимные соглашения – этот способ можно использовать в том случае, когда две организации используют одинаковое аппаратное обеспечение и между ними существует договоренность о предоставлении друг другу необходимых устройств в случае возникновения чрезвычайных обстоятельств. Для данного способа две бизнес-структуры должны заключить соглашение и координировать все изменения, с тем, чтобы сохранить взаимозаменяемость двух сред. Процесс Управления Возможностями должен следить за тем, чтобы зарезервированные возможности не использовались для других целей или чтобы их можно было быстро освободить. В настоящее время этот способ не очень привлекателен из-за роста использования онлайновых систем, таких как сети банкоматов (ATM) и онлайновые банковские системы для клиентов, т.к. эти системы должны быть доступны круглосуточно в течение всего времени. • Поэтапное восстановление («холодный» резервный центр[218]) – этот способ можно использовать в тех сферах бизнеса, где можно обойтись без ИТ-услуг в течение определенного периода времени, например, 72-х часов. При использовании данного способа заказчику предоставляется свободный компьютерный зал на заранее оговоренной территории, стационарный центр[219] или мобильная компьютерная комната, доставляемая на место расположения компании, - мобильный центр[220]. Такой компьютерный центр должен быть снабжен электропитанием, кондиционером, сетевыми коммуникациями и телефонной связью. Данный способ может быть предоставлен по договору с внешним поставщиком. Кроме того, необходимо отдельное соглашение с поставщиком, гарантирующее быструю доставку ИТ-компонент. Общее преимущество такого подхода состоит в том, что эти средства восстановления доступны всегда. Кроме того, для стационарного и мобильного компьютерного центра преимущества и недостатки различаются и зависят от таких аспектов, как: - Расстояние до центра – обычно существует ограниченное количество поставщиков, предоставляющих услуги стационарного центра, и он может находиться на некотором расстоянии от заказчика. Этот недостаток может быть компенсирован использованием мобильной станции. - Время – стационарные залы доступны лишь на определенное время. - Задержка – в любом случае доставка необходимого компьютерного оборудования занимает определенное время. - Сеть – часто возникают трудности с предоставлением нужных телекоммуникационных средств. Оборудование передвижной станции можно подсоединить к сети в основном используемом здании. • Промежуточное восстановление («теплый» резерв[221]) – данный способ обеспечивает доступ к аналогичной операционной среде, в которой можно восстановить обычное предоставление услуг в течение короткого промежутка времени (от 24 до 72 часов). Существует три варианта этого способа: - Внутренний (совместное устранение неисправности): применим в тех случаях, когда бизнес располагается на нескольких площадках или имеет выделенную среду тестирования, которую можно использовать в качестве рабочей среды. Данный способ обеспечивает полное восстановление при минимальных затратах времени на переключение. В организациях с несколькими распределенными системами часто используется один из вариантов этого подхода, когда на каждой системе резервируется часть требуемых мощностей. Мониторинг таких свободных мощностей осуществляется Процессом Управления Мощностями (аналогично варианту использования взаимных соглашений – см. выше). - Внешний: некоторые поставщики услуг предлагают этот способ как коммерческую услугу. При этом затраты распределяются между несколькими заказчиками. Расходы по данному варианту зависят от того, какое программное и аппаратное обеспечение потребуется, на какой период времени будут предоставляться средства (например, на 16 недель). Часто этот способ помогает сохранить работоспособность на период времени, в течение которого активируется «холодный» резервный центр. Данный вариант способа промежуточного восстановления относительно дорогостоящий и предоставленный центр, скорее всего, будет находиться на некотором удалении от основной территории. - Мобильный: в данном варианте готовая к работе инфраструктура размешается в трейлере, который используется как компьютерный зал и оборудован устройствами контроля за окружающей средой, такими как кондиционеры. У ИТ-организации должно быть место для парковки такого трейлера. В специально выделенных пунктах на некотором расстоянии от основного здания должны быть предусмотрены источники электропитания, телекоммуникационные каналы и хранилище данных. Преимуществами такой версии являются быстрое время реагирования и близость к месту расположения компании. Данный способ доступен только для ограниченного числа технических платформ. Некоторые крупные поставщики оборудования предлагают несколько трейлеров со стандартными конфигурациями аппаратного обеспечения. В согласованный момент времени, например, раз в год, такой трейлер направляется к месту расположения бизнеса для проверки Плана восстановления. Кроме того, такая процедура позволяет произвести тестирование перехода[222] на новую версию операционной системы. • Немедленное восстановление («горячий» старт, «горячее» восстановление[223]) – данный способ обеспечивает немедленное или очень быстрое восстановление работы менее чем за 24 часа путем предоставления идентичной рабочей среды и зеркального отображения данных, а возможно, и рабочих процессов. Последний вариант обычно разрабатывается при тесном взаимодействии с Процессом Управления Доступностью. • Комбинации способов – часто План на случай чрезвычайных обстоятельств[224] включает в себя более дорогой способ восстановления, который используется до активизации более дешевого варианта. Например, трейлер, оборудованный как передвижной вычислительный центр (мобильный «горячий» старт), может служить временным решением до тех пор, пока не приедет мобильный центр и не будут доставлены новые главные сервера[225] (передвижной «холодный» старт). Нормальная работа будет возобновлена после восстановления здания и установки в нем новых главных компьютеров. 13.4.5. Организация процесса и планирование внедрения После того, как определена стратегия бизнеса и сделан выбор одного из перечисленных способов восстановления, необходимо переходить к реализации Процесса Управления Непрерывностью ИТ-сервисов и разработки детальных планов для использования выбранных средств восстановления. Реализацией процесса ITSCM должна заниматься специальная группа. Ее организация может включать в себя назначение руководителя (Руководитель на случай кризисной ситуации[226]), координацию работ и формирование восстановительных команд каждого сервиса. На самом высоком уровне должен быть разработан общий план, охватывающий следующие вопросы: • План экстренного реагирования; • План оценки повреждений; • План восстановления работы; • План работы с важными данными (что делать с данными, включая записи на бумажных носителях); • План руководства на случай кризисной ситуации и связь с общественностью (PR). Все эти планы используются для оценки экстренных ситуаций и определения мер реагирования на них. После этого можно принимать решение об инициировании процесса восстановления бизнеса, при котором начинают действовать планы следующего уровня, включающие: • План размещения и оказания услуг; • План по вычислительным системам и локальным сетям; • План по телекоммуникациям (доступ и каналы связи); • План обеспечения безопасности (целостность данных и сетей); • План по персоналу; • Финансовые и административные планы. 13.4.6. Применение превентивных мер и способов восстановления Этот этап заключается в практическом воплощении определенных ранее превентивных мер и способов восстановления. Превентивные меры по уменьшению степени воздействия предпринимаются совместно с деятельностью в рамках Процесса Управления Доступностью и могут включать: • Использование бесперебойных источников питания и резервных источников электропитания; • Использование отказоустойчивых систем[227]; • Использование удаленных систем хранения данных и RAID-массивов и т. д. Также должен быть объявлен стартовый срок для активизации резервных соглашений, включающих персонал, здания и телекоммуникации. Даже еще во время действия непредвиденных обстоятельств уже можно начинать работы по восстановлению нормальной деятельности и заказу новых ИТ-компонентов. Рамочные неактивированные («дремлющие») договоры на такой случай могут быть заключены с поставщиками заранее. В этом случае уже будут подписаны заказы на поставку компонентов по согласованной ранее цене. В случае чрезвычайной ситуации поставщик будет исполнять заказ без необходимости обсуждения его пены. Такие неактивированные («дремлющие») договоры следует пересматривать каждый год, т. к. цены и модели технических средств могут изменяться. При корректировке договоров следует учитывать базисные конфигурации, зарегистрированные в рамках Процесса Управления Конфигурациями. При подготовке резервных соглашений могут осуществляться следующие виды деятельности: • ведение переговоров со сторонними организациями по вопросам удаленных средств восстановления; • поддержка и оснащение средств восстановления; • закупка и установка резервного аппаратного обеспечения (неактивированные договоры); • управление неактивированными («дремлющими») договорами. 13.4.7. Разработка планов и процедур восстановления Планы должны быть разработаны в деталях и стать официальными документами, т. к. Планы восстановления требуют поддержки, и все изменения в них должны согласовываться заинтересованными сторонами. Эта информация также должна доводиться до сведения всех участников. Основные проблемы связаны с изменениями в инфраструктуре и Изменениями Уровней Сервиса. Например, переход на новую платформу среднего класса[228] может привести к тому, что не будет эквивалентного оборудования в резервном центре «теплого», внешнего старта. По этой причине Процесс Управления Конфигурациями играет важную роль в мониторинге базисных конфигураций с учетом Плана восстановления. В плане также должны быть определены процедуры, необходимые для его выполнения. План восстановления План восстановления должен включать все виды деятельности по восстановлению бизнес-активности и ИТ-услуг: • Введение – описание структуры плана и предполагаемых средств восстановления. • Обновление – описание процедур и соглашений по поддержке актуальности плана и отслеживанию изменений в инфраструктуре. • Маршрутный лист – план делится на разделы, каждый из которых определяет действия, выполняемые конкретной группой специалистов. Маршрутный лист показывает, какие разделы плана должны быть направлены в каждую группу. • Начало восстановления – описание времени и условий начала действия плана. • Классификация чрезвычайных обстоятельств – если в плане дается описание процедур на случай различных чрезвычайных обстоятельств, то они должны быть описаны с точки зрения их серьезности (незначительные, среднего уровня серьезности, серьезные), длительности (день, неделя, месяцы) и уровня повреждений (незначительные, ограниченные, серьезные). • Разделы для участвующих групп специалистов – план должен быть разделен на шесть разделов – по количеству областей действия и закрепленных на за ними групп специалистов: - Администрация – как и когда вводить план в действие, какие руководители и специалисты участвуют в нем, где находиться центр управления? - ИТ-инфраструктура – аппаратное и программное обеспечение, телекоммуникационные средства, включенные в систему восстановления и соответствующие процедуры, а также неактивированные («дремлющие») договоры на закупку новых ИТ-компонентов. - Персонал – персонал, необходимый для работы в резервном центре, возможно, средства транспортировки и размещение персонала, если резервный центр расположен удалено от основного месторасположения. - Безопасность – инструкции по защите от краж, пожаров и взрывов, как в основном здании, так и на удаленной площадке, а также информация о внешних хранилищах, таких как склады и подвалы. - Площадки восстановления – информация о договорах, персонале с указанием конкретных функций, системе безопасности и транспорте. - Возврат к нормальным условиям – процедуры восстановления нормальной инфраструктуры (например, здания), условия, при которых начинают действовать эти процедуры и соответствующие неактивированные («дремлющие») контракты. Процедуры Процедуры разрабатываются на основе Плана восстановления. Они должны быть эффективными[229], так, чтобы каждый мог выполнять работы по восстановлению, следуя этим процедурам. Процедуры должны включать: • инсталляцию и тестирование технических средств и сетевых компонентов; • восстановление приложений, баз данных и других данных. Эти и другие необходимые процедуры должны прилагаться к Плану восстановления. 13.4.8. Начальное тестирование Начальное тестирование – критически важный аспект процесса ITSCM. Тесты следует проводить в начале работы, потом после проведения значительных изменений и затем, как минимум, один раз год. ИТ-подразделения отвечают за тестирование эффективности планов и процедур в отношении ИТ-элементов. Тесты могут проводиться с предварительным объявлением или без него. 13.4.9. Обучение и осведомление Обучение персонала ИТ-подразделения и других отделов компании и осведомленность всего персонала организации являются важными условиями успешной реализации Процесса Управления Непрерывностью ИТ-сервисов. Персонал ИТ-подразделения должен проводить обучение других членов команды восстановления бизнеса, незнакомых с вопросами информационных технологий, чтобы они могли оказать необходимую поддержку при проведении восстановительных работ. Обучение и тестирование должно охватывать как центральные, так и удаленные средства, предусмотренные на случай чрезвычайных обстоятельств. 13.4.10. Анализ и аудит Следует регулярно проводить аудит и проверять актуальность всех планов. Такая проверка затрагивает все аспекты Процесса Управления Непрерывностью ИТ-сервисов. В области ИТ такой аудит должен проводиться при каждом значительном изменении ИТ-инфраструктуры, например, при вводе в операционную среду новых систем и сетей и появлении новых поставщиков. Аудит также должен проводиться при любом изменении стратегии ИТ-подразделения или бизнеса. Организации, где происходят быстрые и частые изменения, могут внедрить регулярную программу по проверке концепции процесса ITSCM. Любые изменения в планах и стратегии, появившиеся в результате проведения таких проверок, должны быть реализованы под руководством Процесса Управления Изменениями. 13.4.11. Тестирование Необходимо проводить регулярное тестирование Плана восстановления, подобно объявлению учебных тревог на борту корабля. Если в компании изучение плана начинается после того, как произошла чрезвычайная ситуация, то, вероятнее всего, у такой организации будет немало проблем с восстановлением. Тестирование позволяет выявить слабые места плана и изменения, которые не были учтены. В некоторых случаях можно проводить тестирование изменений на средствах восстановления прежде, чем вводить их в действующую ИТ-инфраструктуру. 13.4.12. Управление Изменениями Процесс Управления Изменениями играет важную роль в поддержании актуальности Планов восстановления. Необходимо проводить анализ воздействия любого изменения на План восстановления. 13.4.13. Обеспечение гарантий[230] Обеспечение гарантий работоспособности процесса означает проверку соответствия качества процесса (процедур и документации) бизнес-потребностям компании. 13.5. Управление ПроцессомЭффективное Управление Процессом базируется на отчетах для руководства, критических факторах успеха и ключевых показателях качества. 13.5.1. Отчеты для руководства В случае возникновения чрезвычайной ситуации предоставляются отчеты о причинах и последствиях чрезвычайной ситуации и действиях по ее разрешению. Любое выявленное при этом слабое место будет учтено в Планах по улучшению сервисов. В отчеты для руководства по данному процессу также должны быть включены отчеты о тестировании Плана восстановления. Должны также составляться отчеты о произведенных изменениях в плане по восстановлению как результатах изменения каких-либо частей ИТ-инфраструктуры. 13.5.2. Критические факторы успеха и ключевые показатели качества Успех Процесса Управления Непрерывностью ИТ-сервисов зависит от следующих факторов: • наличия эффективного Процесса Управления Конфигурациями; • поддержки процесса всеми в компании; • наличия современных эффективных инструментальных средств; • проведения специального обучения для всех участников данного процесса; • регулярного тестирования плана восстановления без предварительного уведомления. Ключевыми показателями качества являются: • количество выявленных ошибок в планах восстановления; • потеря дохода компании в результате чрезвычайной ситуации; • стоимость процесса. 13.5.3. Функции и роли Задачи Руководителя Процесса Управления Непрерывностью ИТ-сервисов состоят во внедрении и обеспечении поддержки процесса ITSCM для постоянного выполнения всех требований по Управлению Непрерывностью Бизнеса (ВСМ) и представлении функций ИТ-сервисов в рамках процесса ВСМ. В данном процессе можно определить несколько ролей и видов ответственности, а также установить различие между ответственностью в обычных условиях и ответственностью в кризисных ситуациях.
Таблица 13.1. Примеры видов ответственности в рамках Процесса Управления Непрерывностью ИТ-сервисов 13.6. Проблемы и затраты13.6.1. Затраты Основные затраты, связанные с реализацией Процесса Управления Непрерывностью следующие: • затраты времени и средств на инициацию, разработку и внедрение процесса ITSCM. • затраты на организацию Управления Рисками и связанное с этим дополнительное аппаратное обеспечение. Эти расходы можно сократить, если включить эти действия в сферу деятельности Процесса Управления Доступностью на этапе разработки новых конфигураций. • переходящие затраты на поддержку выбранных способов восстановления, такие как плата по Внешним Договорам по «горячему» старту, затраты на организацию тестирования и плата за период поддержания в готовности средств восстановления. • повторяющиеся операционные расходы на тестирование, аудит и корректировку планов. Эти расходы возникают только после того, как сделан обоснованный выбор и проведено сравнение с возможными расходами в случае отказа от создания Плана восстановления. Хотя затраты на поддержку такого плана могут показаться высокими, часто они оказываются вполне сопоставимыми с общими расходами на страхование от пожаров и воровства. Более того, эффективный процесс ITSCM может помочь уменьшить расходы на страхование. 13.6.2. Проблемы При внедрении данного процесса могут возникнуть следующие проблемы: • Ресурсы – организация должна предоставить дополнительные мощности проектной команде для разработки и тестирования плана. • Серьезность намерений (обязательства) – ежегодные расходы на процесс должны быть включены в бюджеты организации, для чего требуется твердое намерение руководства поддерживать Процесс Управления Непрерывностью ИТ-сервисов. • Доступ к средствам восстановления – для всех обсужденных выше способов восстановления требуется проведение регулярного тестирования соответствующих средств. Поэтому заключаемые договоры должны обеспечивать регулярный доступ ИТ-организации к средствам восстановления. • Оценка потерь – некоторые потери, такие как потеря репутации, нельзя измерить в денежном выражении. • Составление бюджета – не всегда удается добиться понимания необходимости в дорогих средствах восстановления функциональности, иногда происходит сокращение Планов восстановления. • Отсутствие обязательств со стороны бизнес-руководителя – это ведет к неудаче в разработке процесса ITSCM, хотя заказчик может полагать, что все необходимое сделано. • Постоянное откладывание – это бывает в тех случаях, когда отсутствует большинство составляющих процесса и, как следствие этого, реализация процесса постоянно откладывается. В таких случаях на вопрос о Процессе Управления Непрерывностью ИТ-сервисов даются ответы: «Да. Мы встречается по этому вопросу на следующей неделе», «Мы собирается создать комиссию специально по данному вопросу» и тому подобное. • Черный ящик – это бывает в тех случаях, когда поставщик ИТ-услуг отказывается от ответственности, а также прекращает управлять готовностью процесса: «Кто-то еще этим занимается». Поскольку организация затратила много средств или передала часть своих операций поставщику, руководство надеется, что затраченные деньги обеспечат возможность восстановления или же что у поставщика есть планы, которые помогут восстановить бизнес после чрезвычайной ситуации. • ИТ-подразделение – в своей работе должно руководствоваться действительными пожеланиями и требованиями бизнеса, а не своими предположениями. • Знание бизнеса – важно, чтобы бизнес поддерживал разработку процесса ITSCM путем определения основных направлений работы. • Отсутствие осведомленности в компании – необходимо, чтобы вся организация знала о значимости процесса ITSCM. Без информирования персонала и его поддержки процесс обречен на неудачу. Примечания:2 Термин «ИТ Сервис-менеджмент», с одной стороны, используется как синоним термина «Управление ИТ-услугами», но, с другой стороны, усиливает его, имея в виду централизованный подход к менеджменту всей ИТ-организацией как современным сервисным подразделением, направленным на предоставление услуг бизнес-подразделения и являющихся неотъемлемым звеном в производственном процессе. 21 Mentors and coachers. 22 IT Customer Relationship Management – IT CRM. 23 Service Level Management – CLM. 210 Denial of Service – DoS. 211 Benefits. 212 Scope. 213 Business Impact Analysis. 214 Scope. 215 Stronghold/Fortress approach. 216 Skirmish Capability. 217 Recovery Options. 218 Cold Stand-by. 219 Fixed Facility. 220 Mobile Facility. 221 Warm Stand-by. 222 Upgrade. 223 Hot Start, Hot Stand-by. 224 Contingency Plan. 225 Host Computers. 226 Crisis Manager. 227 Fault-tolerant Systems. 228 Midrange Platform. 229 Effective. 230 Assurance. |
|
|||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
|||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||