|
||||
|
|
Часть 2.В первой части статьи мы остановились на этом:  Пойдём дальше. Вторая часть статьи. Использование Photoshop’а (Curves) для чистки сканов книг + философское отступление.Напомню, речь идет только о черно-белых книгах (текст и штриховые рисунки). Не о цветных. * * *В отзывах к первой части статьи прозвучал много хороших слов и благодарностей. Большое спасибо всем, кто нашел время откликнутся, написать пару строк в комменты, тем более с добрыми словами в мой адрес. Доброе слово, как говорится, и кошке приятно. Всем удачи:-) Надеюсь, однако, что будет больше замечаний непосредственно по теме. Делитесь своими наработками, рецептами. Некоторые блогеры упомянули о других программах/способах обработки сканов – напишите о них, это будет интересно всем. Профессионалы, расскажите о более серьезных программах, а можно и выложить. Критикуйте, дополняйте эту статью (это касается всех частей)- ведь это выгодно всем. * * * Философское отступлениеДа, я знаю, что надо не грузить общими рассуждениями, а говорить конкретно. Но любое дело лучше делать осмысленно. Осмысление же требует хотя бы самого общего представления о сути предмета. Поэтому, пожалуйста, прочтите последующие несколько абзацев не спеша, вдумчиво. Может быть они будут Вам полезны не только в деле очистки сканов книг. Возможно, Вам покажутся общеизвестными высказанные там мысли, но, как показывает опыт общения, это не так. Если влом читать неконкретные вещи, то можно сразу перейти к Photoshop: Curves, всё, что там написано, можно понять и не читая раздел Философское отступление Итак, пару слов о шуме (помехе), (полезном) сигнале и фильтрации, в самом общем плане, безотносительно к обработке изображения. Сигнал. Имеется ввиду полезный сигнал. Сигнал – это то, что нам нужно… Это исчерпывающее определение. Например, сигналом может быть часть картинки – изображение текста в примере, который мы разбираем. Или голос исполнителя в музыкальном клипе. Или правда в речах политика, если она там есть. И всё, что угодно. Шум. А шум, помеха, это то, что нам не нужно. Например фон текста на картинке (фактура бумаги, пятна, следы грязи на стекле сканера). Или звучание музыкальных инструментов в муз. клипе, если мы хотим выделить голос исполнителя. Или вся речь политика, если правды там нет. Фильтрация, это процесс разделения сигнала и шума. Это может быть некое электронное или механическое устройство, компьтерная программа. Разум слушателя, если речь идет о словах политика… Для того, чтобы фильтрация была осуществима, сигнал и шум хоть в чем-то, но должны отличаться. Т.е. мы должны найти параметры, свойства, по которым отличаются шум/сигнал и увеличить это различие. Вернемся к сканам книги. На краях и переплета после сканирования часто бывают черные полосы. Это тоже шум. От полезного сигнала, изображения текста, он отличается расположением в двумерном пространстве изображения страницы, поэтому отделить его легко руками и относительно легко автоматически. Стоит, однако, неплотно прижать толстую книгу при сканировании и черная полоса будет пересекаться с текстом. И всё, выделить текст в этом месте методами обработки изображения станет невозможно. Но если речь идет всего о 1-2 буквах в начале (конце) строки, мозг, почти на 100% восстановит недостающие буквы. Вдь ткст очн избтчн, при удални глснх всё ещ мжно пнть о чм рчь. Однако фильтрация и восстановление будет идти не изображения, а текста как последовательности букв и слов, с учетом их смысла, семантики. Программа NeatImage, описанная в 1-ой части статьи использует другой критерий различения шума и сигнала – разницу в двумерных спектрах сигнала и шума. Обратите внимание: указывать где шум, а где сигнал нам пришлось самостоятельно. В иных случаях шум и сигнал могут поменяются местами. Например, криминалисту может быть задан вопрос: – "Где взята бумага, на которой написана жуткая записка?". И фактура бумаги была бы полезным сигналом, а изображение текста – шумом. В 3-й части статьи будет описана работа с фильтром Фотошопа Smart Blur. Там используются другие критерии разделения сигнала и шума. ВыводНужно обязательно понимать, по какому критерию происходит разделение сигнала и шума в используемых вами процедурах фильтрации. Тогда можно будет выработать более эффективный метод обработки. Ведь если мы по очереди применим несколько фильтров с разными критериями фильтрации, то результат будет хороший. Если же фильтры обрабатывают по одному и тому же критерию, то с какого-то момента, улучшения не будет, а то и начнется ухудшение разделения. * * * Photoshop: CurvesЗдесь описана работа с Фотошопом, но подобный инструмент есть в любом достаточно мощном растровом редакторе: Gimp, Corel Photopaint, PaintShop Pro и др. Алгоритмы у всех одинаковы. Важно лишь наличие у редактора режима пакетной обработки. Итак, инструмент Curves. Что, собственно, мы им сделаем? Это очень просто: разделим шум и полезное изображение по критерию яркости. Всё, что будет белее некоторого порога, станет максимально белым. Соответственно всё, что будет темнее некоторого порога, будет совершенно черным. Все наши усилия будут направленны как раз на установление этих порогов так, чтобы фон попал в белое, а текст – в черное. Имейте ввиду, если после предыдущих этапов обработки на изображении есть участки шума более темные, чем наиболее светлые участки текста, то Curves их не только не удалит, а наоборот – подчеркнет. Вызываем Curves (Меню: Image -› Adjustments -› Curves или просто Ctrl-M). На Рис. 1 стрелками указаны две пипетки: "Уровень черного" и "Уровень белого". Орудуя ими по очереди мы и подгоним пороги так, чтобы текст было побольше, а шума поменьше. Серая пипетка нам не нужна. Кнопка в правом нижнем углу (подсвечена желтым) увеличивает окошко или делает его компактным. 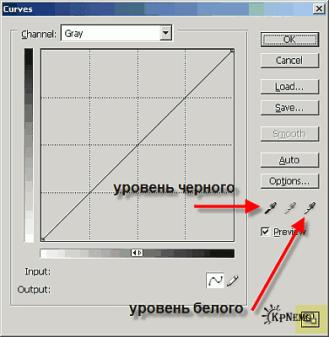 Рис. 1 Рис. 1 Перед вызовом Curves нужно увеличить изображение на весь экран так, чтобы были целиком видны 3-4 буквы. Обязательно должна попасть точка и запятая, буквы с мелкими деталями. Лучше выберите сильно зашумленный участок, там где шум более темный. По возможности выберите участок с мелким шрифтом, например текст сноски внизу страницы. Теперь по очереди, чередую пипетки, щелкайте на белой – на участках с шумом, черной – на полезных участках картинки, на буквах. Когда будет работать пипетками, контролируйте следующие критерии, они выбраны с учетом характерных ошибок FineReader'а: – точка "." и запятая "," должны отличаться; – белый участок внутри букв "е", "о", "R" и т.п не должен быть залит черным; – мелкие детали букв должны быть различимы, например хвостик у курсивной "а", она не должна превращатся в "о"; – следите за "коромыслом" у буквы "й", точкой над "i" и другими подобными элементами букв; – обратите внимание на верхние (и нижние) индексы, например значки и цифры, указывающие на сноску; – мелкие разрывы в вертикальных участках широких букв – "м", "ш" – не страшны; – в горизонтальных/наклонных участках букв "н", "и", "п" разрывов быть не должно. FR немедленно начинает их путать; На рисунках 2-6 показаны скриншоты последовательной настройки уровней белого ичерного. Пипетка выделена овалом. Розовым – черная, желтым – белая.  Рис. 2 Рис. 2  Рис. 3 Рис. 3  Рис. 4 Рис. 4  Рис. 5 Рис. 5  Рис. 6 Рис. 6 Когда настроите Curves, сохраните профиль: "Save…". Он будет использован потом, при пакетной обработке остальных страниц. Вот что получилось:  Рис. 7 Рис. 7 В начале первой части статьи я говорил о том, как влияет очистка изображения на степень сжатия. Посмотрите как последовательно уменьшаются размеры картинок от 2-й до 7-й. С 8806 байт до 1376. Это хорошая иллюстрация к упомянутому утверждению. Теперь надо записать Action, чтобы автоматически обработать Фотошопом остальные страницы. В нем будет всего две команды: 1) Curves, c ранее сохраненным профилем; 2) Image -› Mode -› Bitmap… Выскочит окошко Bitmap. В строке "Resolution" оставьте как есть – 600dpi. В строке "Metod" выберите "50% Threshold". Можно сначала попробовать Threshold отдельно, до записи скрипта, чтобы посмотреть, что получилось. Если вам покажется лучше другой уровень Threshold, не 50%, вставьте его в Action отдельной командой, сразу после Curves. Запускать пакетную обработку в Фотошопе, надеюсь, все умеют? Если нет, то у Фотошопа есть Help… Следующая, 3-я, часть статьи будет посвящена работе с фильтром Smart Blur. Может быть, я добавлю туда материалы по некоторым другим способам обработки изображений. А может быть и нет, как со временем будет |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||