|
||||||||||||||||||||||
|
|
Глава 3"Подводные камни" Данная глава посвящена "подводным камням"— ситуациям, в которых ошибки или неожиданное поведение программы наиболее вероятны. Другими словами, подводные камни — это то, на чем раз за разом спотыкаются многие начинающие программисты. Не претендуя на описание всех подобных случаев, мы, тем не менее, разберем несколько достаточно характерных примеров. Более полный список можно посмотреть в разделе "Подводные камни" сайта "Королевство Delphi" (см. приложение 1). Подводные камни можно классифицировать по причинам, вызывающим повышенную вероятность ошибок, следующим образом: □ Аппаратные "камни" — проблемы, вызванные некорректной работой аппаратуры. Наиболее известная из таких проблем — неправильная работа операции деления в блоке FPU первых версий процессора Pentium (в настройках компилятора Delphi можно увидеть опцию Pentium-safe FDIV — при ее включении генерируется более медленный, но правильно работающий на (очень) старых процессорах код для вещественного деления). Но подобные проблемы, к счастью, редки, поэтому мы не будем рассматривать их здесь. □ Системные "камни" — проблемы, вызванные тем, что системные функции, которые использует программа, работают не так, как описано в документации, или же у этих функций обнаруживаются особенности работы, вообще не упомянутые в документации. □ "Камни" компилятора — проблемы, вызванные ошибками компиляторе Delphi. □ "Камни" VCL — ошибки, содержащиеся в библиотеке VCL. Ранее мы уже упоминали о некоторых из них. Далее мы рассмотрим еще несколько имеющихся в ней ошибок. □ И последний класс "камней" — ошибки, связанные с тем, что программист — человек. Здесь объединены ситуации, когда документация даёт исчерпывающее описание проблемы, аппаратура и программные средства работают безукоризненно, но все новые и новые поколения программистов совершают одни и те же ошибки, потому что ситуация кажется им слишком простой и очевидной, чтобы изучать документацию. (Заметим, что это не говорит плохо о таких программистах — человеческая психология имеет свои законы, столь же объективные, как и законы в естественных науках.) Но компьютер — лишь имитация реального мира, и нередко он не оправдывает наших интуитивных ожиданий. Пункты приведенной классификации не являются взаимоисключающими: далее мы увидим, что некоторые ситуации попадают одновременно под несколько пунктов. Данная глава посвящена детальному разбору некоторых из подобных ситуаций. Она состоит из четырех разделов. Первый раздел посвящен неочевидным проблемам при работе с целыми числами, второй — при работе с вещественными, в третьем описываются неочевидные моменты использования строк, а в четвертом собрана небольшая коллекция не связанных между собой "подводных камней", с которыми пришлось столкнуться автору книги. Всем ситуациям дано подробное объяснение, чтобы читатель не только запомнил, как делать нельзя, но и понял, почему. Описание каждого из подводных камней будет сопровождаться примером, который можно найти на прилагаемом компакт-диске. Все примеры (за исключением специально оговоренных случаев) построены следующим образом: на главную (и единственную) форму программы помещаются компоненты Button1: TButtonи Label1: TLabel. Событию Button1.OnClickназначается код. демонстрирующий проблему, результат работы кода отображается в Label1.Caption. В тексте книги приводится только код этого обработчика. 3.1. Неочевидные особенности целых чиселАппаратная реализация целочисленной арифметики достаточно очевидна и в большинстве случаев не приносит неожиданностей. К тому же возможные проблемы в том или ином виде упомянуты во многих книгах по Delphi, поэтому даже начинающий программист обычно готов к ним. В этом разделе мы компактно изложим эти проблемы и объясним причины их появления. 3.1.1. Аппаратное представление целых чиселDelphi относится к языкам, в которых целые типы данных максимально приближены к аппаратной реализации целых чисел процессором. Это позволяет выполнять операции с целочисленными данными максимально быстро, но заставляет программиста учитывать аппаратные ограничения. Примечание Целые числа могут быть знаковыми и беззнаковыми. Сначала рассмотрим формат более простых беззнаковых чисел. Если у нас есть N двоичных разрядов для хранения такого числа, то мы можем представить любое число от 0 до 2N-1. В Delphi беззнаковые целые представлены фундаментальными типами Byte (N=8, диапазон 0..255), Word (N=16, диапазон 0..65 535) и LongWord (N=32, диапазон 0..4 294 967 295). Примечание Знаковые числа устроены несколько сложнее. Старший из N бит, отводящихся на такое число, служит для хранения знака (этот бит называется знаковым). Если этот бит равен нулю, число считается положительным, а оставшиеся N-1 разрядов используются для хранения числа так же, как в случае беззнакового целого (эти разряды мы будем называть беззнаковой частью). В этом случае знаковое число ничем не отличается от беззнакового. Отрицательные значения кодируются несколько сложнее. Когда все разряды (включая знаковый бит) равны единице, это соответствует значению -1. Рассмотрим это на примере однобайтного знакового числа. Числу -1 в данном случае соответствует комбинация 1 1111111 (знаковый бит мы будем отделять от остальных пробелом), т.е. беззнаковая часть числа содержит максимально возможное значение -127. Числу -2 соответствует комбинация 1 1111110, т.е. в беззнаковой части содержится 126. В общем случае отрицательное число, хранящееся в N разрядах равно X-2N-1, где X — положительное число, хранящееся в беззнаковой части. Таким образом, N разрядов позволяют представить знаковое целое в диапазоне -2N-1..2N-1-1, причем значению -2N-1 соответствует ситуация, когда все биты, кроме знакового равны нулю. Такая на первый взгляд не очень удобная система позволяет унифицировать операции для знаковых и беззнаковых чисел. Для примера рассмотрим число 11111110. Если его рассматривать как беззнаковое, оно равно 254, если как знаковое, то -2. Вычитая из него, например, 3, мы должны получить 251 и -5 соответственно. Как нетрудно убедиться, в беззнаковой форме 251 — это 11111011. И число -5 в знаковой форме — это тоже 11111011, т.е. результирующее состояние разрядов зависит только от начального состояния этих разрядов и вычитаемого числа и не зависит от того, знаковое или беззнаковое число представляют эти разряды. И это утверждение справедливо не только для выбранных чисел, но и вообще для любых чисел, если ни они, ни результат операции не выходят за пределы допустимого диапазона. То же самое верно для операции сложения. Поэтому в системе команд процессора нет отдельно команд знакового и беззнакового сложения и вычитания — форматы чисел таковы, что можно обойтись одной парой команд (для умножения и деления это неверно, поэтому существуют отдельно команды знакового и беззнакового умножения и деления). Ранее мы специально оговорили, что такое удобное правило действует только до тех пор, пока аргументы и результат остаются в рамках допустимого диапазона. Рассмотрим, что произойдет, если мы выйдем за его пределы. Пусть в беззнаковой записи нам нужно из 130 вычесть 10. 130 — это 10000010, после вычитания получим 01111000 (120). Но если попытаться интерпретировать эти двоичные значения как знаковые числа, получится, что из -126 мы вычитаем 10 и получаем 120. Такими парадоксальными результатами приходится расплачиваться за унификацию операций со знаковыми и беззнаковыми числами. Рассмотрим другой пример: из пяти (в двоичном представлении 00000101) вычесть десять (00001010). Здесь уместно вспомнить вычитание в столбик, которое изучается в школе: если в разряде уменьшаемого стоит цифра, большая, чем в соответствующем разряде вычитаемого, то из старшего разряда уменьшаемого приходится занимать единицу. То же самое и здесь: чтобы вычесть большее число из меньшего, как бы занимается единица из несуществующего девятого разряда. Это можно представить так: из числа (1)00000101 вычитается (0)00001010 и получается (0)11111011 (несуществующий девятый разряд показан в скобках: после получения результата мы про него снова забываем). Если интерпретировать полученный результат как знаковое целое, то он равен -5, т.е. именно тому, что и должно быть. Но с точки зрения беззнаковой арифметики получается, что 5-10=251. Приведенные примеры демонстрировали ситуации, когда результат укладывался в один из диапазонов (знаковый или беззнаковый), но не укладывался в другой. Рассмотрим, что будет, если результат не попадает ни в тот, ни в другой диапазон. Пусть нам нужно сложить 10000000 и 10000000. При таком сложении снова появляется несуществующий девятый разряд, но на этот раз из него единица не занимается, а в него переносится лишняя. Получается (1)00000000. Несуществующий разряд потом игнорируется. С точки зрения знаковой интерпретации получается, что 128 + 128 = 0. С точки зрения беззнаковой — что -128 + (-128) = 0, т.е. оба результата, как и можно было ожидать с самого начала, оказываются некорректными. Знаковые целые представлены в Delphi типами ShortInt(N=8, диапазон -128..127), SmallInt(N=16, диапазон -32 768..32 767), LongInt(N=32, диапазон -2 147 483 648..2 147 483 647) и Int64(N=64, диапазон -9 223 372 036 854 775 808..9 223 372 036 854 775 807). Примечание Далее приведены несколько примеров, иллюстрирующих сказанное. 3.1.2. Выход за пределы диапазона при присваиванииНачнем с рассмотрения простого примера (листинг 3.1. проект Assignment1 на компакт-диске). Листинг 3.1. Неявное преобразование знакового числа в беззнаковое при присваиванииprocedure TForm1.Button1Click(Sender: TObject); var X: Byte; Y: ShortInt; begin Y := -1; X := Y; Label1.Caption := IntToStr(X); end; При выполнении этого примера будет выведено значение 255. Здесь мы сталкиваемся с тем, что все разряды значения Yбез дополнительных проверок копируются в X, но если Yинтерпретируется как знаковое число, то X— как беззнаковое, а числам 255 и -1 в восьмиразрядном представлении соответствует одна и та же комбинация битов. Примечание Строго говоря, в Delphi предусмотрена защита от подобного присваивания. Если включить опцию Range checking (включается в окне Project/Options... на закладке Compiler или директивой компилятора {$R+}или {$RANGECHECKS ON}), то при попытке присвоения X := Yвозникнет исключение ERangeError. Но по умолчанию эта опция отключена (для повышения производительности — дополнительные проверки требуют процессорного времени), поэтому программа без сообщений об ошибке выполняет такое неправильное присваивание. В следующем примере (листинг 3.2, проект Assignment2 на компакт-диске) мы рассмотрим присваивание числу такого значения, которое не укладывается ни в знаковый, ни в беззнаковый диапазон. Листинг 3.2. Присваивание переменной значения, выходящего за рамки диапазонаprocedure TForm1.Button1Click(Sender: TObject); var X: Byte; Y: Word; begin Y := 1618; X := Y; Label1.Caption := IntToStr(X) end; На экране появится число 82. Разберемся, почему это происходит. Число 1618 в двоичной записи равно 00000110 01010010. При присваивании этого значения переменной Xстаршие восемь битов "некуда девать", поэтому они просто игнорируются. В результате в Хзаписывается число 01010010, т.е. 82. Разумеется, при включенной опции Range checking и в этом случае произойдет исключение ERangeError. Приведенные примеры показывают два основных источника неожиданностей, возникающих при присваивании значения целой переменной: 1. При смешении знаковых и беззнаковых чисел значение меняется из-за того, что старший бит интерпретируется то как знак числа, то как старший разряд. 2. При присваивании переменной значения, требующего большего числа разрядов, "лишние" разряды просто игнорируются. Все проблемы при присваивании сводятся к одному из этих случаев или к их комбинации. Все эти ситуации при выключенной опции Range checking приводят к ошибкам, которые бывает очень трудно обнаружить. Из-за этого рекомендуется включать эту опцию хотя бы на этапе отладки. В некоторых случаях возможность присваивания значений, выходящих за пределы диапазона переменной, может быть необходимой (например, для реализации "хитрых" алгоритмов или при сопряжении сторонних библиотек, одна из которых использует знаковые типы, другая — беззнаковые). Чтобы включение ERangeErrorне возникало, следует предусмотреть явное приведение типа. Например, следующий код работает без исключений при включенной опции Range checking (листинг 3.3). Листинг 3.3. Явное приведение типа для подавления исключений procedure TForm1.Button1Click(Sender: TObject); var X: Byte; Y: ShortInt; begin Y := -1; X := Byte(Y); Label1.Caption := IntToStr(X) end; В результате его выполнения переменная Xполучает значение 255. 3.1.3. Переполнение при арифметических операцияхПереполнением принято называть ситуацию, когда при операциях над переменной результат выходит за пределы ее диапазона. Рассмотрим следующий пример (листинг 3.4, проект Overflow1 на компакт-диске). Листинг 3.4. Переполнение при вычитанииprocedure TForm1.Button1Click(Sender: TObject); var X: Byte; begin X := 0; X := X - 1; Label1.Caption := IntToStr(X) end; Переменная Xполучит значение 255, поскольку при вычитании получается -1, что в беззнаковом формате соответствует 255. В принципе, этот пример практически эквивалентен примеру Assignment1, за исключением того, что значение -1 появляется в результате арифметических операций. Немного изменим этот пример — заменим оператор вычитания функцией Dec(листинг 3.5, пример Overflow2 на компакт-диске). Листинг 3.5. Переполнение при декременте {$R+} procedure TForm1.Button1Click(Sender: TObject); var X: Byte; begin X := 0; Dec(X); Label1.Caption := IntToStr(X); end; Результат получается тот же (X получает значение 255), но обратите внимание: несмотря на то, что опция Range checking включена, исключение не возникает. Этим пример Overflow2 отличается от Overflow1 — там исключение возникнет. Связано это с тем, что переполнение при использовании Decи подобных ей функций контролируется другой опцией — Overflow checking (в коде программы включается директивой {$Q+}или {$OVERFLOWCHECKS ON}). Эта опция по умолчанию тоже отключена и ее также рекомендуется включать при отладке. При ее включении в данном примере возникнет исключение EIntOverflow. 3.1.4. Сравнение знакового и беззнакового числаПосмотрим, что произойдет, если мы попытаемся сравнить знаковое и беззнаковое число (листинг 3.6, пример Compare1 на компакт-диске). Листинг 3.6. Сравнение "одинаковых" знакового и беззнакового числаprocedure TForm1.Button1Click(Sender: TObject); var X: Byte; Y: ShortInt; begin Y := -1; X := Y; if X = Y then Label1.Caption := 'Равно'; else Label1.Caption := 'He равно'; end; В окне появится надпись Не равно, хотя последовательность битов в переменных Xи Yбудет, как мы уже знаем, одинаковая. Надпись соответствует действительности — X(255) действительно не равно Y(-1). Разберемся, почему так происходит. Те, кто успел самостоятельно откомпилировать пример Compare1, могли заметить предупреждение компилятора на строке со сравнением: "Comparing signed and unsigned types — widened both operands". Это предупреждение все объясняет: компилятор, зная, что совпадение наборов битов не гарантирует равенство знакового и беззнакового выражения, сначала "расширяет" типы выражений до того типа, чей диапазон целиком вмещает оба требуемых диапазона и лишь затем выполняет сравнение. Это обеспечивает правильный результат сравнения, но требует дополнительных ресурсов, поэтому компилятор выдает предупреждение. Аналогичные действия компилятор выполнит при сравнении выражений типов Wordи SmallInt, а также LongIntи LongWord. Тип Int64 не имеет беззнакового аналога, поэтому операнды этого типа при сравнении компилятор не "расширяет". Явное приведение типов позволяет избавиться от операций по расширению типа и ограничиться побитовым сравнением (листинг 3.7. пример Compare2 на компакт-диске). Листинг 3.7. Явное приведение типов при сравненииprocedure TForm1.Button1Click(Sender: TObject); var X: Byte; Y: ShortInt; begin Y := -1; X := Y; if X = Byte(Y) then Label1.Caption := 'Равно' else Label1.Caption := 'Не равно'; end; При компиляции такого кода не выдается никаких предупреждений, но и результат сравнения будет неверным: Равно. Примечание 3.1.5. Неявное преобразование в цикле forРассмотрим программу (пример ForRange на компакт-диске), на форме которой находятся кнопка и панель, причем кнопка (это важно!) — не на панели, а на форме, а на панели нет никаких компонентов. Обработчик нажатия на кнопку выглядит следующим образом (листинг 3.8). Листинг 3.8. Обработчик нажатия кнопкиprocedure TForm1.Button1Click(Sender: TObject); var I: Cardinal; begin for I := 0 to Panel1.ControlCount - 1 do Panel1.Controls[I].Tag := 1; end; На первый взгляд кажется, что при нажатии на кнопку ничего не должно происходить, т.к. на панели никаких визуальных компонентов нет, и цикл forне должен выполниться ни разу. Тем не менее нажатие на кнопку вызывает исключение Access violation. При нулевом количестве компонентов на панели выражение Panel1.ControlCount - 1должно давать значение -1. Но поскольку переменная цикла имеет тип Сardinal, эта комбинация битов интерпретируется как 4 294 967 295, верхняя граница оказывается больше нижней, и цикл начинает выполняться, обращаясь к несуществующим элементам управления. Отсюда и ошибка. Ошибка исчезнет, если тип переменной Iизменить на Integer— в этом случае верхняя граница цикла получит корректное значение -1, и цикл действительно не выполнится ни разу. Если на панели будет находиться хотя бы один компонент, ошибки тоже не будет, потому что верхняя граница цикла не выйдет из диапазона неотрицательных чисел. Получается, что в ситуации, когда использование беззнакового типа кажется вполне безобидным (действительно, индексы списка не могут быть отрицательными), нас подстерегает "подводный камень", связанный с тем. что верхняя граница цикла может оказаться отрицательной и будет неявно приведена к большому положительному числу. Поэтому в цикле предпочтительнее переменная знакового типа Integer, а если по каким-то причинам приходится использовать переменную типа Cardinal, то необходимо внимательно следить за тем, какие значения принимают границы типа. Примечание Строго говоря, аналогичная проблема может возникнуть и со знаковыми типами, если границы цикла for переходят допустимый диапазон этих чисел, просто циклы, переменная которых принимает значения вблизи границ диапазона типа Integer, встречаются гораздо реже. 3.2. Неочевидные особенности вещественных чиселЕсли рассмотренные в предыдущих разделах особенности целых чисел могли быть неочевидными только начинающим, то вещественные числа могут преподнести сюрпризы даже достаточно опытным программистам, т.к. их поведение существенно дальше от интуитивных представлений, и эти неожиданности не ограничиваются выходом та пределы диапазона. Существующая литература по Delphi, в основном, считает этот вопрос несущественным и обходит его стороной, в результате чего программист, впервые столкнувшийся с одним из таких сюрпризов, впадает в недоумение и испытывает желание "попрыгать вокруг компьютера с бубном". Здесь мы попытаемся восполнить этот пробел и показать, что необъяснимые на первый взгляд явления на самом деле просты и предсказуемы, если известно, как реализуется вещественная арифметика компьютером. 3.2.1. Двоичные дробиДля начала — немного математики. В школе мы проходим два вида дробей простые и десятичные. Десятичные дроби, по сути дела, представляют собой разложение числа по степеням десяти. Так, запись 13,6704 означает число, равное 1·101 + 3·100 + 6·10-1 + 7·10-2 + 0·10-3 + 4·10-4. Но внутреннее представление всех чисел в компьютере, в том числе и вещественных, не десятичное, а двоичное. Поэтому он использует двоичные дроби. Они во многом похожи на десятичные, но основанием степени у них служит двойка. Так, двоичная дробь 101.1101 — это 1·22 + 0·21 + 1·20 + 1·2-1 + 1·2-2 + 0·2-3 + 1·2-4. В десятичном представлении это число равно 5,8125, в чем нетрудно убедиться с помощью любого калькулятора. Теперь вспомним научный формат записи десятичного числа. Первым в этой записи идет знак числа (плюс или минус). Дальше идет так называемая мантисса (число от 1 до 10). Затем идет экспонента (степень десяти, на которую надо умножить мантиссу, чтобы получить нужное число). Итак, уже упоминавшееся число 13,6704 запишется в этом формате как 1.36704·101 (или 1.36704E1 по принятым в компьютере правилам). Если записываемое число меньше единицы, экспонента будет отрицательной. Аналогичная запись существует и в двоичной системе. Так, 101.1101 запишется в виде 1.011101*1010 (везде использована двоичная форма записи, так что 1010 означает 22). Именно такое представление реализовано в компьютере. Двоичная точка в такой записи не остается на одном месте, а сдвигается на величину, указанную в экспоненте, поэтому такие числа называются числами с плавающей точкой (floating point numbers). 3.2.2. Вещественные типы DelphiВ Delphi существует четыре вещественных типа: Single, Double, Extendedи Real. Их общий формат одинаков (рис. 3.1, а). Знак — это всегда один бит. Он равен нулю для положительных чисел и единице для отрицательных. Что же касается размеров мантиссы и экспоненты, то именно в них и заключается различие между типами. Прежде чем перейти к конкретным цифрам, рассмотрим подробнее тип Real, сделав для этого небольшой экскурс в историю. Real— это стандартный тип языка Паскаль, присутствовавший там изначально. Когда создавался Паскаль, процессоры еще не имели встроенной поддержки вещественных чисел, поэтому все операции с данными типа Real сводились к операциям с целыми числами. Соответственно, размер полей в типе Realбыл подобран так, чтобы оптимизировать эти операции. а) общий вид вещественного числа  б) Двоичное представление числа типа Single  Рис. 3.1. Хранение вещественного числа в памяти Микропроцессор Intel 8086/88 и его улучшенные варианты — 80286 и 80386 — также не имели аппаратной поддержки вещественных чисел. Но у систем на базе этих процессоров была возможность подключения так называемого сопроцессора. Эта микросхема работала с памятью через шины основного процессора и обеспечивала аппаратную поддержку вещественных чисел. В системах средней руки гнездо сопроцессора обычно было пустым, т.к. это уменьшало цену (разумеется, вставить туда сопроцессор не было проблемой). Для каждого центрального процессора выпускались свои сопроцессоры, маркировавшиеся Intel 8087, 80287 и 80387 соответственно. Были даже сопроцессоры, выпускаемые другими фирмами. Они работали быстрее, чем сопроцессоры Intel, но появлялись на рынке позже. Тип вещественных чисел, поддерживаемый сопроцессорами, не совпадает с Real. Он определяется стандартом IEEE (Institute of Electrical and Electronics Engineers). Чтобы обеспечить в своих системах поддержку типов IEEE, Borland вводит в Turbo Pascal типы Single, Doubleи Extended. Extended— это основной для сопроцессора тип, a Singleи Doubleполучаются из него очень простым усечением. Система команд сопроцессора допускает работу с этими типами: при загрузке числа типа Singleили Doubleво внутренний регистр сопроцессора последний конвертирует их в Extended. Напротив, при выгрузке чисел этих типов из регистра в память сопроцессор усекает их до нужного размера. Внутренние же операции всегда выполняются с данными типа Extended(впрочем, из этого правила есть исключение, на котором мы остановимся позже, после детального рассмотрения формата различных типов). Singleи Doubleпозволяют экономить память. Ни один из них также не совпадает с типом Real. В системах с сопроцессорами новые типы обрабатываются заметно (в 2–3 раза) быстрее, чем Real(это с учетом того, что тип Realпосле соответствующего преобразования также обрабатывался сопроцессором; если же сравнивать обработку типа Extendedна машине с сопроцессором и Realна машине без сопроцессора, то там на отдельных операциях достигалась разница в скорости примерно в 100 раз). Чтобы программы с этими типами можно было выполнять и в системах без сопроцессора, была предусмотрена возможность подключать к ним программный эмулятор сопроцессора. Обработка этих типов эмулятором была медленнее, чем обработка Real. Начиная с 486-й серии Intel берет курс на интеграцию процессора и сопроцессора в одной микросхеме. Процент брака в микросхемах слишком велик, поэтому Intel идет на хитрость: если у микросхемы брак только в сопроцессорной части, то на этом кристалле прожигаются перемычки, блокирующие сопроцессор, и микросхема продается как процессор 80486SX, не имеющий встроенного сопроцессора (в отличие от полноценной версии, которую назвали 80486DX). Бывали и обратные ситуации, когда сопроцессор повреждений не имел, зато процессор был неработоспособен. Такие микросхемы превращали в "сопроцессор 80487". Но это уже из области экзотики, и, по имеющейся у нас информации, до России такой сопроцессор не дошел. Процессор Pentium во всех своих вариантах имел встроенный блок вычислений с плавающей точкой (FPU — Floating Point Unit), и отдельный сопроцессор ему не требовался. Таким образом, с приходом этого процессора тип Realостался только для обратной совместимости, а на передний план вышли типы Single, Doubleи Extended. Начиная с Delphi 4, тип Realстановится синонимом типа Double, а старый 6-байтный тип получает название Real48. Здесь и далее под словом Realмы будем понимать старый 6-байтный тип. Примечание Существует директива компилятора {$REALCOMPATIBILITY ON/OFF}, при включении которой (по умолчанию она отключена) Realстановится синонимом Real48, а не Double. Размеры полей для различных вещественных типов указаны в табл. 3.1. Таблица 3.1. Размеры полей в вещественных типах
Другие параметры вещественных типов, такие как диапазон и точность, можно найти в справке Delphi. 3.2.3. Внутренний формат вещественных чиселРассмотрим тип Single, т.к. он самый короткий и, следовательно, самый простой для понимания. Остальные типы отличаются от него только количественно. В дальнейшем числа в формате Singleмы будем записывать как s eeeeeeee mmmmmmmmmmmmmmmmmmmmmmm, где s означает знаковый бит, е — бит экспоненты, m — бит мантиссы. Порядок хранения битов в типе Single показан на рис. 3.1, б (по принятым в процессорах Intel правилам байты в многобайтных значениях переставляются так. что младший байт идет первым, а старший — последним, и вещественных чисел это тоже касается В мантиссе хранится двоичное число. Чтобы получить истинное значение мантиссы, к ней надо мысленно добавить слева единицу с точкой (т.е., например, мантисса 1010000000000000000000 означает двоичную дробь 1.101). Таким образом, имея 23 двоичных разряда, мы записываем числа с точностью до 24-х двоичных разрядов. Экспонента — по определению всегда целое число. Но способ записи экспоненты в вещественных числах не совпадает с рассмотренным ранее способом записи чисел со знаком. Ноль в этом представлении записывается как 01111111 (в обычном представлении это равно 127). Соответственно. 10000000 (128 в обычном представлении) означает единицу, а 01111110 (126) означает -1, и т. д. (т.е. из обычного беззнакового числа надо вычесть 127, и получится число, закодированное в экспоненте). Такая запись чиста называется нормализованной. Из описанных правил есть исключения. Так, если все биты экспоненты равны нулю (т.е. там стоит число -127), то к мантиссе перед ее началом надо добавлять не "1.", а "0." (денормализованная запись). Это позволяет увеличить диапазон вещественных чисел. Если бы этого исключения не было, то минимально возможное положительное число типа Singleбыло бы равно примерно 5,9·10-39. А так появляется возможность использовать числа до 1,4·10-45. Побочным эффектом этого является то, что числа, меньшие чем 1,17·10-38, представляются с меньшей, чем 24 двоичных разряда, точностью. Если все биты в экспоненте равны единице, а в мантиссе — нулю, то мы получаем комбинацию, известную как INF(от англ. Infinity — бесконечность). Эта комбинация используется тогда, когда результат вычислений превышает максимально допустимое форматом число. В зависимости от значения бита s бесконечность может быть положительной или отрицательной. Если же при такой экспоненте в мантиссе хоть один бит не равен нулю, такая комбинация называется NAN(Not A Number — не число). Попытки работы с комбинациями NANили INFприводят к ошибке времени выполнения. Для задания нуля все биты мантиссы и экспоненты должны быть равны нулю (формально это означает 0·10-127). С учетом описанных правил, если хотя бы один бит экспоненты не будет равен нулю (т.е. экспонента будет больше -127), запись будет считаться нормализованной, и нулевая мантисса будет рассматриваться как единица. Поэтому никакие другие комбинации значений мантиссы и экспоненты не могут дать ноль. Тип Doubleустроен точно так же, разница только в количестве разрядов и в том, какое значение экспоненты берется за ноль. Итак, мы имеем 11 разрядов для экспоненты. За ноль берется значение 1023. Несколько иначе устроен Extended. Кроме количественных отличий добавляется еще и одно качественное: в мантиссе явно указывается первый разряд. Это означает, что мантисса 1010… интерпретируется как 1.01, а не как 1.101, как это было в типах Singleи Float. Поэтому если 23-битная мантисса типа Singleобеспечивает 24-знаковую точность, а 52-битная мантисса Double— 53-битную, то 64-битная мантисса Extendedобеспечивает 64-х, а не 65-битную точность. Соответственно, при денормализованной форме записи первый разряд мантиссы явно содержит 0. За ноль экспоненты принимается значение 16 383. Тип Real, как уже упоминалось, стоит особняком. Во-первых, в нем биты следуют в другом порядке, а во-вторых, нет денормализованной формы. Мы не будем касаться внутреннего устройства типа Real, т.к. эта информация уже перестала быть актуальной. 3.2.4. "Неполноценный" ExtendedРанее мы отметили, что FPU всегда выполняет все операции в формате Extended, оговорившись при этом, что есть исключение из этого правила. Здесь мы рассмотрим это исключение. У FPU существует специальный двухбайтный регистр, называемый управляющим словом. Установка отдельных битов этого регистра диктует то или иное поведение при выполнении операций. Прежде всего, это связано с тем, какие исключения может возбуждать FPU. Другие биты этого регистра отвечают за то, как будут округляться числа, как FPU понимает бесконечность, — всё это можно при необходимости узнать из документации Intel. Нас же будут интересовать только два бита из этого слова: восьмой и девятый. Именно они определяют, как будут обрабатываться числа внутри сопроцессора. Если восьмой бит содержит единицу (так установлено по умолчанию), то десять байтов внутренних регистров сопроцессора будут задействованы полностью, и мы получим "полноценный" Extended. Если же этот бит равен нулю, то все определяется значением бита 9. Если он равен единице, то используется только 53 разряда мантиссы (остальные всегда равны нулю). Если же этот бит равен нулю — только 24 разряда мантиссы. Это увеличивает скорость вычислений, но уменьшает точность. Другими словами, точность работы сопроцессора может быть понижена до типа Doubleили даже Single. Но это касается только мантиссы, экспонента в любом случае будет содержать 15 бит, так что диапазон типа Extendedсохраняется в любом случае. Для работы с управляющим словом сопроцессора в модуле Systemописана переменная Default8087CWтипа Wordи процедура Set8087CW(CW: Word). При запуске программы в переменную Default8087CW записываетсято управляющее слово, которое установила система при запуске программы. Функция Set8087CWодновременно записывает новое значение в управляющее слово и в переменную Default8087CW. Такое поведение этой функции не всегда удобно — иногда бывает нужно сохранить старое значение переменной Default8087CW(впрочем, это несложно сделать, заведя дополнительную переменную). С другой стороны, если значение управляющею слова изменить, не используя Set8087CW(а в дальнейшем мы увидим, что такие изменения могут происходить помимо нашей воли), то с помощью функции Default8087CWпросто нет возможности узнать текущее значение управляющего слова. В Delphi 6 и выше появилась функция Get8087CW, позволяющая узнать значение именно контрольного слова, а не переменной Default8087CW. В более ранних версиях существовал единственный способ получить значение этого слова — встроенный в Delphi ассемблер. Итак, установить значение управляющего слова можно с помощью команды FLDCW, прочитать с помощью FNSTCW. Обе эти команды имеют один аргумент — переменную типа Word. Чтобы, например, установить 53-значную точность, не изменив при этом другие биты управляющего слова нужно выполнить такую последовательность команд: asm FNSTCW MyCW AND MyCW, 0FC00h OR MyCW, 200h FLDCW MyCW end; Начиная с Delphi 6, в модуле Mathпоявилась еще одна функция, позволяющая устанавливать точность FPU без манипуляции с отдельными битами управляющего слова — SetPrecisionMode. В зависимости от значения аргумента ( pmSingle, pmDoubleили pmExtended) она устанавливает требуемую точность. Современные сопроцессоры обрабатывают числа с такой скоростью, что при обычных вычислениях вряд ли может возникнуть необходимость в ускорении за счет точности — выигрыш будет ничтожен. Эта возможность необходима, в основном, в тех случаях, когда вычисления с плавающей точкой составляют значительную часть программы, а высокая точность не имеет принципиального значения (например, в 3D-играх). Однако забывать об этой особенности работы сопроцессора не следует, потому что она может преподнести один неприятный сюрприз, о котором чуть позже. 3.2.5. Бесконечные дробиИз школы мы все помним, что не каждое число может быть записано конечной десятичной дробью. Бесконечные дроби бывают двух видов: периодичные и непериодичные. Примером непериодичной дроби является число π, периодичной — число ⅓ или любая другая простая дробь, не представимая в виде конечной десятичной дроби. Примечание Вопрос о периодичности или непериодичности числа нас сейчас не интересует, нам достаточно знать, что не все числа можно представить в виде конечной десятичной дроби. При работе с такими числами мы всегда имеем не точное, а приближенное значение, поэтому ответ получается тоже приближенным. Это нужно учитывать в своих расчетах. До сих пор мы говорили только о десятичных бесконечных дробях. Но двоичные дроби тоже могут быть бесконечными. Даже более того, любое число, выражаемое конечной двоичной дробью, может быть также выражено и десятичной конечной дробью. Но существуют числа (например, 1/5), которые выражаются конечной десятичной дробью, но не могут быть выражены конечной двоичной дробью. Это и есть наиболее важное отличие аппаратной реализации вещественных чисел от наших интуитивных представлений. Теперь у нас достаточно теоретических знаний, чтобы перейти к рассмотрению конкретных примеров — "подводных камней", приготовленных вещественными числами. 3.2.6. "Неправильное" значениеСамый первый "подводный камень", на котором спотыкаются новички — это то, что вещественная переменная может получить не совсем то значение, которое ей присвоено. Рассмотрим это на простом примере (листинг 3.9, примеp WrongValue на компакт-диске). Листинг 3.9. Пример присваивания "неправильного" вещественного значенияprocedure TForm1.Button1Click(Sender: TObject); var R: Single; begin R := 0.1; Label1.Caption = FloatToStr(F); end; Что мы увидим, когда нажмем кнопку? Разумеется, не 0.1, иначе не было бы смысла писать этот пример. Мы увидим 0.100000001490116, т.е. расхождение в девятой значащей цифре. Из справки по Delphi мы знаем, что точность типа Single — 7–8 десятичных разряда, так что нас, по крайнем мере, никто не обманывает. В чем же причина? Просто число 0,1 не представимо в виде конечной двоичной дроби, оно равно 0,0(0011). И эта бесконечная двоичная дробь обрубается на 24-х знаках; мы получаем не 0,1, а некоторое приближенное число (какое именно — см. выше). А если мы присвоим переменной R не 0.1, а 0.5? Тогда мы получим на экране 0.5, потому что 0.5 предоставляется в виде конечной двоичной дроби. Немного поэкспериментировав с различными числами, мы заметим, что точно представляются те числа, которые выражаются в виде m/2n, где m, n — некоторые целые числа (разумеется, n не должно превышать 24, а то нам не хватит точности типа Single). В качестве упражнения предлагаем доказать, что любое целое число, для записи которого хватает 24-х двоичных разряда, может быть точно передано типом Single. Примечание Если в этом примере изменить тип переменной Rс Singleна Doubleили на Extended, на экран будет выведено 0.1. Но это не значит, что в переменную будет записано ровно 0.1 — это просто особенности работы функции FloatToStr, которая не учитывает столь малую разницу между 0,1 и переданным ей числом. 3.2.7. СравнениеТеперь попробуем сравнить значение переменной и константы, которую мы ей присвоили (листинг 3.10, пример Compare1 на компакт-диске). Листинг 3.10. Пример ошибки при сравнении вещественной переменной и константыprocedure TForm1.Button1Click(Sender: TObject); var R: Single; begin R := 0.1; if R = 0.1 then Label1.Caption := 'Равно' else Label1.Caption := 'He равно'; end; При нажатии кнопки мы увидим надпись Не равно. На первый взгляд это кажется абсурдом. Действительно, мы уже знаем, что переменная Rполучает значение 0.100000001490116 вместо 0.1. Но ведь "0.1" в правой части равенства тоже должно преобразоваться по тем же законам, т.к. работает аналогичный алгоритм. Тут самое время вспомнить, что FPU работает только с 10-байтным типом Extended, поэтому и левая, и правая часть равенства сначала преобразуется в этот тип, и лишь потом производится сравнение. То число, которое оказалось в переменной Rвместо 0.1, хотя и выглядит страшно, но зато представляется в виде конечной двоичной дроби. Информация же о том, что это на самом деле должно означать "0.1", нигде не сохранилась. При преобразовании этого числа в Extendedмладшие, избыточные по сравнению с типом Singleразряды мантиссы просто заполняются нулями, и мы снова получим то же самое число, только записанное в формате Extended. А "0.1" из правой части равенства преобразуется в Extendedбез промежуточного превращения в Single. Поэтому некоторые из младших разрядов мантиссы будут содержать единицы. Другими словами, мы получим хоть и не точное представление числа 0.1, но все же более близкое к истине, чем 0.100000001490116. Из-за таких хитрых преобразований оказывается, что мы сравниваем два близких, но все же не равных числа. Отсюда — закономерный результат в виде надписи Не равно. Тут уместна аналогия с десятичными дробями. Допустим, в одном случае мы делим 1 на три с точностью до трех знаков и получаем 0,333. Потом мы делим 1 на три с точностью до четырех знаков и получаем 0,3333. Теперь мы хотим сравнить эти два числа. Для этого приводим их к точности в четыре разряда. Получается, что мы сравниваем 0,3330 и 0,3333. Очевидно, что это разные числа. Если попробовать заменить число 0,1 на 0,5, то мы увидим надпись Равно. Полагаем, что читатели уже догадались, почему, но все же приведем объяснение. Число 0,5 — это конечная двоичная дробь. При прямом приведении ее к типу Extendedв младших разрядах оказываются нули. Точно такие же нули оказываются в этих разрядах при превращении числа 0,5 типа Singleв тип Extended. Поэтому в результате мы сравниваем два равных числа. Это похоже на процесс деления 1 на 4 с точностью до трех и до четырех значащих цифр. В первом случае получили бы 0,250, во втором — 0,2500. Приведя оба значения к точности в четыре знака, получим сравнение 0,2500 и 0,2500. Очевидно, что эти числа равны. 3.2.8. Сравнение разных типовТеперь попытаемся сравнить переменную не с константой, а с другой переменной (листинг 3.11, пример Compare2 на компакт-диске). Листинг 3.11. Пример ошибки при сравнении переменных разных типовprocedure TForm1.Button1Click(Sender: TObject); var R1: Single; R2: Double; begin R1 := 0.1; R2 := 0.1; if R1 = R2 then Label1.Caption := 'Равно' else Label1.Caption := 'He равно'; end; Почему этот пример также выдаст Не равно, понять проще, чем в предыдущем случае. При R1бесконечная дробь обрывается на 24-х разрядах, а при R2— на 53-х. Таким образом, в дополнительных по сравнению с типом Singleразрядах переменной R2будут единицы. При дополнении значений нулями до 10-байтной точности мы получим разные числа, что и определяет результат сравнения. Это напоминает ситуацию, когда мы сравниваем 0,333 и 0,3333, приводя их к точности в пять знаков: числа 0,33300 и 0,33330 не равны. Как и в предыдущем случае, замена 0,1 на 0,5 даст результат Равно. 3.2.9. Вычитание в циклеРассмотрим еще один пример, иллюстрирующий ситуацию, которая часто озадачивает начинающего программиста (листинг 3.12, пример Subtraction на компакт-диске). Листинг 3.12. Накапливание ошибки при вычитанииprocedure TForm1.Button1Click(Sender: TObject); var R: Single; I: Integer; begin R := 1; for I := 1 to 10 do R := R - 0.1; Label1.Caption := FloatToStr(R); end; В результате выполнения этого кода на экране появится -7.3015691270939E-8 вместо ожидаемого нуля. Объяснение этому достаточно очевидно, если вспомнить то, о чем мы говорили ранее. Число 0,1 не может быть передано точно ни в одном из вещественных типов, а при каждом вычислении происходит преобразование Singleв Extendedи обратно, причем последнее — с потерей точности. Эти потери приводят к тому, что мы получаем в результате не ноль, а "почти ноль". 3.2.10. Неожиданная потеря точностиИзменим в предыдущем примере тип переменной Rс Singleна Double. Значение, выводимое программой, станет 1.44327637948555E-16. Вполне логичный и предсказуемый результат, т.к. тип Doubleточнее, чем Single, и, следовательно, все вычисления имеют меньшую погрешность, мы просто обязаны получить более точный результат. Хотя, разумеется, абсолютная точность (т.е. ноль) для нас остается недостижимым идеалом. А теперь — вопрос на засыпку. Изменится ли результат, если мы заменим Doubleна более точный Extended? Ответ не такой однозначный, каким его хотелось бы видеть. В принципе, после такой замены вы должны получить -6.7762635780344E-20. Но в некоторых случаях от замены Doubleна Extendedрезультат не изменится, и вы снова получите 1.44327637948555Е-16. Это зависит от операционной системы и версии Delphi. Все дело в использовании "неполноценного" Extended. При запуске программы любая система устанавливает такое управляющее слово FPU, чтобы Extendedбыл полноценным. Но затем программа вызывает много разных функций Windows API. Какая-то (или какие-то) из этих многочисленных функций некорректно работают с управляющим словом, меняя его значение и не восстанавливая при выходе. Такая проблема встречается, в основном, в Windows 95 и старых версиях Windows 98. Также имеются сведения о том, что управляющее слово может "портиться" и в Windows NT, причем эффект наблюдался не сразу после установки системы, а лишь через некоторое время, после доустановки других программ. Проблема именно в некорректности поведения системных функций; значение управляющего слова, устанавливаемое системой при запуске программы, всегда одинаково. Таким образом, приходим к неутешительному выводу: к тем проблемам с вещественными числами, которые обусловлены особенностями их аппаратной реализации, добавляются еще и ошибки операционной системы. Правда, радует то, что в последнее время эти ошибки встречаются крайне редко — видимо, новые версии системы от них избавлены. Тем не менее полностью исключать такую возможность нельзя, особенно если ваша программа будет запускаться на старой технике с устаревшими системами. Чтобы приведенный пример всегда выдавал правильное значение -6.7762635780344E-20, достаточно поставить в начале нашей процедуры Set8080CW(Get8087CW or $0100), и программа в любой системе будет устанавливать сопроцессор в режим максимальной точности. Примечание Раз уж мы заговорили об управляющем слове, давайте немного поэкспериментируем с ним. Изменим первую строчку на Set8087CW(Get8087CW and $FCFF or $0200). Тем самым мы перевезем сопроцессор в режим 53-разрядной точности представления мантиссы. Теперь в любой системе мы увидим 1.44327637948555Е-16, несмотря на использование Extended. Если же мы изменим первую строчку на Set8087CW(Get8087CW and $FCFF), то будем работать в режиме 24-разрядной точности. Соответственно, в любой системе будет результат -7.3015691270939Е-8. Заметим, что при загрузке в 10-байтный регистр сопроцессора числа типа Extendedв режиме пониженной точности "лишние" биты не обнуляются. Только результаты математических операций представляются с пониженной точностью. Кроме того, при сравнении двух чисел также учитываются все биты, независимо от точности. Поэтому код, приведенный в листинге 3.10 при выборе любой точности даст Не равно. 3.2.11. Борьба с потерей точности в VCLВ том, что описанная проблема с потерей точности встречается все реже, есть заслуга и разработчиков VCL. Зная, вызовы каких функций могут привести к изменению управляющего слова FPU, они перед этими вызовами запоминают управляющее слово, а затем восстанавливают. В более поздних версиях Delphi количество таких "оберток" больше, чем в ранних, поэтому чем новее версия Delphi, тем меньше шанс столкнуться с описанной проблемой. Здесь мы рассмотрим несколько примеров из исходного кода стандартных модулей Delphi 2007. Для динамической загрузки DLL предназначена API-функция LoadLibrary. В модуле SysUtilsдля этой функции предлагается обертка, называющаяся SafeLoadLibrary(листинг 3.13). Листинг 3.13. Функция SysUtils.SafeLoadLibrary { SafeLoadLibrary calls LoadLibrary, disabling normal Win32 error message popup dialogs if the requested file can't be loaded. SafeLoadLibrary also preserves the current FPU control word (precision, exception masks) across the LoadLibrary call (in case the DLL you're loading hammers the FPU control word in its initialization, as many MS DLLs do) } function SafeLoadLibrary(const Filename: string; ErrorMode: UINT): HMODULE; var OldMode: UINT; FPUControlWord: Word; begin OldMode := SetErrorMode(ErrorMode); try asm FNSTCW FPUControlWord end; try Result := LoadLibrary(PChar(Filename)); finally asm FNCLEX FLDCW FPUControlWord end; end; finally SetErrorMode(OldMode); end; end; Как видно из комментария, проблема в том, что многие системные библиотеки изменяют управляющее слово FPU при своей инициализации. В функции CreateADOObject(внутренняя функция модуля ADODB) тоже сохраняется и восстанавливается управляющее слово (листинг 3.14). Листинг 3.14. Функция CreateADOObjectмодуля ADODB function CreateADOObject(const ClassID: TGUID): IUnknown; var Status: HResult; FPUControlWord: Word; begin asm FNSTCW FPUControlWord end; Status := CoCreateInstance(ClassID, nil, CLSTX_INPROC_SERVER or CLSCTX_LOCAL_SERVER, IUnknown, Result); asm FNCLEX FLDCW FPUControlWord end; if (Status = REGDB_E_CLASSNOTREG) then raise Exception.CreateRes(@SADOCreateError) else OleCheck(Status); end; Здесь восстанавливать управляющее слово приходится после вызова системной функции CoCreateInstance, создающей СОМ-объект. Но, судя по тому, что больше нигде при вызове CoCreateInstanceтакой код не используется, проблема не в самой функции, а в тех конкретных ADO-объектах, которые создаются здесь с ее помощью. Аналогичную защиту можно обнаружить в модуле Dialogs, в методе TCommonDialog.TaskModalDialog. Комментарий к этой защите гласит: "Avoid FPU control word change in NETRAP.dll, NETAPI32.dll, etc". В модуле Windowsособым образом импортируются функции CreateWindowи CreateWindowEx, которые, видимо, тоже были замечены в некорректном обращении с управляющим словом FPU. Вот как, например, выглядит импорт функции CreateWindowEx(листинг 3.15). Листинг 3.15. Импорт функции CreateWindowExмодулем Windows function _CreateWindowEx(dwExStyle: WORD; lpClassName: PChar; lpWindowName: PChar; dwStyle: DWORD; X, Y, nWidth, nHeight: Integer; hWndParent: HWND; hMenu: HMENU; hInstance: HINST; lpParam: Pointer): HWND; stdcall; external user32 name 'CreateWindowExA'; function CreateWindowEx(dwExStyle: DWORD; lpClassName: PChar; lpWindowName: PChar; dwStyle: DWORD; X, Y, nWidth, nHeight: Integer; hWndParent: HWND; hMenu: HMENU; hInstance: HINST; lpParam: Pointer): HWND; var FPUCW: Word; begin FPUCW := Get8087CW; Result := _CreateWindowEx(dwExStyle, lpClassName, lpWindowName, dwStyle, X, Y, nWidth, nHeight, hWndParent, hMenu, hInstance, lpParam); Set8087CW(FPUCW); end; Модуль Windowsимпортирует функцию CreateWindowExAиз библиотеки user32.dll, но дает ей измененное название и не показывает ее в своем интерфейсе. Вместо этого он экспортирует другую функцию с названием CreateWindowEx(и аналогичную с названием CreateWindowExA), которая является оберткой над настоящей CreateWindowExAи обеспечивает сохранение значения управляющего слова FPU. Аналогичным способом импортируется и Unicode-вариант функции. Таким образом, стандартные библиотеки обеспечивают вызов безопасного варианта CreateWindowExв любой программе. Примечание 3.2.12. Машинное эпсилонКогда мы имеем дело с вычислениями с ограниченной точностью, возникает такой парадокс. Пусть, например, мы считаем с точностью до трех значащих цифр. Прибавим к числу 1,00 число 1,00·10-4. Если бы все было честно, мы получили бы 1,0001. Но у нас ограничена точность, поэтому мы вынуждены округлять до трех значащих цифр. В результате получается 1,00. Другими словами, к некоторому числу мы прибавляем другое число, большее нуля, а в результате из-за ограниченной точности мы получаем то же самое число. Наименьшее положительное число, которое при добавлении его к единице дает результат, не равный единице, называется машинным эпсилон. Понятие машинного эпсилон у новичков нередко путается с понятием наименьшего числа, которое может быть записано в выбранном формате. Это неправильно. Машинное эпсилон определяется только размером мантиссы, а минимально возможное число оказывается существенно меньше из-за сдвига плавающей двоичной точки с помощью экспоненты. Прежде чем искать машинное эпсилон программно, попытаемся найти его из теоретических соображений. Итак, мантисса типа Extendedсодержит 64 разряда. Чтобы закодировать единицу, старший бит мантиссы должен быть равен 1 (денормализованная запись), остальные биты — нулю. Очевидно, что при такой записи наименьшее из чисел, для которых выполняется условие x > 1, получается, когда самый младший бит мантиссы тоже будет равен единице, т.е. х = 1,00...001 (в двоичном представлении, между точкой и младшей единицей 62 нуля). Таким образом, машинное эпсилон равно х-1, т.е. 0.00...001. В более привычной десятичной форме записи это будет 2-63, т.е. примерно 1,084·10-19. Листинг 3.16 показывает, как можно найти это число (пример Epsilon на компакт-диске). Листинг 3.16. Поиск машинного эпсилонprocedure TForm1.Button1Click(Sender: TObject); var R: Extended; I: Integer; begin R := 1; while 1 + R/2 > 1 do R := R / 2; Label1.Caption := FloatToStr(R); end; Запустив этот код, мы получим на экране 1.0842021724855Е-19 в полном соответствии с нашими теоретическими выкладками. Примечание А теперь изменим тип переменной Rс Extendedна Double. Результат не изменится. На Single— опять не изменится. Но такое поведение лишь на первый взгляд может показаться странным. Давайте подробнее рассмотрим выражение 1 + R / 2 > 1. Итак, все вычисления (в том числе и сравнение) сопроцессор выполняет с данными типа Extended. Последовательность действий такова: число Rзагружается в регистр сопроцессора, преобразуясь при этом к типу Extended. Дальше оно делится на 2, а затем к результату прибавляется 1, и все это в Extended, никакого обратного преобразования в Single или Doubleне происходит. Затем это число сравнивается с единицей. Очевидно, что результат сравнения не должен зависеть от исходного типа R, т.к. диапазона даже типа Singleвполне хватает, чтобы разместить машинное эпсилон. 3.2.13. Методы решения проблемПодведем итоги сказанному. Значения, которые мы получаем, могут отличаться от ожидаемых, даже если речь идет о простом присваивании. Во многих случаях (например, в научных расчетах) это несущественно, т.к. сам метод расчета дает еще большую погрешность. Проблемы начинаются там, где мы хотим вывести число на экран или сравнить его с другим. Универсальных рецептов на все случаи жизни не существует, но во многих ситуациях помогают следующие советы: □ Если ваша задача — просто получить "красивое" представление числа на экране, то функцию FloatToStrзаменяйте на ее более мощный аналог FloatToStrFили на функцию Format— они позволяют указать желаемое количество символов после точки. □ Сравнение вещественных чисел следует выполнять с учетом погрешности, т.е. вместо if а = b… писать if Abs(а - b) < Ерs…, где Eps— некоторая величина, задающая допустимую погрешность (в модуле Math, начиная с Delphi 6, существует функция SameValue, с помощью которой это же условие можно записать как if SameValue(a, b, Eps)…). □ Для денежных расчетов следует выбирать тип Currency, реализующий число с фиксированной, а не плавающей, десятичной точкой. Отметим также, что не следует пытаться решить проблему неточного представления числа (0,100000001490116 вместо 0,1) с помощью функции RoundTo, поскольку эта функция не может обеспечить точность бо́льшую, чем точность аппаратного представления вещественных чисел. 3.3. Тонкости работы со строкамиВ этом разделе мы рассмотрим некоторые тонкости работы со строками, которые позволяют лучше понять, какой код генерирует компилятор при некоторых, казалось бы, элементарных действиях. Не все приведенные здесь примеры работают не так, как можно было бы ожидать, так что этот материал немного выходит за рамки главы. Но "подводные камни" здесь мы тоже встретим. 3.3.1. Виды строк в DelphiДля работы с кодировкой ANSI в Delphi существует три вида строк: AnsiString, ShortStringи PChar. Различие между ними заключается в способе хранения строки, а также выделения и освобождения памяти для нее. Зарезервированное слово stringпо умолчанию означает тип AnsiString, но если после нее следует число в квадратных скобках, то это означает тип ShortString, а число — ограничение по длине. Кроме того, существует опция компилятора Huge strings (управляется также директивами компилятора {$H+/-}и {$LONGSTRINGS ON/OFF}, которая по умолчанию включена, но если ее выключить, то слово stringстанет эквивалентно ShortString; или, что то же самое, string[255]. Эта опция введена для обратной совместимости с Turbo Pascal, в новых программах отключать ее нет нужды. Внутреннее устройство этих типов данных иллюстрирует рис. 3.2. 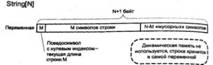 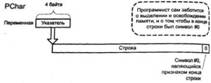 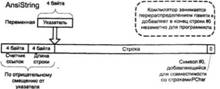 Рис. 3.2. Устройство различных строковых типов Delphi Наиболее просто устроен тип ShortString. Это массив символов с индексами от 0 до N, где N — число символов, указанное при объявлении переменной (в случае использования идентификатора ShortStringN явно не указывается и равно 255). Нулевой элемент массива хранит текущую длину строки, которая может быть меньше или равна объявленной (эту длину мы будем далее обозначать M), элементы с индексами от 1 до M — это символы, составляющие строку. Значения элементов с индексами M+1..N не определены. Все стандартные функции для работы со строками игнорируют эти символы. В памяти такая переменная всегда занимает N+1 байтов. Ограничения типа ShortStringочевидны: на хранение длины отводится только один байт, поэтому такая строка не может содержать больше 255 символов. Кроме того, такой способ записи длины не совпадает с принятым в Windows, поэтому ShortStringнесовместим с системными строками. В системе приняты так называемые нуль-терминированные строки: строка передается указателем на ее первый символ, длина строки отдельно нигде не хранится, признаком конца строки считается встретившийся в цепочке символов #0. Длина таких строк ограничена только доступной памятью и способом адресации (т.е. в Windows теоретически это 4 294 967 295 символов). Для работы с такими строками предусмотрен тип PChar. Переменная такого типа является указателем на начало строки. В литературе нередко можно встретить утверждение, что PChar = ^Сhar, однако это неверно: тип PCharвстроен в компилятор и не выводится из других типов. Это позволяет выполнять с ним операции, недопустимые для других указателей. Во-первых, если P— переменная типа PChar, то допустимо обращение к отдельным символам строки с помощью конструкции P[N], где N— целочисленное выражение, определяющее номер символа (в отличие от типа ShortString, здесь символы нумеруются с 0, а не с 1). Во-вторых, к указателям типа PCharразрешено добавлять и вычитать целые числа, смещая указатель на соответствующее число байтов вверх или вниз (здесь речь идет только об операторах "+" и "-"; адресная арифметика с помощью процедур Inc иDec доступна для любых типизированных указателей, а не только для PChar). При работе с PCharпрограммист целиком и полностью отвечает за выделение памяти для строки и за ее освобождение. Именно это и служит основным источником ошибок у новичков: они пытаются работать с такими строками так же, как и с AnsiString, надеясь, что операции с памятью будут выполнены автоматически. Это очень грубая ошибка, способная привести к самым непредсказуемым последствиям. Хотя программист имеет полную свободу выбора в том, как именно выделять и освобождать память для нуль-терминированных строк, в большинстве случаев самыми удобными оказываются специально предназначенные для этого функции StrNew, StrDisposeи т.п. Их преимущество заключается в том, что менеджер памяти выделяет чуть больше места, чем требуется для хранения строки, и в эту дополнительную память записывается, сколько байтов было выделено. Благодаря этому функция StrDisposeудаляет ровно столько памяти, сколько было выделено, даже если в середину выделенного блока был записан символ #0, уменьшающий длину строки. Компилятор также позволяет рассматривать статические массивы типа Char, начинающиеся с нулевого индекса, как нуль-терминированные строки. Такие массивы совместимы с типом PChar, что позволяет обойтись без использования динамической памяти при работе со строками. Тип AnsiStringобъединяет достоинства типов ShortStringи PChar: строки имеют фактически неограниченную длину, заботиться о выделении памяти для них не нужно, в их конец автоматически добавляется символ #0, что делает их совместимыми с системными строками (впрочем, эта совместимость не абсолютная; как и когда можно использовать AnsiStringв функциях API, мы рассматривали в разд. 1.1.13.). Переменная типа AnsiString— это указатель на первый символ строки, как и в случае PChar. Разница в том, что перед этой строкой в память записывается дополнительная информация: длина строки и счетчик ссылок. Это позволяет компилятору генерировать код, автоматически выделяющий, перераспределявший и освобождающий память, выделяемую для строки. Работа с памятью происходит совершенно прозрачно для программиста, в большинстве случаев со строками AnsiStringможно работать, вообще не задумываясь об их внутреннем устройстве. Символы в таких строках нумеруются с единицы, чтобы облегчить перенос старых программ, использовавших строки типа ShortString. Счетчик ссылок позволяет реализовать то, что называется copy-on-demand, копирование по необходимости. Если у нас есть две переменные S1, S2типа AnsiString, присваивание вида S1 := S2не приводит к копированию всей строки. Вместо этого в указатель S1копируется значение указателя S2, а счетчик ссылок строки увеличивается на единицу. В дальнейшем, если одну из этих строк потребуется модифицировать, она сначала будет скопирована (а счетчик ссылок оригинала, естественно, уменьшен) и только потом изменена, чтобы это не затрагивало остальные переменные. Далее мы рассмотрим, какие проблемы могут возникнуть при использовании строк разного вида. 3.3.2. Хранение строковых литераловЛитералами называются значения, записываемые в программе буквально. В частности, строковые литералы в Delphi — это последовательности символов, заключенных в кавычки или записанных в виде ANSI-кодов с использованием префикса #. Когда в программе встречается строковый литерал, компилятор должен поместить его в какую-либо область памяти, чтобы это значение стало доступным программе. Компилятор Delphi размещает строковые литералы в сегменте кода, в участках, управление которым никогда не передается. В данном разделе мы рассмотрим, к каким последствиям это может привести. Положим на форму пять кнопок и напишем следующие обработчики для нажатия на них (листинг 3.17, пример Constants на компакт-диске). Листинг 3.17. Примеры работы со строковыми литераламиprocedure TForm1.Button1Click(Sender: TObject); var P: PChar; begin P := 'Xest'; P[0] := 'T'; { * } Label1.Caption := P; end; procedure TForm1.Buttom2Click(Sender: TObject); var S: string; P: PChar; begin S:= 'Xest'; P := PChar(S); P[0] := 'T'; { * } Label1.Caption := P; end; procedure TForm1.Button3Click(Sender: TObject); var S: string; begin S := 'Xest'; S[1] := 'T'; Label1.Caption := S; end; procedure TForm1.Button4Click(Sender: TObject); var S: ShortString; begin S := 'Xest'; S[1] := 'T'; Label1.Caption := S; end; procedure TForm1.Button5Click(Sender: TObject); var S: ShortString; P: PChar; begin S := 'Xest'; P := @S[1]; P[0] := 'T'; Label1.Caption := P; end; В этом примере только нажатие на третью и четвертую кнопку приводит к появлению надписи Test. Первые два обработчика вызывают исключение Access violation в строках, отмеченных звездочками, а при нажатии пятой кнопки программа обычно работает без исключении (хотя в некоторых случаях оно все же может возникнуть), но к слову "Test" добавляется какой-то мусор. Разберемся, почему так происходит. Встретив в первом обработчике литерал 'Xest'и определив, что он относится к типу PChar, компилятор выделяет в подходящей области сегмента кода пять байтов (четыре значащих символа и один завершающий ноль), а в указатель Pзаносится адрес этого литерала. Сегмент кода доступен только для чтения, прав на его изменение система программе в целях безопасности не дает, поэтому попытка изменить то, что находится в этом сегменте, приводит к закономерному результату — выдаче сообщения "Access violation". В обработчике второй кнопки происходит почти то же самое, с той лишь разницей. что для литерала выделяется на восемь байтов больше: т.к. в данном случае литерал имеет тип AnsiString, ему нужны еще 4 байта для хранения длины и 4 — для счетчика ссылок. В переменную Sзаписывается указатель на этот литерал. Приводя эту переменную к типу PChar, мы, по сути, просто копируем этот указатель в переменную P, а дальше происходит то же самое — попытка изменить страницу памяти, доступную программе только для чтения с тем же самым результатом. В третьем случае литерал, как и раньше, размещается в сегменте кода. Счетчик ссылок у таких литералов всегда равен -1 — это значение указывает менеджеру памяти, что это константа, которая не может быть изменена и память для которой не нужно освобождать. Поэтому при любой попытке изменить переменную, которой присвоен литерал, срабатывает механизм копирования по необходимости: для строки выделяется место в динамической памяти, затем значение литерала копируется в эту область, обновляется значение указателя S, а затем выполняется изменение копии, находящейся в динамической памяти. Так как эта память доступна и для чтения, и для записи, исключение не возникает, и все работает так, как и было задумано. В четвертом случае литерал также хранится в сегменте кода, но работы с указателем уже нет. Этот литерал занимает там пять байтов: один байт на длину и четыре — на символы. Переменная Sразмешается в стеке, занимая там 256 байтов, а присваивание ей литерала — это копирование значения литерала из сегмента кода в область памяти, занятую переменной. Таким образом, в дальнейшем мы работаем не с константой в сегменте кода, а с ее копией в стеке, которую можно без проблем модифицировать. В пятом случае мы получаем указатель на этот участок стека. Обратите внимание, что приведение типов в данном случае не работает: для записи в Pадреса первого символа строки приходится использовать оператор получения адреса @. Модификация строки проходит, как и в предыдущем случае, успешно, но при присваивании выражения типа PCharсвойству типа AnsiStringдлина строки определяется по правилам, принятым для PChar, т.е. строка сканируется до обнаружения нулевого символа. Но посколькуShortString "не отвечает" за то, что будет содержаться в неиспользуемых символах, там может остаться всякий мусор от предыдущего использования стека. Никакой гарантии, что сразу после последнего символа будет #0, нет. Отсюда и появление непонятных символов на экране. Общий вывод таков: пока мы не вмешиваемся в работу компилятора с типами ShortStringи AnsiString, получаем ожидаемый результат. Работа с этими же строками через PCharв обход стандартных механизмов приводит к появлению проблем. Кроме того, при работе со строками PCharнеобходимо четко представлять, где и как выделяется для них память, иначе можно получить неожиданную ошибку. 3.3.3. Приведение литералов к типу PCharВ разд. 1.1.13 мы уже говорили, что когда у функции есть параметр типа PChar, и этот параметр не будет изменяться функцией, при вызове ей можно передавать строковый литерал (см. листинг 1.20). Компилятор размещает литерал в сегменте кода и передает функции указатель на эту память. В примерах кода, приведенных на различных сайтах, можно нередко встретить такую ситуацию, когда литерал, передаваемый в качестве параметра типа PChar, явно приводится к этому типу. Разберемся, что это дает. Для этого положим на форму четыре кнопки и напишем в обработчиках их нажатия следующий код (листинг 3.18. пример PCharLitна компакт-диске). Листинг 3.18. Приведение литералов к типу PChar procedure TForm1.Button1Click(Sender: TObject); begin Application.MessageBox('Text', nil, 0); end; procedure TForm1.Button2Click(Sender: TObject); begin Application.MessageBox('A', nil, 0); end; procedure TForm1.Button3Click(Sender: TObject); begin Application.MessageBox(PChar('Text'), nil, 0); end; procedure TForm1.Button4Click(Sender: TObject); begin Application.MessageBox(PChar('A'), nil, 0); end; Метод TApplication.MessageBoxпо каким-то непонятным причинам имеет параметры типа PCharвместо string, и мы этим воспользуемся. При его вызове будет показано диалоговое окно с текстом, переданным в качестве первого параметра (в заголовке будет написано Ошибка, т.к. второй параметр у нас nil). Нажатие на первую и вторую кнопку не приводит ни к каким неожиданностям — мы видим на экране Text и А соответственно. Теперь перейдем к коду с явным приведением литерала к PChar. Нажатие на третью кнопку к сюрпризам не приведет, а вот нажатие на четвертую даст исключение Access violation. Происходит это потому, что тип литерала зависит не только от его вида, но и оттого, в каком контексте он упомянут. Например, в предыдущем разделе мы видели, что литерал 'Xest'мог иметь тип stringили PCharв зависимости от того, какой переменной он присваивался. Там, где явного приведения типов нет, тип литерала однозначно определяется по типу формального параметра, и в обработчиках нажатия первых двух кнопок компилятор создает правильные литералы 'Text'и 'А'типа PChar. Явное приведение литерала к типу PCharменяет контекст, в котором литерал упомянут, и компилятор может сделать неправильный вывод о его типе. В обработчике третьей кнопки компилятор правильно понимает, что литерал имеет тип PCharи генерирует код, полностью эквивалентный коду обработчика первой кнопки. А вот в случае приведения к типу PCharлитерала 'А'компилятор принимает этот литерал не за строковый, а за символьный (т.е. за литерал типа Char), состоящий из одного символа без всяких добавлений длины, символа #0и т.п. При приведении выражения типа Charк любому указателю (в том числе и к PChar) оно рассматривается как выражение любого порядкового типа, и его численное значение становится численным значением указателя. В нашем случае это символ с кодом 65 ($41 в шестнадцатиричной записи), поэтому в функцию передается указатель $00000041. Такой указатель указывает на ту область виртуальной памяти, которая никогда не отображается на физическую память, поэтому его использование приводит к ошибке Access violation. Итак, мы увидели, что явное приведение литерала к типу PCharлибо никак не отражается на генерируемом компилятором коде (в случае литералов из нескольких символов), либо приводит к генерированию заведомо некорректного кода (в случае односимвольных литералов). Если еще учесть, что приведение литералов к PCharзагромождает код, легко сделать вывод, что приводить литералы к PCharне нужно, поскольку это потенциальный источник проблем и признак плохого оформления кода. 3.3.4. Сравнение строкДля типов PCharи AnsiString, которые являются указателями, понятие равенства двух строк может толковаться двояко: либо как равенство указателей, либо как равенство содержимого памяти, на которую эти указатели указывают. Второй вариант предпочтительнее, т.к. он ближе к интуитивному понятию равенства строк. Для типа AnsiStringреализован именно этот вариант, т.е. сравнивать такие строки можно, ни о чем не задумываясь. Более сложные ситуации мы проиллюстрируем примером Companions. В нем одиннадцать кнопок, и обработчик каждой из них иллюстрирует одну из возможных ситуаций. Начнем со сравнения двух строк типа PChar(листинг. 3.19). Листинг 3.19. Сравнение строк типа PChar procedure TForm1.Button1Click(Sender: TObject); var P1, P2: PChar; begin P1 := StrNew('Test'); P2 := StrNew('Test'); if P1 = P2 then Label1.Caption := 'Равно'; else Label1.Caption := 'Не равно'; StrDispose(P1); StrDispose(P2); end; В данном примере мы увидим надпись Не равно. Это происходит потому, что в этом случае сравниваются указатели, а не содержимое строк, а указатели здесь будут разные. Попытка сравнить строки с помощью оператора сравнения — весьма распространенная ошибка у начинающих. Для сравнения таких строк следует применять специальную функцию — StrComp. Следующий пример, на первый взгляд, в плане сравнения ничем не отличается от только что рассмотренного (листинг 3.20). Листинг 3.20. Сравнение строк типа PChar, заданных одинаковыми литералами procedure TForm1.Button2Click(Sender: TObject); var P1, P2: PChar; begin P1 := 'Test'; P2 := 'Test'; if P1 = P2 then Label1.Caption := 'Равно' else Label1.Caption := 'Не равно'; end; Разница только в том, что строки хранятся не в динамической памяти, a в сегменте кода. Тем не менее на экране появится надпись Равно. Это происходит, разумеется, не потому, что сравнивается содержимое строк, а потому, что в данном случае два указателя оказываются равными. Компилятор поступает достаточно интеллектуально: видя, что в разных местах указаны литералы с одинаковым значением, он выделяет для такого литерала место только один раз, а потом помещает в разные указатели один адрес. Поэтому сравнение дает правильный (с интуитивной точки зрения) результат. Такое положение дел только запутывает ситуацию со сравнением PChar: написав подобный тест, человек может сделать вывод, что строки PCharсравниваются не по указателю, а по значению, и действовать под руководством этого заблуждения. Раз уж мы столкнулись с такой особенностью компилятора, немного отвлечемся от сравнения строк и "копнем" этот вопрос немного глубже. В частности, выясним, распространяется ли "интеллект" компилятора на литералы типа AnsiString(листинг 3.21). Листинг 3.21. Сравнение переменных типа AnsiStringкак указателей procedure TForm1.Button3Click(Sender: TObject); var S1, S2: string; begin S1 := 'Test'; S2 := 'Test'; if Pointer(S1) = Pointer(S2) then Label1.Caption := 'Равно' else Label1.Caption := 'He равно'; end; В этом примере на экран будет выведено Равно. Как мы видим, указатели равны, т.е. и здесь компилятор проявил "интеллект". Рассмотрим чуть более сложный случай (листинг 3.22). Листинг 3.22. Сравнение переменныхAnsiStringи PCharкак указателей procedure TForm1.Button4Click(Sender: TObject); var P: PChar; S: string; var S := 'Test'; P := 'Test'; if Pointer(S) = P then Label1.Caption := 'Равно' else Label1.Caption := 'He равно'; end; В этом случае указатели окажутся не равны. Действительно, с формальной точки зрения литерал типа AnsiStringотличается от литерала типа PChar: в нем есть счетчик ссылок (равный -1) и длина. Однако если забыть с существовании этой добавки, эти два литерала одинаковы: четыре значащих символа и один #0, т.е. компилятор, в принципе, мог бы обойтись одним литералом. Тем не менее на это ему "интеллекта" уже не хватило. Рассмотрим еще один пример: сравнение строк по указателям (листинг 3.23). Листинг 3.23. Сравнение глобальных переменных типа AnsiStringкак указателей var GS1, GS2: string; procedure TForm1.Button5Click(Sender: TObject); begin GS1 := 'Test'; GS2 := 'Test'; if Pointer(GS1) = Pointer(GS2) then Label1.Caption := 'Равно'; else Label1.Caption := 'Не равно'; end; Этот пример отличается от приведенного в листинге 3.21 только тем, что теперь переменные глобальные, а не локальные. Однако этого достаточно, чтобы результат оказался другим — на экране мы увидим надпись Не равно. Для глобальных переменных компилятор всегда создаст уникальный литерал, на обнаружение одинаковых литералов ему "интеллекта" не хватает. Более того, если поставить точки останова в методах Button3Clickи Button4Click, легко убедиться, что указатель, который будет помещен в переменную Sв методе Button4Click, отличается от того, который будет помещен в переменные S1и S2в методе Button3Click, хотя литералы в обоих случаях одинаковые. Компилятор умеет обнаруживать равенство литералов типа AnsiStringтолько в пределах одной функции. Теперь посмотрим, что будет с глобальными переменными типа PCharпри присваивании им одинакового литерала (листинг 3.24). Листинг 3.24. Сравнение глобальных переменных типа PChar var GP1, GP2: PChar; procedure TForm1.Button6Click(Sender: TObject); begin GP1 := 'Test'; GP2 := 'Test'; if GP1 = GP2 then Label1.Caption := 'Равно' else Label1.Caption := 'He равно'; end; После выполнения этого кода мы увидим надпись Равно, т.е. здесь компилятор смог обнаружить равенство литералов, несмотря на то, что переменные глобальные. Однако переменные типа PChar, которым присваиваются одинаковые литералы в разных функциях, как и переменные типа AnsiString, получат разные значения. Но вернемся к сравнению строк. Как мы знаем, строки AnsiStringсравниваются по значению, а PChar— по указателю. А что будет, если сравнить AnsiStringс PChar? Ответ на этот вопрос даёт листинг 3.25. Листинг 3.25. Сравнение переменных типа AnsiStringи PChar procedure TForm1.Button7Click(Sender: TObject); var P: PChar; S: string; begin S := 'Test'; P := 'Тest'; it S = Р then Label1.Caption := 'Равно' else Label1.Caption := 'Не равно'; end; Этот код выдаст Равно. Как мы знаем из предыдущих примеров (см. листинг 3.22), значения указателей не будут равны, следовательно, производится сравнение по содержанию, т.е. именно то, что к требуется. Если исследовать код, который генерирует компилятор, то можно увидеть, что сначала неявно создается строка AnsiString, в которую копируется содержимое строки PChar, а потом сравниваются две строки AnsiString. Сравниваются, естественно, по значению. Для строк ShortStringсравнение указателей невозможно, две таких строки всегда сравниваются по значению. Правила хранения литералов и сравнения с другими типами следующие: 1. Литералы типа ShortStringразмещаются в сегменте кода только один раз на одну функцию, сколько бы раз они ни повторялись в ее тексте. 2. При сравнении строк ShortStringи AnsiStringпервая сначала конвертируется в тип AnsiString, а потом выполняется сравнение. 3. При сравнении строк ShortStringи PCharстрока PCharконвертируется в ShortString, затем эти строки сравниваются. Последнее правило таит в себе «подводный камень», который иллюстрируется следующим примером (листинг 3.26). Листинг 3.26. Ошибка при сравнении переменных типаShortStringи PChar procedure TForm1.Button8Click(Sender: TObject); var P: PChar; S: ShortString begin P := StrAlloc(300); FillChar(P^, 299, 'A'); P[299] := #0; S[0] := #255; FillChar(S[1], 255, 'A'); if S = P then Label1.Caption := 'Равно' else Label1.Caption := 'Не равно'; StrDispose(Р); end; Здесь формируется строка типа PChar, состоящая из 299 символов "A". Затем формируется строка ShortString, состоящая из 255 символов "А". Очевидно, что эти строки не равны, потому что имеют разную длину. Тем не менее на экране появится надпись Равно. Происходит это вот почему: строка PCharоказывается больше, чем максимально допустимый размер строки ShortString. Поэтому при конвертировании лишние символы просто отбрасываются. Получается строка длиной 255 символов, совпадающая со строкой ShortString, с которой мы ее сравниваем. Отсюда вывод: если строка ShortStringсодержит 255 символов, а строка PChar— более 255 символов, и ее первые 255 символов совпадают с символами строки ShortString, операция сравнения ошибочно даст положительный результат, хотя эти строки не равны. Избежать этой ошибки поможет либо явное сравнение длины перед сравнением строк, либо приведение одной из сравниваемых строк к типу AnsiString(второй аргумент при этом также будет приведен к этому типу). Следующий пример (листинг 3.27) дает правильный результат Не равно. Листинг 3.27. Правильное сравнение переменных типа ShortStringи PChar procedure TForm1.Button9Click(Sender: TObject); var P: PChar; S: ShortString; begin P := StrAlloc(300); FillChar(P^, 299, 'A'); P[299] := #0; S[0] := #255; FillChar(S[1], 255, 'A'); if string(S) = P then Label1.Caption := 'Равно' else Label1.Caption := 'He равно'; StrDispose(P); end; Учтите, что конвертирование в AnsiString— операция дорогостоящая в смысле процессорного времени (в этом примере будут выделены, а потом освобождены два блока памяти), поэтому там, где нужна производительность, целесообразнее вручную сравнить длину, а еще лучше вообще по возможности избегать сравнения строк разных типов, т.к. без конвертирования это в любом случае не обходится. Теперь зададимся глупым, на первый взгляд, вопросом: если мы приведем строку AnsiStringк PChar, будут ли равны указатели? Проверим это (листинг 3.28). Листинг 3.28. Равенство указателей после приведения AnsiStringк PChar procedure TForm1.Button10Click(Sender: TObject); var S: string; P: PChar; begin S := 'Test'; P := PChar(S); if Pointer(S) = P then Label1.Caption := 'Равно' else Label1.Caption := 'Не равно'; end; Вполне ожидаемый результат — Равно. Можно, например, перенести строку из сегмента кода в динамическую память с помощью UniqueString— результат не изменится. Однако выводы делать рано. Рассмотрим следующий пример (листинг 3.29). Листинг 3.29. Сравнение указателя после приведения пустой строки к PChar procedure TForm1.Button11Click(Sender: TObject); var S: string; P: PChar; begin S := ''; P := PChar(S); if Pointer(S) = P then Label1.Caption : = 'Равно' else Label1.Caption := 'He равно'; end; От предыдущего он отличается только тем, что строка Sимеет пустое значение. Тем не менее на экране мы увидим Не равно. Связано это с тем, что приведение строки AnsiStringк типу PCharна самом деле не является приведением типов. Это скрытый вызов функции _LStrToPChar, и сделано так для того, чтобы правильно обрабатывать пустые строки. Значение ''(пустая строка) для строки AnsiStringозначает, что память для нее вообще не выделена, а указатель имеет значение nil. Для типа PCharпустая строка — это ненулевой указатель на символ #0. Нулевой указатель также может рассматриваться как пустая строка, но не всегда — иногда это рассматривается как отсутствие какого бы то ни было значения, даже пустого (аналог NULL в базах данных). Чтобы решить это противоречие, функция _LStrToPCharпроверяет, пустая ли строка хранится в переменной, и, если не пустая, возвращает этот указатель, а если пустая, то возвращает не nil, а указатель на символ #0, который специально для этого размещен в сегменте кода. Таким образом, для пустой строки PChar(S) <> Pointer(S), потому что приведение строки AnsiStringк указателю другого типа — это нормальное приведение типов без дополнительной обработки значения. 3.3.5. Побочное изменениеИз-за того, что две одинаковые строки AnsiStringразделяют одну область памяти, на неожиданные эффекты можно натолкнуться, если модифицировать содержимое строки в обход стандартных механизмов. Следующий код (листинг 3.30, пример SideChange на компакт-диске) иллюстрирует такую ситуацию. Листинг 3.30. Побочное изменение переменной S2при измененииS1 procedure TForm1.Button1Click(Sender: TObject); var S1, S2: string; P: PChar; begin S1 := 'Test'; UniqueString(S1); S2 := S1; P := PChar(S1); P[0] := 'F'; Label1.Caption := S2; end; В этом примере требует комментариев процедура UniqueString. Она обеспечивает то, что счетчик ссылок на строку будет равен единице, т.е. для этой строки делается уникальная копия. Здесь это понадобилось для того, чтобы строка S1хранилась в динамической памяти, а не в сегменте кода, иначе мы получили бы Access violation, как и во втором случае рассмотренного ранее примера Constants (см. листинг 2.17). В результате работы этого примера на экран будет выведено не Test, a Fest, хотя значение S2, казалось бы, не должно меняться, потому что изменения, которые мы делаем, касаются только S1. Но более внимательный анализ подсказывает объяснение: после присваивания S2 := S1счетчик ссылок строки становится равным двум, а сама строка разделяется двумя указателями: S1и S2. Если бы мы попытались изменить непосредственно S2, то сначала была бы создана копия этой строки, а потом сделаны изменения в этой копии, а оригинал, на который указывала бы S2, остался без изменений. Но, использовав PChar, мы обошли механизм копирования, поэтому строка осталась в единственном экземпляре, и изменения затронули не только S1, но и S2. В данном примере все достаточно очевидно, но в более сложных случаях разработчик программы может и не подозревать, что строка, с которой он работает, разделяется несколькими переменными. Справка Delphi советует сначала обеспечить уникальность копии строки с помощью UniqueStringи только потом работать с ней через PChar, если в этом есть необходимость. Рассмотрим еще один пример, практически не отличающийся от предыдущего (листинг 3.31). Листинг 3.31. Отсутствие побочного изменения переменнойS2при изменении S1 procedure TForm1.Button2Click(Sender: TObject); var S1, S2: string; P: PChar; begin S1 := 'Test'; UniqueString(S1); S2 := S1; P := @S1[1]; P[0] := 'F'; Label1.Caption := S2; end; В этом случае на экран будет выведено Test, т.е. побочного изменения переменной не произойдёт, хотя переменная S1по прежнему изменяется в обход стандартных механизмов Delphi. Вся разница между двумя примерами заключается в том, как получается указатель на строку. В первом примере он является результатом приведения типа строки к PChar, а во втором — операции взятия адреса первого символа строки. По идее, это должно приводить к одинаковому результату, однако компилятор, зная, что указатель получается, возможно, для того, чтобы с его помощью менять содержимое строки, вставляет сюда неявный вызов UniqueString. В результате этого для S1выделяется в динамической памяти другая область, чем для S2, и манипуляции с содержимым S1больше не затрагивают S2. Неявный вызов UniqueStringпри обращении к символу строки по индексу выполняется всегда, когда у компилятора есть основания ожидать изменения строки. Это снижает производительность, т.к. многие вызовы UniqueStringоказываются излишними. Например, если выполняется посимвольная модификация строки в цикле, UniqueStringбудет вызываться на каждой итерации цикла, хотя достаточно одного вызова — перед началом цикла. Поэтому в тех случаях, когда производительность критична, посимвольную модификацию строки лучше выполнять низкоуровневыми методами, обращаясь к символам через указатели и обеспечив уникальность строки самостоятельно. Что же касается скорости получения указателя, то тут наиболее быстрым является приведение переменной типа AnsiStringк типу Pointer, т.к. это вообще не приводит к генерации дополнительного кода. Приведение к типу PCharработает медленнее потому, что выполняется неявный вызов функции _LStrToPChar, а получение адреса первого символа снижает производительность из-за неявного вызова UniqueString. Примечание 3.3.6. Нулевой символ в середине строкиХотя символ #0и добавляется в конец каждой строки AnsiString, он уже не является признаком ее конца, т.к. длина строки хранится отдельно. Это позволяет размещать символы #0и в середине строки. Но нужно учитывать, что полноценное преобразование такой строки в PCharневозможно — это иллюстрируется примером Zero на компакт-диске (листинг 3.32). Листинг 3.32. Потеря остатка строки после символа #0 procedure TForm1.Button1Click(Sender: TObject); var S1, S2, S3: string; P: PChar; begin S1 := 'Test'#0'Test'; S2 := S1; UniqueString(S2); P := PChar(S1); S3 := P; Label1.Caption := IntToStr(Length(S2)); Label2.Caption := IntToStr(Length(S3)); end; В первую метку будет выведено число 9 (длина исходной строки), во вторую — 4. Мы видим, что при копировании одной строки AnsiStringв другую символ #0в середине строки — не помеха (вызов UniqueStringдобавлен для того, чтобы обеспечить реальное копирование строки, а не только копирование указателя). А вот как только мы превращаем эту строку PChar, информация о ее истинной длине теряется, и при обратном преобразовании компилятор ориентируется на символ #0, в результате чего строка "обрубается". Потеря куска строки после символа #0происходит всегда, когда есть преобразование ShortStringили AnsiStringв PChar, даже неявное. Например, все API-функции работают с нуль-терминированными строками, а визуальные компоненты — просто обертки над этими функциями, поэтому вывести с их помощью на экран строку, содержащую #0, целиком невозможно. Но главный "подводный камень", связанный с символом #0в середине строки, заключается в том, что целый ряд стандартных функций для работы со строками AnsiStringна самом деле вызывают API-функции (или даже библиотечные функции Delphi, предназначенные для работы с PChar, что приводит к игнорированию "хвоста" после #0. Следующий код (листинг 3.33. пример ZeroFind на компакт-диске) иллюстрирует эту проблему. Листинг 3.33. Некорректная работа функции AnsiPosс символом #0 procedure TForm1.Button1Click(Sender: TObject); begin Label1.Caption := IntToStr(AnsiPos('Z', 'A'#0'Z')); end; Хотя символ "Z" присутствует в строке, в которой производится поиск, на экран будет выведен "0", что означает отсутствие искомой подстроки. Это связано с тем, что функция AnsiPosиспользует функции StrPosи CompareString, предназначенные для работы со строками PChar, поэтому поиск за символом #0, не производится. Если заменить в этом примере функцию AnsiPosна Pos, которая работает с типом AnsiStringдолжным образом, на экран будет выведено правильное значение "3". Описанные проблемы заставляют очень осторожно относиться к возможному появлению символа #0в середине строк AnsiString— это может стать источником неожиданных проблем. 3.3.7. Функция, возвращающая AnsiStringОчень интересный "подводный камень", связанный с типом AnsiStringрассмотрен в статье [4]. Проиллюстрируем его следующим кодом (листинг 3.34, пример StringResult на компакт-диске). Листинг 3.34. Неожиданное значение результата function AddOne: string; begin Result := Result + '1'; end; procedure TForm1.Button1Click(Sender: TObject); var S: string; begin S := 'Test'; S := AddOne; Label1.Caption := S; end; Если человека, не знакомого с этой особенностью компилятора, попросить предсказать, что появится на экране в результате выполнения этого кода, его рассуждения будут звучать, скорее всего, примерно так: "Так как Resultв функции AddOne— это локальная переменная типа string, то, как и все такие переменные, она будет инициализирована пустым значением. Добавление символа '1'к пустой строке даст в результате строку '1', которая и будет выведена на экран. Кстати, на строке S := 'Test'компилятор должен выдать предупреждение, что значение, присвоенное переменной S, нигде не используется". Однако эти рассуждения неверны. На экране появится надпись Test1, т.е. первоначальное значение переменной Sбудет учтено в функции AddOne. Это происходит потому, что с точки зрения двоичного кода переменная Resultэто не локальная переменная, а параметр-переменная, как если бы функции AddOneбыла объявлена так: procedure AddOne(var Result: string); Именно так компилятор обрабатывает функции, тип результата которых AnsiString(и ShortString, кстати, тоже). Какая переменная будет передана в качестве параметра, — это зависит от того, как вызвана функция, точнее, куда идет ее результат. Иногда компилятору приходится неявно имитировать какую-то переменную, а иногда он может воспользоваться реально существующей переменной. В нашем случае он воспользовался переменной S, передав её в качестве параметра. Строковые параметры-переменные, в отличие от локальных переменных, по понятным причинам не инициализируются пустой строкой, поэтому переменная Resultсохраняет значение переменной S, что и приводит к наблюдаемому результату. Из этого следует правило, которое должен помнить разработчик: функция, возвращающая строковое значение, не должна делать никаких предположений о первоначальном значении переменной Result, т.к. оно может оказаться любым. Следует заметить, что аналогичным образом компилятор обходится и с другими сложными типами: если функция возвращает такой тип, то Resultстановится не локальной переменной, а неявным параметром-переменной. Просто с другими типами это не так заметно, потому что от них никто не ожидает автоматической инициализации в прологе функции, и обращаются с переменной Resultтак, будто она содержит случайный мусор. 3.3.8. Строки в записяхПоля в записях могут иметь любой строковый тип без дополнительных ограничений. Однако следует учитывать, что, в отличие от полей простых типов, значения полей типа PCharи AnsiStringлежат вне пределов структуры, причем в случае AnsiStringэто не так бросается в глаза, т.к вручную выделять и освобождать память не приходится. Это может привести к неприятному сюрпризу, если работать со структурой как с цельным блоком данных. Чаще всего проблема появляется при записи структуры в поток, файл и т.п. В этом случае записывается только значение указателя, которое не имеет никакого смысла для того, кто потом эти данные читает, такой указатель указывает либо в никуда, либо на данные, никакого отношения к строке не имеющие. Для иллюстрации этой проблемы, а также методов её решения нам понадобятся два проекта: RecordRead и RecordWrite (на компакт-диске они оба находятся в папке RecordReadWrite). Обойтись одним проектом здесь нельзя — указатель, переданный в пределах проекта, остается корректным, поэтому проблема маскируется. В проекте RecordWrite три кнопки, соответствующие трем методам сохранения записи в поток TFileStream(в файлы Method1.stm, Method2.stm и Method3.stm соответственно). В три целочисленных поля заносятся текущие час, минута, секунда и сотая доля секунды, строка — произвольная, введенная пользователем в поле ввода Edit1. Файлы пишутся в текущую папку, из-за этого программы нельзя запускать непосредственно с компакт-диска. В проекте RecordRead три кнопки соответствуют трем методам чтения (каждый из своего файла). Сначала рассмотрим первый метод — как делать ни в коем случае нельзя. В проекте RecordWrite имеем следующий код (листинг 3.35). Листинг 3.35. Неправильный метод записи структуры со строкой в файлtype TMethod1Record = packed record Hour: Word; Minute: Word; Second: Word; MSec: Word; Msg: string; end; procedure TForm1.Button1Click(Sender: TObject); var Rec: TMethod1Record; Stream: TFileStream; begin DecodeTime(Now, Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec); Rec.Msg := Edit1.Text; Stream := TFileStream.Create('Method1.stm', fmCreate); Stream.WriteBuffer(Rec, SizeOf(Rec)); Stream.Free; end; В проекте RecordRead соответствующий код (листинг 3.36). Листинг 3.36. Неправильный метод чтения структуры со строкой из файлаprocedure TForm1.Button1Click(Sender: TObject); var Rec: TMethod1Record; Stream: TFileStream; begin Stream := TFileStream.Create('Method1.stm', fmOpenRead); Stream.ReadBuffer(Rec, SizeOf(Rec)); Stream.Free; Label1.Caption := TimeToStr(EncodeTime(Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec)); Label2.Caption := Rec.Msg; { * } end; Примечание Запись в файл происходит нормально, но при чтении в строке, отмеченной звездочкой, скорее всего, возникает исключение Access violation (в некоторых случаях исключения может не быть, но вместо сообщения будет выведен мусор). Причину этого мы уже обсудили ранее — указатель Msg, действительный в контексте процесса RecordWrite, не имеет смысла в процессе RecordRead, а сама строка передана не была. Без ошибок этим методом можно передать только пустую строку, потому что ей соответствует указатель nil, имеющий одинаковый смысл во всех процессах. Однако метод передачи строк, умеющий передавать только пустые строки, имеет весьма сомнительную ценность с практической точки зрения. Самый простой способ исправить ситуацию— изменить тип поля Msgна ShortString. Больше ничего в приведенном коде менять не придется. Однако использование ShortStringимеет два недостатка. Во-первых, длина строки в этом случае ограничена 255 символами. Во-вторых, если длина строки меньше максимально возможной, часть памяти, выделенной для структуры, останется незаполненной. Если средняя длина строки существенно меньше максимальной, то таких неиспользуемых кусков в потоке будет много, т.е. файл окажется неоправданно раздутым. Это всегда плохо, а в некоторых случаях — вообще недопустимо, поэтому ShortStringможно посоветовать только в тех случаях, когда строки имеют примерно одинаковую длину (напомним, что ShortStringпозволяет ограничить длину строки меньшим, чем 255, числом символов — в этом случае поле будет занимать меньше места). С одним из этих недостатков можно бороться: если заменить в записи ShortStringстатическим массивом типа Char, то можно передавать строки большей, чем 255 символов, длины. Второй метод демонстрирует этот способ. В проекте RecordWrite этому соответствует код (листинг 3.37). Листинг 3.37. Запись в файл структуры с массивом символовconst MsgLen = 15; type TMethod2Record = packed record Hour: Word; Minute: Word; Second: Word; MSec: Word; Msg: array[0..MsgLen - 1] of Char; end; procedure TForm1.Button2Click(Sender: TObject); var Rес: TMethod2Record; Stream: TFileStream; begin DecodeTime(Now, Rec.Hour, Rec.Minute, Rес.Second, Rec.MSec); StrPLCopy(Rec.Msg, Edit1.Text, MsgLen - 1); Stream := TFileStream.Create('Method2.stm', fmCreate); Stream.WriteBuffer(Rec, SizeOf(Rec)); Stream.Free; end; В проекте RecordRead это следующий код (листинг 3.38). Листинг 3.38. Чтение из файла структуры с массивом символовprocedure TForm1.Button2Click(Sender: TObject); var Rес: TMethod2Record; Stream: TFileStream; begin Stream := TFileStream.Create('Method2.stm', fmOpenRead); Stream.ReadBuffer(Rec, SizeOf(Rec)); Stream.Free; Label1.Caption := TimeToStr(EncodeTime(Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec)); Label2.Caption := Rec.Msg; end; Константа MsgLenзадаёт максимальную (вместе с завершающим нулём) длину строки. В приведенном примере она взята достаточно маленькой, чтобы наглядно продемонстрировать, что данный метод имеет ограничения на длину строки. Переделки по сравнению с кодом предыдущего метода минимальны: при записи для копирования значения Edit1.Textвместо присваивания нужно вызывать функцию StrPLCopy. В коде RecordReadизменений (за исключением описания самой структуры) вообще нет — это достигается за счёт того, что массив Charсчитается компилятором совместимым с PChar, а выражения типа PCharмогут быть присвоены переменным типа AnsiString— конвертирование выполнится автоматически. Однако проблему неэффективного использования файлового пространства мы таким образом не решили. Более того, мы до конца не решили и проблему максимальной длины: хотя ограничение на длину строки теперь может быть произвольным, всё равно оно должно быть известно на этапе компиляции. Чтобы полностью избавиться от этих проблем, необходимо вынести строку за пределы записи и сохранить её отдельно, вместе с длиной, чтобы при чтении сначала читалась длина строки, затем выделялась для неё память, и в эту память читалась строка. Именно так работает третий метод. В проекте Record Write это будет следующий код (листинг 3.39) Листинг 3.39. Запись в файл строки отдельно от структурыtype TMethod3Record = packed record Hour: Word; Minute: Word; Second: Word; MSec: Word; end; procedure TForm1.Butrton3Click(Sender: TObject); var Rec: TMethod3Record; Stream: TFileStream; Msg: string; MsgLen: Integer; begin DecodeTime(Now, Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec); Msg := Edit1.Text; MsgLen := Length(Msg); Stream := TFileStream.Create('Method3.stm', fmCreate); Stream.WriteBuffer(Rec, SizeOf(Rec)); Stream.WriteBuffer(MsgLen, SizeOf(MsgLen); if MsgLen > 0 then Stream.WriteBuffer(Pointer(Msg)^, MsgLen); Stream.Free; end; В проекте RecordRead это следующий код (листинг 3.40). Листинг 3.40. Чтение из файла строки отдельно от структурыprocedure TForm1.Button3Click(Sender: TObject); var Rec: TMethod3Record; Stream: TFileStream; Msg: string; MsgLen: Integer; begin Stream := TFileStream.Create('Method3.stm', fmOpenRead); Stream.ReadBuffer(Rec, SizeOf(Rec)); Stream.ReadBuffer(MsgLen, SizeOf(Integer)); SetLength(Msg, MsgLen); if MsgLen > 0 then Stream.ReadBuffer(Pointer(Msg)^, MsgLen); Stream.Free; Label1.Caption := TimeToStr(EncodeTime(Rec.Hour, Rec.Minute, Rec.Second, Rec.MSec)); Label2.Caption := Msg; end; Наконец-то мы получили код, который безошибочно передает строку, не имея при этом ограничений длины (кроме ограничения на длину AnsiString) и не расходуя понапрасну память. Правда, сам код получился сложнее. Во-первых, из записи исключено поле типа string, и теперь ее можно без проблем читать и писать в поток. Во-вторых, в поток после нее записывается длина строки. В-третьих, записывается сама строка. Параметры вызова методов ReadBufferи WriteBufferдля чтения/записи строки требуют дополнительного комментария. Метод WriteBufferпишет в поток ту область памяти, которую занимает указанный в качестве первого параметра объект. Если бы мы указали саму переменную Msg, то записалась бы та часть памяти, которую занимает эта переменная, т.е. сам указатель. А нам не нужен указатель, нам необходима та область памяти, на которую он указывает, поэтому указатель следует разыменовать с помощью оператора ^. Но просто взять и применить этот оператор к переменной Msgнельзя — с точки зрения синтаксиса она не является указателем. Поэтому приходится сначала приводить ее к указателю (здесь подошел бы любой указатель, не обязательно нетипизированный). То же самое относится и к ReadBuffer: чтобы прочитанные данные укладывались не туда, где хранится указатель на строку, а туда, где хранится сама строка, приходится прибегнуть к такой же конструкции. И обратите внимание, что прежде чем читать строку, нужно зарезервировать для нее память с помощью SetLength. Вместо приведения строки к указателю с последующим его разыменованием можно было бы использовать другие конструкции: Stream.ReadBuffer(Msg[1], MsgLen); и Stream.WriteBuffer(Msg[1], MsgLen); Это дает требуемый результат и даже более наглядно: действительно, при чтении и записи мы работаем с той областью памяти, которая начинается с первого символа строки, т.е. с той, где хранится сама строка. Но такой способ менее производителен из-за неявного вызова UniqueString. В нашем случае мы и так защищены от побочных изменений других строк (при записи строка не меняется, при чтении она и так уникальна — это обеспечивает SetLength), поэтому вполне можем обойтись без этой в данном случае излишней опеки со стороны компилятора. Примечание Недостатком этого метода является то, что мы вынуждены переделывать под него запись. В нашем примере это не составило проблемы, но в реальных проектах запись обычно предназначена не только для чтения и сохранения в поток, и если взять и выкинуть из нее строки, то все прочие участки кода станут более громоздкими. Поэтому в реальности приходится писать отдельные процедуры, которые сохраняют запись не как единое целое, а по отдельным полям. Ранее мы говорили о том, что копирование записей, содержащих поля типа AnsiString, в рамках одного процесса маскирует проблему, т.к. указатель остается допустимым и даже (какое-то время) правильным. Но сейчас с помощью приведенного в листинге 3.41 кода (пример RecordCopy на компакт-диске) мы увидим, что проблема не исчезает, а просто становится менее заметной. Листинг 3.41. Побочное изменение переменной после низкоуровневого копирования type TSomeRecord = record SomeField: Integer; Str: string; end; procedure TForm1.Button1Click(Sender: TObject); var Rec: TSomeRecord; S: string; procedure CopyRecord; var LocalRec: TSomeRecord; begin LocalRec.SomeField := 10; LocalRec.Str := 'Hello!!!'; UniqueString(LocalRec.Str); Move(LocalRec, Rec, SizeOf(TSomeRecord)); end; begin CopyRecord; S := 'Good bye'; UniqueString(S); Label1.Caption := Rec.Str; Pointer(Rec.Str) := nil; end; На экране вместо ожидаемого Hello!!! появится Good bye. Это происходит вот почему: процедура Moveосуществляет простое побайтное копирование одной области памяти в другую, механизм изменения счетчика ссылок при этом не срабатывает. В результате менеджер памяти не будет знать, что после завершения локальной процедуры CopyRecordостаются ссылки на строку "Hello!!!". Память, выделенная этой строке, освобождается. Но Rec.Strпродолжает ссылаться на эту уже освобожденную память. Для строки Sвыделяется свободная память — та самая, где раньше была строка LocalRec.Str. А поскольку Rec.Strпродолжает ссылаться на эту область памяти, поэтому обращение к ней дает строку "Good bye", которая теперь там размещена. Обратите внимание на последнюю строку — приведение Rec.Strк типу Pointerи обнулению. Это сделано для того, чтобы менеджер памяти не пытался финализировать строку Rec.Strпосле завершения процедуры, иначе он попытается освободить память, которая уже освобождена, и возникнет ошибка. Чтобы показать, насколько коварна эта ошибка, рассмотрим следующий код (листинг 3.42, из того же примера RecordCopy на компакт-диске). Листинг 3.42. Сокрытие ошибки при низкоуровневом копировании записи со строкойprocedure TForm1.Button2Click(Sender: TObject); var Rec: TSomeRecord; S: string; procedure CopyRecord; var LocalRec: TSomeRecord; begin LocalRec.SomeField := 10; LocalRec.Str := 'Привет!'; Move(LocalRec, Rec, SizeOf(TSomeRecord)); end; begin CopyRecord; S := 'Пока!'; Label1.Caption := Rec.Str; end; Or предыдущего случая этот пример отличается только тем, что в нем нет вызовов UniqueString, и строки указывают на литералы в сегменте кода, которые никогда не удаляются. На экране получаем вполне ожидаемое Привет!. Обнулять указатель здесь уже нет смысла, потому что освобождать литерал менеджер памяти все равно не будет. Так ошибка оказалась скрытой. Продолжим наши эксперименты. Запустим пример RecordCopy и понажимаем попеременно кнопки Button1и Button2. Мы видим, что результат не зависит от порядка, в котором мы нажимаем кнопки. Модифицируем код в локальной процедуре обработчика Button1Click: уберем из строки "Hello!!!" восклицательные знаки, сократив ее до "Hello". Теперь можно наблюдать интересный эффект: если после запуска нажать сначала Button1, то никаких изменений мы не заметим. А вот если кнопка Button2будет нажата раньше, чем Button1, то при последующих нажатиях Button1никаких видимых эффектов не будет. Это связано с тем, что теперь строка "Hello" не равна по длине строке "Good bye", поэтому разместится ли "Good bye" в том же месте памяти, где раньше была "Hello", или в каком-то другом, зависит от истории выделения и освобождения памяти. Если мы начинаем "с чистого листа", память после строки "Hello" останется свободной, поэтому туда можно поставить более длинную строку. А вот если раньше память уже выделялась и освобождалась (внутри методов TLabel), то тот кусочек свободной памяти, который достаточен для "Hello", слишком мал для "Good bye", и эта строка размещается в другом месте. А там, куда указывает Rec.Str, остается мусор, работать с которым нормально невозможно, поэтому при попытке присвоить его свойству Label1.Captionпоследнее не меняется (эффект наблюдается только до Delphi 7 включительно; в более новых версиях Delphi используется новый менеджер памяти FastMem, который немного по-другому размещает строки в памяти, поэтому с ним зависимости от порядка нажатия кнопок не будет). Примечание Даже на таком простом примере видно, насколько коварна эта ошибка и как незначительные изменения в коде могут кардинально изменить ее проявления. Между тем приведенный здесь код — плод долгого "приручения" этой ошибки, чтобы она всегда проявлялась предсказуемым образом. Но даже сейчас мы не можем дать полной гарантии, что у кого-то из читателей из-за какой-то неучтенной мелочи не возникнет ситуация, когда эта ошибка проявляется как-то по-другому (как мы уже видели, даже в разных версиях Delphi эта ошибка проявляет себя немного по-разному). В реальных проектах все гораздо сложнее, и поведение программы из-за этой ошибки может стать таким неожиданным, а проявление этой ошибки — настолько далеким от того места, где она сделана, что впору будет "прыгать вокруг компьютера с бубном", изгоняя бесов. Чтобы не оказаться в таком положении, нужно очень аккуратно работать со строками (а также с другими автоматически финализируемыми типами: динамическими массивами, интерфейсами, вариантами), чтобы тот код, который неявно генерирует компилятор, не оказался в тупике. Чаще всего проблемы возникают при побайтном копировании переменной типа AnsiString(не обязательно в составе записи) или при работе с ней как с указателем другого типа. Это не значит, что приводить AnsiStringк другим указателям категорически нельзя — ранее мы уже делали это, и вполне успешно. Но, применяя любой низкоуровневый инструмент к таким строкам, разработчик должен четко представлять, как это отразится на внутренних механизмах работы с ними. Иначе — вот такая непонятная ошибка. Еще одна ситуация, когда записи со строками могут преподнести сюрприз — выделение динамический памяти для них. Динамическую память можно выделить двумя способами: с помощью процедуры Newили GetMem(освобождать ее надо, соответственно, с помощью Disposeили FreeMem). Для записей, не содержащих строки, эти способы практически эквивалентны, за исключением того, что при использовании Newобъем выделяемой памяти определяет компилятор, поэтому Newсчитается более безопасным вариантом. Если же запись содержит строку, то эта строка должна быть инициализирована, иначе попытка работы с ней приведет к ошибке. Процедура GetMemничего не делает с содержимым выделяемой ею памяти, и строка остается неинициализированной, в то время как Newвыполняет инициализацию. Это не значит, что GetMemнепригодна для выделения памяти для такой записи, просто после вызова GetMemнужно не забыть вызвать специальную процедуру Initialize, которая правильно инициализирует строки в записи. Соответственно, прежде чем удалить такую запись с помощью FreeMem, необходимо вызвать процедуру Finalizeдля финализации строк. Это создает дополнительные проблемы, не давая никаких преимуществ, поэтому целесообразнее все-таки использовать Newи Dispose. Преимущество GetMemперед Newзаключается в том, что за один вызов GetMemможно выделить память сразу для нескольких записей (с последующей их ручной инициализацией, конечно же), в то время как Newвыделяет память только для одного экземпляра записи. Но с появлением в языке динамических массивов это преимущество тоже перестало быть особо полезным. Проще объявить динамический массив из записей и создать требуемое число элементов в нем — компилятор сам позаботится об инициализации таких переменных. Поэтому мы рекомендуем отказаться от GetMemпри выделении памяти под записи со строками, а если уж вы столкнулись с ситуацией, когда без этого совсем никак, не забывайте вызывать Initializeи Finalize. Примечание Память для записей можно выделять и в обход менеджера памяти Delphi напрямую вызывая системные функции типа HeapAlloc, VirtualAllocили CoTaskMemAlloc. Разумеется, компилятор в этом случае не сможет инициализировать и финализировать выделяемую память, поэтому, как и в случае с GetMem, для строк с записями необходимо пользоваться процедурами Initializeи Finalize. 3.3.9. Использование ShareMemПример, который мы сейчас рассмотрим, — это даже не "подводный камень", это то, что в форумах обычно называется "грабли". Все новые и новые программисты с завидным упорством наступают на эти грабли и получают по лбу, хотя, казалось бы, вокруг стоят таблички, предупреждающие об опасности, только не ленись читать. Итак, создаем новую динамически компонуемую библиотеку (DLL). Delphi предлагает нам следующую заготовку (листинг 3.43). Листинг 3.43. Базовыйlibrary Project1; { Important note about DLL memory management: ShareMem must be the first unit in your library's USES clause AND your project's (select Project-View Source) USES clause if your DLL exports any procedures or functions that pass strings as parameters or function results. This applies to all strings passed to and from your DLL--even those that are nested in records and classes. ShareMem is the interface unit to the BORLNDMM.DLL shared memory manager, which must be deployed along with your DLL. To avoid using BORLNDMM.DLL, pass string information using PChar or ShortString parameters. } uses SysUtils, Classes; {$R *.RES} begin end. Самое важное здесь — комментарий. Его следует внимательно прочитать и осознать, а главное — выполнить эти советы, иначе при передаче строк AnsiStringмежду DLL и программой вы будете получать ошибку Access violation в самых неожиданных местах. Почему-то многие им пренебрегают, а потом бегут с вопросами в разные форумы, хотя минимум внимательности и отсутствия снобизма по отношению "к этим, из Borland'а, которые навставляли тут никому не нужных комментариев" могли бы уберечь от ошибки. Для начала выясним источник ошибки. Менеджер памяти Delphi работает следующим образом: он берет у системы большие блоки памяти, а потом по мере необходимости выделяет их по частям. Это позволяет избежать частых выделений памяти системными средствами и тем самым повышает производительность. Следствием этого становится то. что менеджер памяти должен иметь информацию о том, какими блоками он распределил полученную от системы память между различными потребителями. Менеджер памяти реализуется модулем System. Так как DLL компонуется отдельно от использующего ее exe-файла, у нее будет своя копия кода System, и, следовательно, свой менеджер памяти. И если объект, память для которого была выделена в коде основного модуля программы, попытаться освободить в коде DLL, то получится, что освобождать память будет совсем не тот менеджер, который ее выделил. А сделать он этого не сможет, т.к. не обладает информацией о выделенном блоке. Результат — ошибка (скорее всего, Access violation при выходе из процедуры). А при работе со строками AnsiStringпамять постоянно выделяется и освобождается, поэтому, попытавшись работать с одной и той же строкой и в главном модуле, и в DLL, мы получим ошибку. Теперь, когда мы поняли, почему возникает проблема, разберемся, как ShareMemее решает. Delphi предоставляет возможность заменить стандартный менеджер памяти своим: для этого нужно написать низкоуровневые функции выделения, освобождения и перераспределения памяти и сообщить их адреса через процедуру SetMemoryManager. После этого через них будут работать все высокоуровневые функции для манипуляций с памятью ( New, GetMemи т.п.). Именно это и делает ShareMemв секции инициализации этого модуля содержится код, заменяющий функции работы с памятью своими, которые находятся во внешней библиотеке BORLNDMM.DLL. Получается, что и библиотека, и главный модуль работают с одним менеджером памяти, что решает описанные проблемы. Если менеджер памяти попытаться поменять не в самом начале программы, то ему придется освобождать память, которую успел выделить предыдущий менеджер памяти, что приведет к той же самой проблеме. Поэтому заменить менеджер памяти нужно до того, как будет выполнена первая операция по её выделению. Отсюда возникает требование вставлять ShareMemпервым модулем в dpr-файлах главного модуля и DLL — чтобы его секция инициализации была первым выполняемым программой кодом. В Интернете часто можно встретить утверждения, что в новых версиях Delphi (BDS2006 и выше) ShareMemне нужен, потому что стандартный менеджер памяти там заменен на FastMM, который прекрасно обходится без ShareMem. Это неверно. Оригинальный FastMMдействительно может функционировать без ShareMemпри выполнении определённых условий. Модуль, использующий FastMM("модуль" здесь значит модуль в понимании системы, т.е. module, а не unit), может предоставить свой менеджер памяти в общее пользование, а все остальные модули, подключившие FastMMбудут пользоваться этим менеджером вместо своего. Получится, что все модули в процессе будут работать с одним менеджером памяти, и проблем не будет. В общее пользование свой менеджер памяти предоставляет тот модуль, который инициализируется самым первым (т.к. основной модуль программы инициализируется только после того, как будут проинициализированы все статически связанные с ним DLL, в общее пользование свой менеджер памяти предоставляет одна из DLL). Тот вариант FastMM, который входит в состав новых версий Delphi, тоже может быть предоставлен в общее пользование, но по умолчанию этого не происходит, так что с передачей строк в DLL возникнут те же проблемы, что и в старых версиях Delphi. Но решить эти проблемы теперь можно двумя способами. Первый — это использовать ShareMemи распространять с программой библиотеку BORLNDMM.dll, точно так же, как и в более ранних версиях Delphi. Второй способ — подключить к dpr-файлам библиотек и главного модуля модуль SimpleShareMem. Этот модуль в своей секции инициализации проверяет, есть ли уже переданный в общее пользование менеджер памяти, и если есть, переключает свою программу или DLL на него, а если ещё нет, делает текущий менеджер памяти общим. Использование модулей SimpleShareMemи ShareMemидентично: его так же нужно указывать первым в списке uses главного файла проекта. Но никаких дополнительных библиотек распространять с программой не придется. Таким образом, новые версии Delphi действительно позволяют обойтись без библиотеки BORLNDMM.DLL, но это все-таки получается не автоматически, а после некоторых усилий. Кстати, к данному в комментарии совету заменить AnsiStringна PChar, чтобы избавиться от необходимости использования ShareMem, следует относиться осторожно: если мы попытаемся, например, вызвать StrNewв основной программе, а StrDispose— в DLL, то получим ту же проблему. Вопрос не в типах данных, а в том, как манипулировать памятью. Поэтому обычный способ работы с PCharследующий: программа выделяет буфер своим менеджером памяти и передает указатель на этот буфер, а также его длину в качестве параметров функции из DLL. Эта функция заносит в буфер требуемую строку, не перераспределяя память. Затем программа освобождает эту строку своим же менеджером памяти. В листинге 3.44 приведен пример кода такой функции в DLL. Листинг 3.44. Код функции в DLL function GetString(Buf: PChar; BufLen: Integer): Integer; var S: string; begin // Формируем строку для возврата программе ... // Копируем строку в буфер if BufLen > 0 then StrLCopy(Buf, PChar(S), BufLen - 1); // возвращаем требуемый размер буфера Result := Length(S) + 1; end; Здесь параметр Bufсодержит указатель на буфер, выделенный вызывающей программой, BufLen— размер этого буфера в байтах. Для примера здесь взят случай, когда строка, которую нужно возвратить, формируется в переменной типа string, т.к. в большинстве случаев это наиболее удобный способ. После того как строка сформирована, ее содержимое копируется в буфер с учетом его длины. Результат, который возвращает функция, — это необходимый размер буфера. Программа по этому результату может сделать вывод, поместилась ли вся строка в выделенный ей буфер, и если не поместилась, принять меры, например, вызвать функцию еще раз. выделив под буфер больше памяти. Если не существует ограничения на длину возвращаемой строки, программа "не знает", буфер какого размера потребуется. Наиболее простое решение этой проблемы следующее: программа сначала вызывает функцию GetString, передавая nilв качестве указателя на буфер и 0 в качестве размера буфера. Затем по результату функции определяется требуемый размер буфера, выделяется память и функция вызывается еще раз, уже с буфером нужного размера. Такой способ обеспечивает правильную передачу строки любой длины, но требует двукратного вызова функции, что снижает производительность, особенно в том случае, если на формирование строки тратится много времени. Повысить среднюю производительность можно, применяя комбинированный метод получения буфера. Программа создает массив в стеке такого размера, чтобы в большинстве случаев возвращаемая строка вмещалась в нем. Этот размер определяется в каждом конкретном случае, исходя из особенностей функции и условий ее вызова. А на тот случай, если она все-таки там не поместилась, предусмотрен запасной вариант с выделением буфера в динамической памяти. Этот подход иллюстрирует листинг 3.45. Листинг 3.45. Быстрый (в среднем) способ получения строки через буферconst StatBufSize = ...; // Размер, подходящий для данного случая var StatBuf: array[0..StatBufSize - 1] of Char; Buf: PChar; RealLen: Integer; begin // Пытаемся разместить строку в буфере StatBuf RealLen := GetString(StatBuf, StatBufSize); if RealLen > StatBufSize then begin // Если StatBuf оказался слишком мал, динамически выделяем буфер // нужного размера и вызываем функции еще раз Buf := StrAlloc(RealLen); GetString(Buf, RealLen); end else // Размера статического буфера хватило. Пусть Buf указывает // на StatBuf, чтобы нижеследующий код мог в любом случае // обращаться к буферу через переменную Buf Buf := StatBuf; // Что-то делаем с содержимым буфера ... // Если выделяли память, ее следует очистить if Buf <> StatBuf then StrDispose(Buf); end; Следует также упомянуть о еще одной альтернативе передачи строк в DLL — типе WideString, который хранит строку в кодировке Unicode и является, по сути, оберткой над системным типом BSTR. Работать с WideStringтак же просто, как и с AnsiString, перекодирование из ANSI в Unicode и обратно выполняется автоматически при присваивании значения одного типа переменной другого. В целях совместимости с СОМ и OLE при работе с памятью дли строк WideStringиспользуется специальный системный менеджер памяти (через API-функции SysAllocString, SysFreeStringи т.п.), поэтому передавать эти строки из DLL в главный модуль и обратно можно совершенно безопасно даже без ShareMem. Правда, при этом не стоит забывать о расходовании процессорного времени на перекодировку, если основная работа идет не с Unicode, а с ANSI. Отметим одну ошибку, которую делают новички, прочитавшие комментарий про ShareMem, но не умеющие работать с PChar. Они пишут, например, такой код для функции, находящейся в DLL и возвращающей строку (листинг 3.46). Листинг 3.46. Неправильный способ возврата строки из DLL function SomeFunction(...): PChar; var S: string; begin // Здесь присваивается значение S Result := PChar(S); end; Такой код компилируется и даже, за редким исключением, дает ожидаемый результат. Но тем не менее, в этом коде грубая ошибка. Указатель, возвращаемый функцией, указывает на область памяти, которая считается свободной, поскольку после выхода переменной Sза пределы области видимости память, которую занимала эта строка, освободилась. Менеджер памяти может в любой момент вернуть эту память системе (тогда обращение к ней вызовет Access violation) или задействовать для других целей (тогда новая информация уничтожит содержащуюся там строку). Проблема маскируется тем, что обычно результат используется немедленно, до того как менеджер памяти что-то сделает с этим блоком. Тем не менее полагаться на это и писать такой код не следует. 3.4. Прочие "подводные камни"В этом разделе собрана небольшая коллекция не связанных между собой "подводных камней", с которыми пришлось столкнуться автору книги. 3.4.1. Порядок вычисления операндовЭта проблема связана с тем, что у человека есть определенные интуитивные представления о порядке выполнения действий программой, однако компилятор не всегда им соответствует. Рассмотрим следующий код (листинг 3.47, пример OpOrder на компакт-диске). Листинг 3.47. "Неправильный" порядок вычисления операндовvar X: Integer; function GetValueAndModifyX: Integer; begin X := 1; Result := 2; end; procedure TForm1.Button1Click(Sender: TObject); var A1, A2: Integer; begin X := 2; A1 := X + GetValueAndModifyX; X := 2; А2 := GetValueAndModifyX + X; Label1.Caption := IntToStr(A1); Label2.Caption := IntToStr(A2); end; Суть этого примера заключается в том, что функция GetValueAndModifyXимеет побочный эффект — изменяет значение глобальной переменной X. И эту же переменную мы используем при вычислении выражения, в которое входит также вызов GetValueAndModifyX. При вычислении A1в выражении сначала упоминается X, а потом GetValueAndModifyX, при вычислении А2— наоборот. Логично было бы предположить, что A1получит значение 4, А2— 3, т.к. вычисление первого операнда должно выполняться раньше второго. В действительности же обе переменные получат значение 3, поскольку компилятор сам выбирает порядок вычисления операндов независимо от того, в каком порядке они упоминаются в выражении. То же самое касается любых коммутативных операций: умножения, арифметических and, orи xor. Посмотрим, что будет для некоммутативных операций, например, для деления (листинг 3.48). Листинг 3.48. "Неправильный" порядок вычисления операндов при делении procedure TForm1.Button2Click(Sender: TObject); var A1, A2: Extended; begin X := 2; A1 := X / GetValueAndModifyX; X := 2; A2 := GetValueAndModifyX / X; Label1.Caption := FloatToStr(A1); Label2.Caption := FloatToStr(A2); end; В результате выполнения этого кода A1получает значение 0.5, A2— 2, т.е. и здесь сначала вычисляется функция, а потом берется значение переменной X. Если бы функция GetValueAndModifyXне имела побочных эффектов (т.е. только возвращала бы результат и больше ничего не меняла), порядок вычисления аргументов был бы нам безразличен. Вообще, функции, имеющие побочные эффекты, считаются потенциальным источником ошибок, поэтому их написание нежелательно. Но в некоторых случаях (например, в функции Random) обойтись без побочных эффектом невозможно. Примечание Ради интереса посмотрим, что будет, если вторым аргументом тоже будет функция, зависящая от X, (листинг 3.49). Листинг 3.49. Сложение двух операндов с побочными эффектами function GetX: Integer; begin Result := X; end; procedure TForm1.Button3Click(Sender: TObject); var A1, A2: Integer; begin X:= 2; A1 := GetX + GetValueAndModifyX; X := 2; A2 := GetValueAndModifyX + GetX; Label1.Caption := IntToStr(A1); Label2.Caption := IntToStr(A2); end; Здесь A1получит значение 4, A2— 3, т.e. интуитивно ожидаемые. Тем не менее полагаться на интуицию все же не стоит: в более сложных случаях она может подвести. Дело в том, что стандарт языка Паскаль разрешает разработчикам конкретной реализации языка самим выбирать порядок вычисления операндов [5]. Поэтому, даже если вам удалось добиться желаемого порядка вычисления, в следующих версиях Delphi (или при переносе на другую платформу) программа может начать работать неправильно. Таким образом, разработчик не имеет права делать какие-то предположения о том, в каком порядке будут вычисляться операнды, а когда изменение этого порядка может повлиять на результат, код должен быть написан таким образом, чтобы исключить эту возможность. В частности, пример со сложением должен быть переписан так (листинг 3.50). Листинг 3.50. Явное управление порядком вычисления операндов procedure TForm1.Button1Click(Sender: TObject); var A1, A2: Integer; begin X := 2; A1 := X; Inc(A1, GetValueAndModifyX); X := 2; A2 := GetValueAndModifyX; Inc(A2, X); Label1.Caption := IntToStr(A1); Label2.Caption := IntToStr(A2); end; Такой код, несмотря на побочные эффекты функции GetValueAndModifyX, даст ожидаемые значения при любом порядке вычисления операндов, т.к. здесь вычисление операндов разнесено по разным операторам, а порядок выполнения операторов четко определен. Примечание 3.4.2. Зацикливание обработчика TUpDown.OnClick при открытии диалогового окна в обработчикеДля демонстрации этого "подводного камня" нам потребуется проект, на форме которого находится компонент TUpDownсо следующим обработчиком события OnClick(листинг 3.51, пример UpDownDlg на компакт-диске). Листинг 3.51. Обработчик события OnClickкомпонента UpDown1 procedure TForm1.UpDown1Click(Sender: TObject; Button: TUDBtnType); begin Application.MessageBox('Text', 'Caption', MB_OK); end; Теперь, если запустить программу и нажать на верхнюю кнопку UpDown1, откроется окно с сообщением (при нажатии на нижнюю кнопку окно не будет открываться потому, что по умолчанию у компонент TUpDownсвойства Positionи Minравны нулю, поэтому нажатие на нижнюю кнопку не приводит к изменению значения Position, и событие OnClickне возникает; если изменить значение свойства Minили Position, то тот же эффект будет наблюдаться и при нажатии на нижнюю кнопку). Если закрыть это окно, то щелчок мышью в любом месте формы снова приведет к срабатыванию события OnClickи открытию окна, и так до бесконечности: любой щелчок по форме в любом ее месте будет снова и снова приводить к появлению сообщения. Эффект наблюдается и в том случае, когда вместо стандартного сообщения в обработчике показывается любая другая модальная форма. Кроме того, тот же эффект будет, и если использовать события OnChangingили OnChangingExвместо OnClick, но мы далее для определенности будем говорить только об OnClick. Если этот код пройти по шагам в отладчике, то никакого зацикливания не возникает: OnClickвызывается один раз, любое последующее нажатие кнопки мыши на форме не приводит ни к каким необычным результатам. Причина этой проблемы в том, как VCL обрабатывает сообщения, которые система помещает в очередь. При нажатии на кнопку компонента TUpDownв очередь сообщений помещаются два сообщения: WM_LBUTTONDOWNи WM_NOTIFY. Компонент TUpDownпо умолчанию имеет стиль csCaptureMouse— это означает, что при обработке WM_LBUTTONDOWNVCL захватывает мышь в монопольное пользование для данного компонента. Примечание Затем начинает обрабатываться событие WM_NOTIFY, которое уведомляет программу о том, что пользователь нажал на кнопку компонента TUpDown. Именно при обработке этого сообщения VCL вызывает событие TUpDown.OnClick, в котором открывается модальное окно. Всё это происходит очень быстро, поэтому кнопку мыши пользователь отпускает тогда, когда модальное окно уже оказалось на экране. В результате сообщение WM_LBUTTONUPлибо попадает в очередь открывшегося диалогового окна, если мышь находилась над ним, либо вообще никуда не попадает, если мышь была вне модального окна. На время существования модального окна система "забывает" о том, что мышь захвачена для монопольного использования, но "вспоминает" об этом, как только модальное окно закрывается. Монопольное использование мыши компонентом TUpDownдолжно отменяться при обработке сообщения WM_LBUTTONUP, но оно, как было сказано ранее, в очередь не попадает, поэтому после закрытия окна мышь остается захваченной данным компонентом. Поэтому любое нажатие кнопки мыши воспринимается системой как относящееся к UpDown1, и снова приводит к помещению в очередь сообщений WM_LBUTTONDOWNи WM_NOTIFY, которые обрабатываются описанным образом. Так получается порочный круг, из которого при нормальной работе программы нет выхода. Этот круг может быть разорван, например, отладчиком, который отменяет монопольное использование мыши компонентами программы, чтобы иметь возможность работать. В этой проблеме виновата VCL, которая зачем-то назначает компоненту TUpDownстиль csCaptureMouse. Данный компонент реализуется не средствами VCL, — это стандартное окно системного класса UPDOWN_CLASS, а компонент TUpDown— это только оболочка для него. Поэтому все необходимые перехваты мыши выполняются самой системой. VCL нет нужды в это вмешиваться. Чтобы избавиться от проблемы, нужно убрать csCaptureMouseиз списка стилей компонента. Делается это так: UpDown1.ControlStyle := UpDown1.ControlStyle - [csCaptureMouse]; Этот код достаточно выполнить один раз (например, в обработчике события OnCreateформы), и проблемы с зацикливанием исчезнут (в примере UpDownDlg эта строка закомментирована). Отметим, что в Windows предусмотрено специальное сообщение — WM_CANCELMODE, — посылаемое при открытии диалогового окна тому окну, которое захватило мышь, чтобы оно ее освободило. Один из способов решения проблемы — добавление в UpDown1обработчика этого сообщения (для этого можно написать наследника TUpDownили же воспользоваться свойством WindowProc— см. разд. 1.1.8), который отменит захват мыши. Отсутствие этого обработчика — тоже явная ошибка VCL. 3.4.3. Access violation при закрытии формы с перекрытым методом WndProcЧтобы увидеть этот "подводный камень", создадим проект, содержащий две формы: главную Form1и вспомогательную Form2. В Form1добавим код, который по нажатию кнопки открывает Form2. Во второй форме напишем обработчик события OnCloseтаким образом, чтобы он устанавливал по закрытию действие caFree. Добавим поле строкового типа, перекроем конструктор и метод WndProcтак, чтобы окончательный код выглядел следующим образом (листинг 3.52, пример CloseAV на компакт- диске). Листинг 3.52. Код класса TForm2 type TForm2 = class(TForm) procedure FormClose(Sender: TObject; var Action: TCloseAction); private S: string; protected procedure WndProc(var Message: TMessage); override; public constructor Create(AOwner: TComponent); override; end; .... constructor TForm2.Create(AOwner: TComponent); begin S := 'abc'; inherited; end; procedure TForm2.WndProc(var Message: TMessage); begin inherited; S[2] := 'x'; { * } end; procedure TForm2.FormClose(Sender: TObject; var Action: TCloseAction); begin Action := caFree; end; Обратите внимание, что в конструкторе сначала присваивается значение полю S, и лишь потом вызывается унаследованный конструктор. Это сделано потому, что по умолчанию Sсодержит пустую строку, т.е. nil, а уже при вызове унаследованного конструктора окно получит сообщения, для обработки которых будет вызван метод WndProc. Если в этот момент Sбудет по-прежнему nil, попытка обратиться ко второму символу строки вызовет Access violation. Поэтому еще до начала работы унаследованного конструктора поле Sдолжно получить подходящее значение. Запустим программу и попытаемся закрыть второе окно. Возникнет исключение Access Violation: Write of address 00000001. Проблема будет в строке, отмеченной {*}. При этом любые другие манипуляции с окном никаких исключений вызывать не будут. При Action = caFreeпосле завершения работы метода FormClose VCL вызывает метод TCustomForm.Release. Проблема именно в нем: если попытаться закрыть Form2с помощью Release, возникнет то же самое исключение. В справке Releaseпозиционируется как безопасный способ удаления формы из ее собственного метода. К сожалению, в действительности это не так: реализация этого удаления оставляет желать лучшего и может приводить к попыткам работать с объектом тогда, когда его уже не существует. При вызове Releaseв очередь помещается сообщение CM_RELEASE, адресатом которого является сама удаляемая форма. В очередном цикле петли сообщений CM_RELEASEизвлекается из очереди и передается на обработку. Так как сообщение адресовано форме, она же его и обрабатывает. Рассмотрим более подробно, как это происходит. (Детально механизм обработки сообщений в VCL описан в разд. 1.1.8; мы здесь рассмотрим только ту часть, которая относится к обработке CM_RELEASE.) Система передает управление оконной процедуре. Для каждого экземпляра визуального компонента VCL создает свою оконную процедуру с помощью MakeObjectInstance. Эта процедура вызывает метод объекта MainWndProc, передающий управление тому методу, на который указывает свойство WindowProc. По умолчанию это WndProc. WndProcне обрабатывает CM_RELEASEсамостоятельно, а передает его методу Dispatch. Dispatchпытается найти для этого сообщения специальный обработчик (метод с директивой message) и, т.к. в TCustomFormтакой обработчик описан (он называется CMRelease), передаёт управление ему. И здесь начинается самое интересное. CMRealeaseпросто вызывает Free, удаляя тем самым объект, т.е. объект удаляется из метода самого объекта, что делать запрещено. Таким образом, после выполнения Freeуправление вновь получает CMRealease. Из него управление возвращается в Dispatch, оттуда — в WndProc, затем — в MainWndProc, далее — в оконную процедуру, и только после этого управление получает код, который никак не связан с конкретным экземпляром компонента. Мы видим, что после обработки CM_RELEASEи удаления объекта его методы продолжают работать. Методы уже не существующего объекта! В принципе, методы несуществующего объекта могут вполне нормально завершить свою работу, если не будут обращаться к его полям или иным образом использовать указатель Self, который к этому моменту будет уже недействительным. Но стоило нам только вставить в один из этих методов код, задействующий поле объекта, как возникла ошибка. В данном примере получается следующее: сначала CM_RELEASEпередаётся стандартному обработчику, который вызывает деструктор. При работе деструктора финализируются все поля объекта, для которых это требуется. В нашем случае это означает, что в поле Sзаносится nil(освобождения памяти при этом не происходит, потому что Sдо этого ссылалась на литерал, хранящийся в кодовом сегменте, а не в динамической памяти). После этого начинает работать наш код, который пытается изменить второй символ в строке. Программа пытается обратиться к ячейке с адресом nil+ 1, т.е. 00000001, что и приводит к ошибке Access violation. Обращение в аналогичной ситуации к нефинализируемым полям (целым, вещественным, логическим и т. п.) обычно не приводит к исключению. Это связано с тем, что менеджер памяти Delphi обычно не сразу отдаёт системе ту память, которую освобождает объект, поэтому программа, с точки зрения системы, имеет полное право ею пользоваться. Поля объекта не очищаются, и его образ продолжает храниться в памяти, просто менеджер памяти помечает эту область как неиспользуемую и может в любой момент выделить ее для хранения другого объекта. Это создает иллюзию того, что объект продолжает существовать и позволяет работать с уже несуществующим объектом. Но это все равно некорректно, потому что любое перераспределение памяти в данной ситуации может привести к непонятной ошибке. Посмотрим. что будет, если строку S[1] := 'x'заменить на S := IntToStr(Msg.Msg). Как мы уже выяснили, после уничтожения объекта в той области памяти, где хранилось значение S, будет nil. Указатель на вновь созданную строку будет помещен в эту область памяти. Но к ней уже не будет применяться финализация, т.к. менеджер памяти будет считать эту область памяти финализированной. Произойдет утечка памяти. Отметим, что для вновь созданной строки память может быть выделена таким образом, что она наложится на те ячейки, в которых хранились значения полей уничтоженной формы, в том числе значение S. В этом случае попытка обратиться к такому полю приведет к непредсказуемым результатам. Аналогичная проблема может появляться не только при перекрытии WndProc, а вообще при любом способе внедрения своего кода в цепочку обработки так, чтобы он выполнялся после CMRelease. Совершенно непонятно, почему разработчики VCL реализовали такой заведомо некорректный механизм работы Release. Чтобы избежать всех описанных проблем, достаточно было бы просто посылать CM_RELEASEне самой форме, а окну, создаваемому объектом Application, а указатель на освобождаемую форму передавать через параметры этого сообщения. Тогда деструктор формы вызывался бы из метода объекта Application, и никаких проблем не было бы. Эта проблема обнаружена во всех версиях Delphi с 3-й по 2007-ю (в других версиях не проверялась). Самый простой способ ее преодоления — отмена опасных действий, если получено сообщение CM_RELEASE. Например, в описанном случае безопасным будет следующий код (листинг 3.53). Листинг 3.53. Безопасный вариант метода WndProc procedure TForm2.WndProc(var Message: TMessage); begin inherited; if Msg.Msg <> CM_RELEASE then s[2] := 'x'; end; Другой способ заключается в том. чтобы перенести обработку CM_RELEASEв объект Applicationс помощью его события OnMessage. Проблема заключается лишь в том, что адрес удаляемой формы будет неизвестен, но его легко найти по дескриптору окна. Например, в данном случае можно положить на первую форму TApplicationEventsи в его обработчике OnMessageнаписать следующий код (листинг 3.54; в примере CloseAV этот код закомментирован). Листинг 3.54. Обработка сообщения CM_RELEASEобъектом Application procedure TForm1.ApplicationEvents1Message(var Msg: tagMSG; var Handled: Boolean); var I: Integer; begin if Msg.Message = CM_RELEASE then for I := 0 to Screen.FormCount - 1 do if Screen. Forms[I].Handle = Msg.hwnd then begin Screen.Forms[I].Free; Handled := True; Exit; end; end; Событие OnMessageпозволяет перехватить сообщения до того, как они будут диспетчеризованы окну-адресату, соответственно, форма будет уничтожена раньше, чем начнет обрабатывать CM_RELEASE. 3.4.4. Подмена имени оконного класса, возвращаемого функцией GetClassInfoСоздадим новый проект в Delphi, поместим на форму кнопку и метку и создадим следующий обработчик нажатия кнопки (листинг 3.55, пример ClassName на компакт-диске). Листинг 3.55. Подмена имени оконного классаprocedure TForm1.Button1Click(Sender: TObject); var CI: TWndClass; S: string; procedure DoGetClassInfo; begin GetClassInfo(hInstance, PChar('TForm' + IntToStr(1)), CI); end; begin DoGetClassInfo; S := 'abcde' + IntToStr(2); Label1.Caption := CI.lpszClassName; end; Что будет выведено на экран в результате выполнения этого кода? Так как класс называется "TForm1", логично предположить, что именно это и будет выведено. На самом деле мы увидим abcde2 — ту строку, которая присвоена переменной S. Разберемся, как значение переменной Sоказывается в поле CI.lpszClassName. Согласно MSDN поле lpszClassNameимеет тип LPCTSTR(PChar), и в него функция GetClassInfoзаносит указатель на строку, содержащую имя оконного класса. Но нигде не сказано, в какой области памяти должна располагаться эта строка. Функция GetClassInfoпоступает очень просто, но не совсем корректно: один из ее аргументов — указатель на строку с именем класса. Именно его функция и помещает в lpszClassName. В приведенном примере в качестве аргумента GetClassInfoпередаётся выражение типа string, приведенное к PChar, которое не может быть вычислено на этапе компиляции, поэтому компилятор генерирует код, вычисляющий данное выражение. Этот код размещает вычисленное выражение в динамической памяти, и в GetClassInfoпередаётся указатель на эту строку. Все строковые выражения, вычисленные подобным образом, должны удаляться из памяти, чтобы не было утечек. Компилятор помещает код, освобождающий эту память, в эпилог той функции, в которой встретилось выражение. В данном случае — в эпилог локальной процедуры DoGetClassInfo. Освободившуюся память менеджер памяти не сразу возвращает системе придерживает, чтобы иметь возможность быстрее выделить память при следующем запросе. Таким образом, после завершения работы DoGetClassInfoпамять, в которой хранится вычисленное имя оконного класса (и на которую указывает CI.lpszClassName), по-прежнему принадлежит процессу, но менеджер памяти полагает ее свободной и считает себя вправе использовать ее по своему усмотрению. Когда присваивается значение переменной S, для размещения новой строки менеджер памяти выделяет ту самую область, в которой ранее хранилось имя класса. Так как CI.lpszClassNameпо-прежнему содержит этот адрес, обращение к этому полю возвращает новую строку, которая присвоена переменной S. Примечание Если в данном примере не выносить вызов функции GetClassInfoв отдельную процедуру DoGetClassInfo, а вызывать ее напрямую из Button1Click, описанного эффекта не будет, потому что в этом случае освобождение памяти, занятой для вычисленного имени класса, будет производиться в эпилоге Button1Click, и на момент присваивания значения переменной Sэта память будет считаться занятой, поэтому для Sменеджер памяти выделит другую область. Принципиально и то, что в обоих случаях (в функции GetClassInfoи при присваивании значения переменной S) используются не строковые литералы, а выражения, вычисляемые только на этапе выполнения программы. Строковые литералы размещаются компилятором в сегменте кода, и указатели, переданные в GetClassInfoи присвоенные переменной S, будут указывать не на динамическую память, а на эти литералы, и подмены не произойдет. Избежать проблемы можно двумя способами. Во-первых, не следует передавать значение поля lpszClassNameза пределы той функции, в которой была вызвана GetClassName. Во-вторых, имя оконного класса должно быть известно программе до вызова GetClassName. Лучше использовать ту строку, в которой хранится это имя, чем поле lpszClassName. 3.4.5. Ошибка EReadError при использовании вещественных свойствЕсли в секции publishedкомпонента имеются свойства вещественного типа ( Single, Doubleили Extended), то попытка присвоить в режиме проектирования формы этим свойствам некоторые вполне корректные значения приводит к ошибке EReadErrorпри чтении ресурсов формы (т.е. при создании формы). Для типов Doubleи Extendedошибка возникает, если значение свойства Xлежит в одном из указанных диапазонов: -1e15 < х <= MinInt - 1 или MaxInt + 1 <= X < 1e15 Не совсем понятно, при чем здесь значения MaxIntи MinInt, если речь идет о вещественных числах, но проблема существует. Типу Singleне хватает точности, чтобы передавать значения MaxIntи MinIntбез искажений. Тем не менее, с поправкой на уменьшение точности границ диапазонов, эта же ошибка возникает и для свойств типа Single. Ошибка возникает только в случае текстовой формы dfm-файла (все версии Delphi, начиная с пятой, по умолчанию используют эту форму). При бинарной форме dfm-файла ошибки не происходит. Ошибка обнаружена в Delphi 5 и 6, причем в Delphi 5 попытка ввести значение из указанного диапазона также может привести к ошибке и в режиме проектирования, при переключении между текстом модуля и формой. В Delphi 6 были замечены ошибки только при запуске программы, в режиме проектирования они не возникали. В Delphi 7 эта проблема уже решена, указанные значения свойств не приводят к ошибкам. В более ранних версиях Delphi проблема, естественно, также отсутствует, потому что в них dfm-файл всегда представляется в бинарной форме. Для решения проблемы могут быть рекомендованы два способа. 1. Обновить Delphi до седьмой (или более поздней) версии. 2. Выбрать бинарную форму dfm-файла. Для этого нужно щёлкнуть правой кнопкой мыши на форме и в открывшемся меню убрать галочки с пункта Text DFM. Можно также отказаться от присвоения проблемных значений свойствам в режиме проектирования и присваивать их во время выполнения программы. 3.4.6. Ошибка List index out of bounds при корректном значении индексаWindows позволяет с каждой строкой списка элементов управления ListBoхи ComboBoxсвязать либо число, либо указатель (точнее — некоторую четырехбайтную величину, которую программа может трактовать как число, как указатель или как что-либо еще). В VCL эта возможность обеспечивает привязку к строкам списка объектов (четырёхбайтная величина по умолчанию трактуется как TObject). Доступ к этим объектам осуществляется через свойства TComboBox.Items.Objects[Index]и TListBox.Items.Objects[Index]. Иногда все-таки требуется привязывать к строкам не объекты, а числа. Для этого можно воспользоваться явным приведением типов, например: ComboBox1.Items.Objects[I] := TObject(17); I := Integer(ComboBox1.Items.Objects[I]); Если таким образом связать со строкой значение -1, то при попытке получить его во всех версиях Delphi до 7-й включительно возникнет исключение EStringListErrorс комментарием "List index out of bounds". Рассмотрим следующий код (листинг 3.56. пример ListIndex на компакт-диске). Листинг 3.56. Пример кода, вызывающего исключение EStringListError procedure TForm1.Button1Click(Sender: TObject); var I: Integer; begin ComboBox1.Items.Clear; ComboBox1.Items.AddObject('Text', TObject(-1)); I := Integer(ComboBox1.Items.Objects[0]); { * } Label1.Caption := IntToStr(I); end; Исключение возникнет при попытке выполнить строку, отмеченную звездочкой, хотя очевидно, что индекс в данном случае корректен. Чтобы понять причину ошибки, необходимо рассмотреть, как осуществляется чтение значения, привязанного к строке, на уровне Windows API. Рассмотрим это на примере TComboBox. Для получения значения необходимо послать окну ComboBoxсообщение CB_GETITEMDATA. Результатом обработки этого сообщения будет значение, связанное с указанной строкой, или CB_ERR, если при обработке сообщения возникнет ошибка. При этом документация не уточняет, какие именно ошибки могут в принципе возникнуть и как узнать, какая из них произошла. Метод TComboBoxStrings.GetObject, через который читается значение свойства Objects, в Delphi 7 и более ранних версиях интерпретирует получение CB_ERRоднозначно: генерирует исключение EStringListErrorс комментарием "List index out of bounds". Проблема заключается в том, что константа CB_ERRимеет численное значение -1. Поэтому и в случае ошибки, и в случае, когда строке сопоставлено значение -1, системный обработчик сообщения CB_GETITEMDATAвернет одинаковый результат. И метод TComboBoxStrings.GetObjectинтерпретирует его как ошибку. (А что ему еще остается делать?) Аналогичная проблема по тем же причинам возникает и для ListBox(аналогичная по смыслу константа LB_ERRтакже имеет значение -1). Это прямое следствие документированных особенностей работы Windows и модели работы VCL встречается во всех версиях Windows. Та же проблема возникает при попытке указать значение 4 294 967 295, т.к. на двоичном уровне это число записывается той же комбинацией битов, что и -1. При использовании свойства Objectsпо прямому назначению, т.е. для хранения объектов, эта проблема не может возникнуть, потому что $FFFFFFFF — это адрес самого старшего байта в четырехгигабайтном виртуальном адресном пространстве программы. Эта область адресного пространства зарезервирована системой, и менеджер памяти Delphi не может выделить память для объекта в этой области. Рекомендуемые способы решения проблемы: 1. Пересмотреть алгоритм и отказаться от связывания значения -1 со строками. 2. Напрямую посылать CB_GETITEMDATAокну ComboBox, а попадание индекса в диапазон контролировать самостоятельно другими методами. Приведенный в листинге 3.57 код иллюстрирует последний совет. Листинг 3.57. Получение связанного с элементом значения вручную procedure TForm1.Button2Click(Sender: TObject); var I: Integer; begin ComboBox1.Items.Clear; ComboBox1.Items.AddObject('Text', TObject(-1)); I := SendMessage(ComboBox1.Handle, CB_GETITEMDATA, 0, 0); Label1.Caption := IntToStr(I); end; Как уже было отмечено ранее, в BDS 2006 и более поздних версиях исключение не возникает. Это связано с новой реализацией метода TCustomComboBoxStrings.GetObject, который отвечает за получение значения свойства Items.Object(листинг 3.58). Листинг 3.58. Получение значения свойства Items.Objectв BDS 2006 и выше function TCustomComboBoxStrings.GetObject(Index: Integer): TObject; begin Result := TObject(SendMessage(ComboBox.Handle, CB_GETITEMDATA, Index, 0)); // Do additional checking on Count and Index here is so in the event // the object being retrieved is the integer -1 the call will succeed if (Longint(Result) = CB_ERR) and ((Count = 0) or (Index < 0) or (Index > Count)) then Error(SListIndexError, Index); end; Решение спорное, т.к. проверка корректности системой дополняется собственной проверкой индекса, и не совсем понятно, что делать в том случае, если система фиксирует какую-либо ошибку, не связанную с индексом. Но здесь Windows ставит разработчика в такие условия, что любое решение будет спорным, так что упреком по отношению к разработчикам VCL такая оценка их решения не является. В таких элементах управления, как TListViewи TTreeView, тоже существует возможность связывания 4-байтного значения с элементом (см. свойства TTreeNode.Data, TListItem.Data), но сообщения TVM_GETITEMи LVM_GETITEM, через которые можно получить значения этих свойств, устроены иначе, поэтому связывание с элементом значения -1 (а также любого другого 4-байтного значения) не приводит к аналогичным проблемам. 3.4.7. Неправильное поведение свойства AnchorsСвойство Anchors, появившееся в Delphi 5, является очень удобным средством управления положением и размерами визуальных компонентов при изменении размера родителя. Однако в тех случаях, когда начальные размеры формы по каким-то причинам не совпадают с установленными при проектировании, задание значения свойства Anchorsне приносит желаемого эффекта: первоначальное расположение визуальных компонентов на форме соответствует размерам, установленным при проектировании, а не тем, которые реально получила форма. Примеры такого некорректного поведения демонстрирует программа WrongAnchors на компакт-диске. Программа WrongAnchors — это MDI-приложение, в котором открываются две дочерние формы разных классов: ChildForm1(класс TChildForm1) и ChildForm2(класс TChildForm2). Во время проектирования эти две формы выглядят совершенно одинаково, но при запуске программы только вторая форма сохраняет заданные при проектировании размеры, а первая становится больше. При этом панель, лежащая на ней, не адаптирует свои размеры к изменившемуся размеру формы, хотя свойство Anchors обязывает ее к этому (это легко видеть, изменяя размеры формы после ее создания). Самый простой способ борьбы с этой неприятностью — заставить дочернюю MDI-форму иметь такой же начальный размер, какой задан при проектировании. Дочерняя MDI-форма приобретает отличный от заданного размер потому, что метод CreateParamsдля ширины и высоты окна устанавливает не те значения, которые хранятся в свойствах Widthи Height, а значение CW_USERDEFAULT. Это значение говорит системе, что она должна выбрать размеры окна на свое усмотрение. Чтобы этого не происходило, нужно вновь вернуть установленные при проектировании значения ширины и высоты в перекрытом методе CreateParams. Именно этим класс TChildForm2отличается от TChildForm1(листинг 3.59). Листинг 3.59. Установка значений ширины и высоты, заданных при проектировании procedure TChildForm2.CreateParams(var Params: TCreateParams); begin inherited CreateParams(Params); Params.Width := Width; Params.Height : = Height; end; Значение CW_USERDEFAULTприсваивается ширине и высоте окна не только в том случае, если это дочерняя MDI-форма, но и когда значение свойства Positionформы равно poDefaultили poDefaultSizeOnly. Но в этом случае перекрывать CreateParamsнет нужды, достаточно просто изменить значение свойства Positionна другое. Просто необходимо помнить, что если свойство Positionформы имеет одно из этих значений, свойства Anchorsлежащих на форме компонентов должны иметь значения по умолчанию. Другой случай, когда окно может при создании иметь размеры, отличные от заданных при проектировании, — это когда свойство WindowStateравно wsMaximized. При этом окно растягивается на весь экран. В примере WrongAnchors в главном меню есть пункты Развернутое окно 1 и Развернутое окно 2, которые открывают диалоговые окна, развернутые на весь экран. Но в первом из этих окон панель опять не адаптируется к новым размеру окна, в то время как во втором — адаптируется, хотя значения свойства Anchorsу обеих панелей одинаковые. Это происходит потому, что в первом случае значение wsMaximizedприсваивается свойству WindowStateво время проектирования, и поэтому окно сразу создается развернутым. А во втором случае значение wsMaximizedприсваивается свойству WindowStateтолько при обработке события OnShowформы, т.е. тогда, когда форма уже создана с заданными при проектировании размерами, но еще не видна на экране. При этом свойство Anchorsработает так, как требуется. Это и есть решение проблемы — значение свойству WindowState нужно присваивать не во время проектирования, а в обработчике события OnShow. Но самое интересное происходит, если свойство WindowStateво время проектирования получило значение wsMaximized, а свойство Position— значение poDefaultили poDefaultSizeOnly. Тогда размеры и положения визуальных компонентов на форме будут адаптированы к размеру, который не совпадает ни с размером развернутой формы, ни с размером, заданным во время проектирования. Если такой форме отменить развертывание на весь экран, то визуальные компоненты получат размеры и положения, установленные в режиме проектирования. Нельзя сказать, что разработчики Delphi не знакомы с этой проблемой, они даже что-то делают, чтобы ее решить. Начиная с BDS 2006 можно устанавливать значение свойства WindowStateв режиме проектирования, и визуальные компоненты на такой форме будут вести себя интуитивно ожидаемым образом, т.е. адаптироваться к размеру формы, растянутой на весь экран. Правда, с двумя существенными оговорками. Во-первых, свойство Position формы не должно быть равно poDefaultили poDefaultSizeOnly. Во-вторых, это относится только к главной форме приложения, для всех остальных форм проблема сохраняется. Поэтому пример WrongAnchors будет работать одинаково и в новых версиях Delphi, и в старых — там на весь экран разворачиваются не главные формы. 3.4.8. Ошибка при сравнении указателей на методПроцедурные типы в Delphi делятся на обычные (унаследованные от Turbo Pascal) и указатели на методы. Первые — что указатели на простые процедуры и функции, вторые — на методы объектов. Чтобы вызвать метод объекта недостаточно знать, где его код располагается в памяти, нужно еще иметь ссылку на конкретный экземпляр класса, к которому относится данный метод (т.е. необходимо значение указателя Self, который будет передан в данный метод). Поэтому указатели на методы называются указателями лишь условно: на самом деле это не один указатель, а два (на код и на объект). Размер переменных такого типа равен 8 байтам, в чем нетрудно убедиться с помощью функции SizeOf. Очевидно, что два указателя на метод равны тогда и только тогда, когда указывают на один и тот же метод одного и того же объекта, т.е. входящие в них указатели попарно равны. Однако компилятор сравнивает указатели на методы неправильно, и пример MethodPtrCmpна компакт-диске демонстрирует это. На форме этого примера расположены две кнопки класса TButton. Обработчик нажатия на первую из них выглядит так, как в листинге 3.60. Листинг 3.60. Пример неправильного сравнения указателей на метод procedure TForm1.ButtonlClick(Sender: TObject); var P1, P2: procedure of object; begin P1 := Button1.Update; P2 := Button2.Update; // Здесь компилятор сравнивает указатели на методы неверно, // давая ошибочный результат "равно" if @Р1 = @Р2 then Label1.Caption := 'Равно' else Label1.Caption := 'Не равно'; end; Здесь мы получаем указатели на один и тот же метод разных объектов (для примера взяты класс TButtonи метод Update, но подошел бы любой класс и любой метод). Сравнение указателей в этом примере дает ошибочный результат Равно, хотя эти указатели не равны между собой. Просмотр кода, который генерирует компилятор, показывает, что здесь сравниваются только указатели на код метода, а указатели на объекты игнорируются. Так как у нас метод один и тот же, различаются только объекты, то и получается ошибочный результат. Сравнить указатели на методы правильно можно с помощью типа TMethodиз модуля SysUtils, объявленного следующим образом: TMethod = record Code, Data: Pointer; end; Так можно получать доступ к отдельным указателям, входящим в указатель на метод. Сравнение указателей на метод с помощью этого типа иллюстрирует листинг 3.61. Листинг 3.61. Правильный способ сравнения указателей на методprocedure TForm1.Button2Click(Sender: TObject); var P1, P2: procedure of object; begin P1 := Button1.Update; P2 := Button2.Update; // Правильный способ сравнения указателей на методы if (TMethod(P1).Data = TMethod(P2).Data) and (TMethod(P1).Code = TMethod(P2).Code) then Label1.Caption := 'Равно' else Label1.Caption := 'He равно'; end; Здесь мы явным образом заставляем компилятор сравнивать оба указателя, поэтому получаем правильный результат Не равно. 3.4.9. Возможность получения адреса свойстваПусть у нас есть класс, описанный следующим образом (листинг 3.62). Листинг 3.62. Класс со свойствами, читаемыми из переменной и из функцииTSomeClass = class private FProp1: Integer; function GetProp2: Integer; public property Prop1: Integer read FProp1; property Prop2: Integer read GetProp2; end; В этом классе два свойства Prop1и Prop2, значение одного из которых определяется полем FProp1, а другого — функцией GetProp2. Оба свойства предназначены только для чтения, но для того эффекта, о котором здесь пойдет речь, это не принципиально: свойства, значения которых можно менять, ведут себя в этом отношении точно так же. Пусть X— это переменная типа TSomeClass. Легко убедиться, что компилятор допускает получение адреса свойства Prop1, т.е. конструкция вида @X.Prop1считается допустимой. Результатом выполнении этого оператора станет указатель на поле FProp1. А вот конструкцию @X.Prop2компилятор не допускает, выдаёт ошибку Variable required. Ошибкой компилятора здесь является то, что он допускает получение адреса в первом случае, т.е. для свойства, значение которой берется из переменной. Это грубейшее нарушение принципа инкапсуляции, лежащего в основе объектно-ориентированного программирования, причем сразу по двум причинам. Во-первых, пользователь класса не должен видеть его внутреннюю реализацию, а здесь пользователь может определить, как читается свойство, по возможности применения оператора @к нему. Во-вторых, пользователь класса должен взаимодействовать с ним строго через предоставленный интерфейс, а у нас получается, что, узнав адрес поля FProp1, пользователь сможет менять его значение в обход предусмотренных для этого в классе механизмов. К счастью, ситуации, в которых эта недоработка компилятора могла бы принести пользу, крайне редки. Но если вы все-таки столкнулись с такой ситуацией, настоятельно рекомендуем не поддаваться соблазну и искать другие способы решения проблемы. Если класс, к полю которого вы хотите получить доступ таким образом, написан вами, то это веский повод пересмотреть внешний интерфейс класса, т.к. при его проектировании скорее всего, были допущены серьезные ошибки. Если это «чужой» класс, подумайте о том, что в следующей версии этого класса автор может изменить реализация свойства, и тогда ваш код откажется компилироваться. 3.4.10. Невозможность использования некоторых свойств оконного компонента в деструктореПроблема, о которой пойдет речь в этом разделе, гораздо шире, чем это явствует из заголовка. Однако наиболее ярко она проявится именно в этом случае. Поэтому мы начнем именно с этой ситуации, а потом рассмотрим проблему более широко. Проблему демонстрирует пример ParentWnd на компакт-диске. В нем создан компонент TWrongCombo, наследник TComboBox. Листинг 5.67 содержит код компонента. Листинг 3.63. Компонент TWrongCombo type TWrongCombo = class(TComboBox) public destructor Destroy; override; procedure AddItem(const Title: string); end; destructor TWrongCombo.Destroy; var I: Integer; begin for I := 0 to Items.Count - 1 do if Assigned(Items.Objects[I]) then Dispose(PDateTime(Items.Objects(I])); inherited; end; procedure TWrongCombo.AddItem(const Title: string); var P: PDateTime; begin New(P); P^ := Now; Items.AddObject(Title, TObject(P)); end; Класс TWrongComboс каждым элементом, добавленным с помощью метода AddItem, связывает значение типа TDateTime, хранящее время добавления элемента. В разд. 3.4.6 мы уже познакомились с возможностью связывания данных с элементом списка с помощью свойства Items.Objects. Но так мы можем связать с элементом только 4-байтное значение, а тип TDateTimeзанимает 8 байтов. Поэтому значение TDateTimeмы будем хранить в динамической памяти, а с элементом свяжем указатель на него. Раз мы выделили динамическую память, ее нужно освободить при удалении компонента. Наиболее подходящим местом для этого кажется деструктор, и именно в нем помещен код освобождения выделенной памяти. Теперь попробуем воспользоваться компонентом. На главной форме программы ParentWndнаходится кнопка Wrong Combo, при нажатии на которую создается компонент типа TWrongCombo(листинг 3.64). Листинг 3.64. Реакция на кнопку Wrong Combo procedure TForm1.BtnWrongComboClick(Sender: TObject); begin if FWrongCombo = nil then begin FWrongCombo := TWrongCombo.Create(Self); FWrongCombo.Left := 10; FWrongCombo.Top := 10; FWrongCombo.Parent := Self; FWrongCombo.AddItem('One'); FWrongCombo.AddItem('Two'); FWrongCombo.AddItem('Three'); end; end; Теперь, если нажать эту кнопку и затем попытаться закрыть форму, в деструкторе TWrongComboвозникнет исключение EInvalidOperationс сообщением "Control has no parent window". Если откомпилировать программу с включенной опцией Use Debug DCUs, видно, что исключение возникает в методе TWinControl.CreateWnd. Одно только это способно обескуражить — действительно, зачем метод создания окна вызывается при его удалении? Причина заключается в том, что к моменту вызова деструктора окно компонента уже удалено, свойство Handleимеет нулевое значение, и свойство Parentтоже имеет значение nil. Обращение к свойству Items.Countприводит к отправке окну сообщения CB_GETCOUNT. Отправка осуществляется с помощью функции SendMessage, одним из параметров которой является дескриптор окна, в качестве которого, естественно, передается свойство Handle. А это свойство, напомним, к этому моменту равно нулю. В разд. 1.1.7 обсуждалось, что обращение к этому свойству в тот момент, когда оно равно нулю, приводит к попытке создания окна (см. листинг 1.8). Именно поэтому вызывается метод CreateWnd. И он возбуждает исключение, потому что окно, которое создает компонент TWrongCombo, имеет стиль WS_CHILD, т.е. не может не иметь родителя. А родитель компоненту не назначен, поэтому и возникает исключение с таким странным, на первый взгляд, сообщением. Отсюда следует важный вывод, что никакое обращение в деструкторе компонента к тем свойствам и методам, которые требуют наличия окна, невозможно. Окно уже удалено, а попытка создания нового окна приведет к исключению. Поэтому, например, в нашем коде требуется искать другое место, чтобы корректно освободить занятую память. Поиск этого места оказывается не такой простой задачей, как хотелось бы, потому что разработчики VCL весьма странным образом реализовали удаление дочерних оконных компонентов в деструкторе класса TWinControl: сначала вызывается системная функция DestroyWindow, которая удаляет и само окно, и, разумеется, все дочерние окна, а потом только дочерние компоненты начинают уведомляться о том, что их удаляют, т.е. к этому моменту они уже не имеют возможности как-то задействовать свои окна. Соответственно, в нашем случае деструктор формы уничтожает окна всех дочерних компонентов до того, как будут вызваны деструкторы этих компонентов. Положение спасает то, что об уведомлении окон заботится система Windows: всем окнам, которые удаляются в результате вызова функции DestroyWindow, отправляется сообщение WM_DESTROY, причем в момент получения этого сообщения ни окно, ни его родитель еще не уничтожены. Это позволяет компоненту как-то реагировать на свое удаление до того, как окно будет уничтожено. Казалось бы, выход найден: нужно освобождать память в обработчике сообщения WM_DESTROY. Но и тут не все так просто. Дело в том, что окно может уничтожаться не только при удалении компонента, но и при изменении некоторых свойств (например, Parent). При этом окно удаляется, а вместо него создается новое, и при удалении старого окна компонент тоже получает сообщение WM_DESTROY. Что же касается компонента TComboBox, он обеспечивает, что при удалении и последующем создании окна все элементы, в том числе связанные с ними значения, восстанавливаются. Таким образом, если мы в наследнике TComboBoxв обработчике сообщения WM_DESTROYвсегда будем освобождать выделенную память, после повторного создания окна получим "битые" ссылки в свойстве Items.Objects, чего, естественно, хотелось бы избежать. Требуется научиться отличать полное удаление компонента от удаления окна с целью повторного создания. Вообще говоря, механизм для этого предусмотрен в VCL — это флаг csDestroyingв свойстве ComponentState. Выполнение деструктора TWinControl.Destroyначинается с вызова метода Destroying, добавляющего этот флаг во всех компонентах, которыми владеет данный компонент. Однако по наличию этого флага у компонента мы не можем в обработчике WM_DESTROYузнать, удаляется весь компонент, или только окно для создания заново. Рассмотрим, например, ситуацию, когда на форму во время проектирования разработчик положил панель, а на эту панель — любой оконный компонент, например, кнопку. Владельцем кнопки в этом случае все равно является форма, а панель — только родителем. Если теперь удалить панель, не удаляя форму, метод Destroyingпанели не затронет кнопку, и на момент получения кнопкой сообщения WM_DESTROYфлаг csDestroyingу нее еще не будет установлен, несмотря на то, что кнопка удаляется. Тем не менее флаг csDestroyingвсе же может помочь нам. Компонент удаляется в одном из трех случаев: 1. Удаляется непосредственно данный компонент. 2. Удаляется владелец компонента. 3. Удаляется родитель компонента. В первом случае удаление начинается не с удаления окна, а с вызова деструктора компонента, и окно компонент удаляет уже сам, когда флаг csD estroying установлен деструктором. Во втором случае деструктор владельца, прежде чем удалить окно, заботится о том, чтобы компонент получил флаг csDestroying, поэтому даже если владелец является одновременно и родителем, флаг у компонента в момент удаления окна уже будет. И, наконец, остается третья ситуация, в которой флага csDestroyingу компонента может и не быть. Но в любом случае удаление цепочки компонентов начинается с вызова деструктора "главного" из них. По линии владельца флаг csDestroyingпередается, по линии родителя — нет, но самый верхний из цепочки родителей обязательно имеет такой флаг. Соответственно, чтобы определить, удаляется ли окно из-за уничтожения визуального компонента, нужно искать флаг csDestroyingне только у самого компонента, но и у всей цепочки его родителей. Если флаг нигде не найден, значит, удаляется только окно, но не сам компонент. На главном окне примера ParentWnd есть также кнопка Right Combo, которая создает на форме визуальный компонент типа TRightCombo. Это правильный вариант класса TWrongCombo, в котором деструктор не переопределяется, а обработчик сообщения WM_DESTROYреализован в соответствии с тем, что написано ранее (листинг 3.65). Листинг 3.65. Обработчик сообщения WM_DESTROYкласса TRightCombo procedure TRightCombo.WMDestroy(var Msg: TMessage); var I: integer; FinalDestruction: Boolean; P: TControl; begin FinalDestruction := False; P := Self; while Assigned(P) do begin if csDestroying in F.ComponentState then begin FinalDestruction := True; Break; end; P := P.Parent; end; if FinalDestruction then for I := 0 to Items.Count - 1 do Dispose(PDateTime(Items.Objects[I])); inherited; end; Такой компонент корректно освобождает память при его удалении, но не освобождает ее тогда, когда окно создается заново. Примечание Чтобы убедиться, насколько некорректно реализовано удаление компонентов в VCL, рассмотрим еще один пример (на компакт-диске он называется FrameDel). В этом примере на форму помещается фрейм с одним компонентом типа TComboBox. Код фрейма показан в листинге 3.66. Листинг 3.66. Код фрейма type TFrame1 = class(TFrame) ComboBox1: TComboBox; private { Private declarations } public destructor Destroy; override; procedure AddComboItem; end; destructor TFrame1.Destroy; var I: Integer; begin for I := 0 to ComboBox1.Items.Count - 1 do if Assigned(ComboBox1.Items.Objects[I]) then Dispose(PDateTime(ComboBox1.Items.Objects[I])); inherited; end; procedure TFrame1.AddComboItem; var P: PDateTime; begin New(P); P^:= Now; ComboBox1.Items.AddObject('Item ' + TimeToStr(P^), TObject(P)); end; На форму в обработчике события OnShowпомещается такой фрейм и вызывается его метод AddComboItem, чтобы в компоненте ComboBox1появился один элемент в списке. Если закрыть такую форму, никаких исключений не возникает, все выглядит нормально. Но при трассировке можно заметить, что цикл внутри деструктора не выполняется ни разу, потому что ComboBox1.Items.Countвозвращает 0. Это происходит потому, что на момент вызова этого деструктора и окно фрейма, и окно ComboBox1уже не существуют, в чем легко убедиться, проверив в деструкторе значение поля ComboBox1.FHandle(до обращения к свойству ComboBox1.Items.Countоно равно нулю). А при обращении к этому свойству происходит попытка создать окно. Так как свойство TComboBox1.Parentв этот момент еще не обнулено, предпринимается попытка создать заново и фрейм тоже, и эта попытка становится успешной. К этому моменту свойство Parentфрейма уже обнулено, но метод TCustomFrame.CreateParamsреализован таким образом, что родителем всех фреймов, для которых родитель не задан явно, становится невидимое окно приложения, которое на этот момент еще не разрушено. Таким образом, окно фрейма и окно компонента TComboBox1успешно создаются заново, и им можно посылать сообщения. Ранее мы говорили, что код компонента TComboBoxобеспечивает перенос элементов при удалении и последующем создании окна. Но в данном случае этот код даже не догадывается, что после удаления окно может быть создано ещё раз, и потому механизм переноса не задействуется. Вновь созданное окно компонента ComboBox1не получает в свой список ни одного элемента, что и приводит к тому, что свойство Items.Countравно нулю. Но динамическая память, выделенная в методе AddComboItemостается не освобождённой. В результате имеем утечку памяти вместо исключения. Кроме того, имеем утечку и других ресурсов, т.к. код, ответственный за удаление окна фрейма, на этот момент уже отработал и не будет запущен еще раз, чтобы удалить вновь созданное окно. Решением проблемы может стать уже опробованный способ: нужно обрабатывать сообщение WM_DESTROY, посылаемое фрейму, выполнять в нем все те же проверки, что и в листинге 3.65, и при необходимости освобождать память, которую нельзя освободить в деструкторе. Примечание Главным выводом этого раздела должно стать то, что последовательность удаления визуальных компонентов в VCL очень плохо продумана (видимо, это одно из самых неудачных мест в VCL), поэтому нужно соблюдать особую осторожность в тех случаях, когда освобождение ресурсов удаляемого оконного компонента может быть связано с обращением к его окну. Деструктор для этих целей, как мы убедились, не подходит, удаление следует выполнять в обработчике WM_DESTROY, проверяя, действительно ли удаляется сам компонент, а не только его окно. |
|
||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||||||||||||||||||||
|
|
||||||||||||||||||||||