|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Глава 8Маршрутизация в IP 8.1 ВведениеМаршрутизация — наиболее важная функция протокола IP. В больших сетях маршрутизаторы IP обмениваются информацией для сохранения корректного состояния своих таблиц маршрутизации. Каким образом это выполняется? Единого протокола для изменения информации в таблицах маршрутизации IP не существует. Поэтому сетевой администратор может выбрать любой протокол для маршрутизации информации, наиболее соответствующий требованиям конкретной сети. За прошедшие годы было разработано и улучшено несколько протоколов, ставших стандартами для групп производителей оборудования. По давней традиции они называются протоколами внутреннего шлюза (Interior Gateway Protocol — IGP). Иногда эту аббревиатуру расшифровывают как Internal Gateway Protocol, что по-русски означает то же самое. Отделение способа изменения таблиц маршрутизации от оставшейся части IP — это очень удачная идея. Маршрутизация становится все более совершенной и эффективной, в то время как базовые основы IP остаются неизменными. На сегодняшний день широко используется несколько протоколов IGP. Остается очень популярным протокол информации о маршрутизации (Routing Information Protocol — RIP), выбирающий маршрут на основе оценки простого счетчика попаданий. Сайты с маршрутизаторами компании Cisco часто выбирают лицензированные протоколы этой компании — протокол маршрутизации шлюзов Интернета (Internet Gateway Routing Protocol — IGRP) или улучшенный протокол IGRP (Enhanced IGRP — EIGRP), в которых применяется весьма сложный способ измерения стоимости, учитывающий множество факторов, включая нагрузку и надежность. Более сложный протокол, предлагающий первым открывать кратчайший путь (Open Shortest Path First — OSPF), применяется в больших сетях. Некоторые организации используют протокол от одной промежуточной системы к другой (Intermediate System to Intermediate System — IS-IS), который может маршрутизировать как трафик IP, так и OSI. Протоколы OSPF и IS-IS формируют подробные карты для сетей и генерируют пути перед выбором маршрута. Предоставление свободы выбора протокола для организации конечного пользователя реализуется прекрасно. Однако необходим стандарт для маршрутизации в сети провайдера при соединении между собой сетей конечных пользователей. Хотя еще применяют устаревший протокол внешнего шлюза (Exterior Gateway Protocol — EGP), большинство провайдеров перешло на протокол граничного шлюза (Border Gateway Protocol — BGP). В этой главе мы познакомимся с каждым из упомянутых выше протоколов и рассмотрим различия в предоставляемых ими возможностях. 8.2 Автономные системыКак можно предоставить столько различных возможностей при выборе протокола маршрутизации? Модель Интернета разделяет весь мир (как всегда, имеется в виду сетевой мир. — Прим. пер.) на элементы, именуемые автономными системами (Autonomous System — AS). Грубо говоря, автономной системой является чья-то сеть. Более формальное определение:
Более важно то, что создающая автономную систему подсеть находится под единым управлением. Типичной автономной системой является сеть компании или провайдера. Реально никому нет дела до автономной системы, пока не возникает потребность во взаимодействии с ней. В этом случае нужно зарегистрироваться в InterNIC и получить собственный номер автономной системы (Autonomous System Number). На рис. 8.1 показаны компании, провайдеры, автономные системы и использование ими протоколов IGP и BGP. Часто нет нужды в обмене информацией о маршрутизации между компанией и провайдером, а необходимые для этого сведения можно ввести вручную. 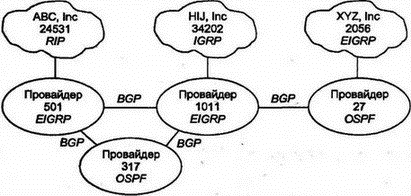 Рис. 8.1. Автономные системы и протоколы маршрутизации Администратор сети организации самостоятельно выбирает типы маршрутизаторов для внутреннего использования, как и протокол (протоколы) маршрутизации. Как же объединяются автономные системы? Способ для этого найден в Интернете уже много лет назад. Как можно догадаться, уникальный номер автономной системы играет в этом основную роль. Протокол внешнего шлюза (External Gateway Protocol — EGP) использует такие номера и выполняет всю необходимую работу. Определение автономных систем и используемых для них номеров было изменено в 1996 г. Провайдерам делегируются полномочия на большие блоки адресов, а далее провайдеры предоставляют своим клиентам подблоки адресов. Трафик к провайдеру можно маршрутизировать с использованием более краткого префикса. Затем провайдер добавляет более длинный префикс для идентификации клиента во внешнем мире. Для маршрутизации номер автономной системы идентифицирует весь кластер сети, состоящий из сети провайдера и всех сетей его клиентов. Как отмечено в RFC 1930, новое определение для автономной системы такое:
Многие подключенные к Интернету сети имеют очень простую политику маршрутизации, т.е. один провайдер обеспечивает обмен данными с другими сетями Интернета. Такие сети не имеют отдельного номера автономной системы. Однако коммерческие организации могут иметь несколько провайдеров или использовать Интернет как недорогое средство для общения с клиентами и поставщиками, или ограничивать коммуникационные возможности своих сайтов. Таким организациям необходим собственный номер автономной системы, который будет использован как индекс при определении и реализации политики маршрутизации. IANA определила один из блоков IP-адресов для личного (не общедоступного) использования. Для получения личного номера автономной системы можно воспользоваться зарезервированным IANA диапазоном от 64 512 до 65 535. 8.3 Маршрутизация в IPДатаграмма IP следует по пути, состоящему из участков попаданий, первый из которых формируется при выходе из узла в смежную с ним локальную или региональную сеть. Маршрутизаторы, отстоящие друг от друга на одно попадание, называются соседями (neighbor). В заголовок IP можно поместить заранее определенный список попаданий (маршрутизация от источника). Однако такой способ используется крайне редко (чаще — хакерами, поэтому многие маршрутизаторы конфигурируются на отбрасывание всех датаграмм с маршрутизацией от источника). Обычно датаграммы маршрутизируются посредством выбора следующего попадания для точки назначения в каждом из маршрутизаторов по пути следования. Маршрутизация по следующему попаданию гибка и надежна. Изменения сетевой топологии обычно проводятся при изменении только в одном или нескольких маршрутизаторах, которые могут информировать друг друга о временных или постоянных изменениях в сети и динамически переключать трафик на альтернативный маршрут. 8.4 Метрики маршрутизацииДля сравнения и выбора лучшего из двух маршрутизаторов используется определенный тип метрик (удаленных изменений). 8.4.1 Протоколы вектора расстоянияСамый простой протокол для сравнения маршрутизаторов использует счет попаданий между конечными точками пути. Некоторые улучшенные варианты оценивают стоимость или вес каждого из участков по пути следования. Например, участок попадания через высокоскоростную локальную сеть имеет вес, равный 1, а участок через низкоскоростной носитель (линия "точка-точка" на 19,2 Кбайт/с) имеет вес 10. Таким образом, путь по скоростному участку предпочтительнее пересылки по низкоскоростной связи. Протокол RIP оценивает маршрут по счетчику попаданий. При вычислении метрики маршрутизации более совершенные протоколы комбинируют характеристики, подобные полосе пропускания, задержку, надежности, текущей загрузке или стоимости оплаты. Протоколы IGRP и EIGRP используют настраиваемые метрики. Алгоритмы для принятия решения при маршрутизации, основанные на значениях метрик, называются векторами расстояния (distance vector). 8.4.2 Протоколы по состоянию связиРанее большое внимание уделялось алгоритмам маршрутизации по состоянию связи (link state). Работающие по этому принципу маршрутизаторы создают карту сети и исследуют пути от себя до каждой из точек сети. Для каждой связи карты формируется метрика стоимости. Общая стоимость для каждого начинающегося от маршрутизатора пути вычисляется как сумма стоимостей каждого участка. Затем можно выбрать наилучший путь для направления трафика. При изменениях в топологии маршрутизаторы посылают сведения об обновлениях другим маршрутизаторам. После обмена пересчитываются стоимости всех путей. Протоколами по состоянию связи являются OSPF и IS-IS. Алгоритмы вычисления состояния связи часто первым именуют кратчайший путь (Shortest Path First — SPF). Это же название дается компьютерному алгоритму, вычисляющему наиболее короткие пути от одного узла до всех остальных узлов сети. 8.5 Таблицы маршрутизацииПри направлении датаграммы в удаленную точку назначения хост или маршрутизатор использует сведения из таблицы маршрутизации. Таблица отражает соответствие между каждой из точек назначения и маршрутизатором следующего попадания на пути к этой точке. Перечисленные в таблице точки назначения могут включать в себя суперсети (бесклассовый блок IP-адресов с единым префиксом), сети, подсети и отдельные системы. Точка назначения по умолчанию представляется как 0.0.0.0. Не существует стандартов на формат таблиц маршрутизации, однако наиболее простая из них должна содержать следующие элементы: ■ Адрес сети, подсети или системы назначения ■ IP-адрес используемого маршрутизатора следующего попадания ■ Сетевой интерфейс для доступа к маршрутизатору следующего попадания ■ Маску для точки назначения ■ Расстояние до точки назначения (количество попаданий) ■ Время в секундах от последнего изменения маршрута Для сокращения размера таблицы многие или все элементы идентифицируют только суперсети, сети или подсети назначения. Смысл этого в том, что, если известно, как добраться до маршрутизатора сети нужного хоста, а затем до маршрутизатора подсети, то вопрос с маршрутизацией будет решен. Иногда несколько элементов таблицы содержат полные IP-адреса отдельных систем. Для изучения работы таблиц маршрутизации рассмотрим два примера. 8.6 Таблица маршрутизации по протоколу RIPЭлементы маршрутизации таблицы 8.1 получены из университетского маршрутизатора, работающего по протоколу RIP. В таблице перечислены точки назначения и перемещающиеся по пути следования к этим точкам маршрутизаторы (на них нужно направить датаграмму при отправке ее в заданную точку назначения). Кроме того, в таблице хранятся метрики (по вектору расстояния), помогающие маршрутизатору выбрать следующее попадание. Таблица 8.1 Таблица маршрутизации RIP-маршрутизатора
* — косвенный ** — прямой *** — локальный Таблица маршрутизации содержит элементы для многих различных подсетей сети 128.36.0.0, а также маршруты к сетям 130.132.0.0, 192.31.2.0 и 192.31.235.0 (эти значения извлечены из маршрутизатора приложением HP Open View for Windows Workgroup Node Manager). Четыре столбца правой части таблицы не используются в RIP). 8.6.1 Использование маски маршрутаДля поиска совпадения с адресом назначения (например, 128.36.2.25) нужно сравнить 128.36.2.25 с каждым элементом маршрута назначения (Route Destination). Элементы маски маршрута (Route Mask) указывают, сколько бит из 128.36.2.25 должны совпадать с битами маршрута назначения. Допустим, третья строка таблицы 8.1 имеет маску маршрута 255.255.255.0, означающую, что должны совпадать первые три байта, 128.36.2 (именно так и будет). Более формально можно сказать, что нужно сравнивать маршрут назначения с результатом операции логического умножения адреса назначения и маски маршрута. Предположим, что совпадение выявлено для двух строк таблицы. Предпочтительный путь будет определять строка с более длинной маской. 8.6.2 Маршрут по умолчаниюПервой строкой в таблице 8.1 стоит маршрут по умолчанию. В ней указано, что, не найдя совпадения со строкой таблицы, трафик должен быть направлен на ближайший соседний маршрутизатор с адресом 128.36.0.2. 8.6.3 Использование подсети 0Администратор данной сети сделал то, что не разрешается стандартами. Он присвоил локальной сети, в которой расположен маршрутизатор, номер подсети 0. Мы уже знаем, что нельзя присваивать 0 в качестве номера подсети. Однако, понимая, что некоторые возможности должны быть у любого доступного номера, разработчики маршрутизаторов позволяют управлять и такими адресами. 8.6.4 Прямые и косвенные назначенияОтметим, что один элемент таблицы указывает на прямой (direct) тип локальной сети 128.36.0, что означает непосредственное подключение этой сети к маршрутизатору. Протокол является локальным (local), когда маршрут можно изучить, просмотрев конфигурационные параметры самого маршрутизатора. Оставшиеся элементы перечисляют удаленные подсети и сети, которые достигаются косвенно (indirect) при направлении трафика на другие маршрутизаторы. Такие маршруты изучаются средствами протокола RIP. 8.6.5 Метрики маршрутизацииВ таблице предусмотрено место для нескольких метрик. RIP использует только одну из них — простой счетчик количества попаданий по пути к точке назначения. Неиспользуемые значения установлены в -1. Отметим, что метрика 0 присвоена подсети 128.36.0, которая подключена непосредственно к маршрутизатору. Многие другие точки назначения доступны за одно попадание. Однако подсеть 128.36.19.0 отстоит от маршрутизатора на 14 попаданий. Мы рассматривали маршрутизатор модели Shiva Lanrover, имеющий множество телефонных номеров для подключения линий к интерфейсу 1. 8.6.6 Возраст маршрутаСтолбец возраста маршрута (Route Age) отслеживает количество секунд от последнего изменения или проверки каждого из маршрутов. Элементы таблицы, созданные через RIP, будут считаться недействительными по тайм-ауту возраста, если их невозможно реконфигурировать в течение трех минут. 8.7 Таблица маршрутизации IGRP/BGPЭлементы маршрутизации в таблице 8.2 получены из маршрутизатора провайдера Интернета. В ней перечислены назначения и идентифицированы маршрутизаторы для следующего попадания, используемые при доставке датаграмм к каждой точке назначения. Кроме того, здесь содержится информация для помощи маршрутизатору при повторном вычислении участка следующего попадания, когда произойдет изменение топологии сети. Таблица 8.2 Элементы таблицы маршрутизации IGRP и BGP
Таблица маршрутизации содержит строки для различных сетей и подсетей (информация из маршрутизатора извлечена через систему управления HP Open View). 8.7.1 Использование маски маршрутаДля поиска совпадения с назначением 128.121.54.101 нужно применить маску маршрута для каждого элемента и сравнить результат с назначением маршрута (Route Destination). Применение маски 255.255.255.0 к четвертой строке даст 128.121.54.0, что совпадает с элементом назначения. IGRP выбирает несколько строк — поскольку может существовать несколько элементов с одинаковым полем назначения и маской. В этом случае используется наилучшая из метрик. Или, если метрики совпадают, IGRP может разделить трафик на два или большее число путей. 8.7.2 Маршрут по умолчаниюПервой строкой в таблице стоит маршрут по умолчанию. Если не найдено ни одного совпадения, трафик будет передан на ближайший маршрутизатор с адресом 130.94.40.250. 8.7.3 Прямые и косвенные точки назначенияТри следующие строки имеют прямой тип для точки назначения, что означает подсети, подключенные непосредственно к этому маршрутизатору. Их протоколы локальны, и маршрутизатор может исследовать эти подсети через конфигурационную информацию, вводимую вручную. Далее идет несколько строк для удаленных (косвенных) точек назначения, положение которых было определено маршрутизатором посредством лицензированного протокола IGRP компании Cisco. 8.7.4 Малые подсетиНабор точек назначения начинается со строки таблицы, содержащей 130.94.1.24, которая выглядит как адрес хоста. Однако маска маршрута указывает, что все эти элементы являются небольшими подсетями. Они имеют часть адреса для хостов, состоящую только из трех последних бит. Например, двоичное представление 24 — 00011000, и все биты для представления этого числа реально принадлежат части адреса для подсети. Хосты такой подсети будут располагаться в диапазоне адресов от 130.94.1.25 до 130.94.1.30. 8.7.5 Строки для протокола Border Gateway ProtocolТаблица завершается списком удаленных назначений, которые были исследованы с помощью протокола Border Gateway Protocol, обеспечившего информацию для маршрутизации между автономными системами и Интернетом. 8.7.6 Метрики маршрутизацииВо второй части таблицы 8.2 видно, что метрика 0 присвоена тем точкам назначения, доступ к которым можно получить в трех непосредственно связанных с маршрутизатором сетях. Как и раньше, значения неиспользуемых метрик равны -1. Всем пяти метрикам значения присвоены при помощи протокола IGRP компании Cisco. Однако не было попыток обеспечить осмысленные значения для метрик точек назначения Интернета в удаленных автономных системах, которые исследовались через протокол BGP. Все интерфейсы маршрутизатора пронумерованы, и датаграммы пересылаются через интерфейс, указанный в столбце Индекс ЕСЛИ. 8.7.7 Возраст маршрутаДля протокола IGRP столбец возраста маршрута (Route Age) означает количество секунд, прошедших со времени последнего изменения или проверки маршрута. Строки таблицы маршрутизации, получаемые через этот протокол, должны время от времени реконфигурироваться. Для протокола BGP возраст маршрута отражает стабильность маршрутов в удаленные точки сети. 8.8 Протоколы обслуживания таблиц маршрутизацииКаким образом маршрутизаторы получают информацию для строк своих таблиц? Как поддерживать корректность строк таблицы маршрутизации? Каким будет лучший способ для выбора маршрутизатора следующего попадания? Все эти вопросы решает протокол маршрутизации, простейший из которых должен: ■ Анализировать сетевые датаграммы для определения наилучшего пути. Выбирать следующее попадание для каждого из маршрутов. ■ Обеспечивать ручной ввод данных в таблицу маршрутизации. ■ Обеспечивать ручное изменение строк таблицы маршрутизации. Именно такие операции и выполняет простой маршрутизатор для подразделения компании (см. рис. 8.2). Он может иметь в таблице только две строки — для локальной сети 192.101.64.0 и маршрут по умолчанию для облака (облаками на рисунках принято обозначать сетевые связи через несколько маршрутизаторов. — Прим. пер.). 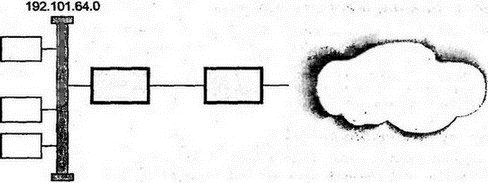 Рис. 8.2. Маршрутизация в подразделении компании Ручной ввод строк таблицы маршрутизации допустим в небольших сетях, но в сложных, расширяющихся и изменяющихся сетях, имеющих потенциально несколько маршрутов к точке назначения, маршрутизация вручную становится невозможной. На некотором уровне сложности человек не сможет проанализировать и описать все сетевые условия. Поэтому протокол маршрутизации должен автоматизировать: ■ Обмен информацией между маршрутизаторами о текущем состоянии сети ■ Повторное вычисление для выбора наилучшего маршрута при каждом изменении в сети Долгие годы проводились серьезные исследования протоколов маршрутизации. Многие из них были реализованы, а используемые в них метрики породили жаркие дебаты. Приведем характеристики наилучшего протокола: ■ Быстрая реакция на изменение в сети ■ Вычисление наилучшего маршрута ■ Хорошая масштабируемость при расширении сети ■ Бережное использование компьютерных ресурсов ■ Бережное использование сетевых ресурсов Однако вычисление наилучшего маршрута в большой сети требует определенных ресурсов центрального процессора и памяти, а быстрая реакция предполагает немедленную пересылку большого объема информации. В хорошем протоколе достигается компромисс между исключающими друг друга требованиями. Изучение протоколов маршрутизации начинается с наиболее простого из них — RIP. 8.9 Протокол RIPНаиболее широко используемым протоколом IGP является RIP, заимствованный из протокола маршрутизации сетевой системы компании Xerox (Xerox Network System — XNS). Популярность RIP основана на его простоте и доступности. RIP был первоначально реализован в TCP/IP операционной системы BSD и продолжает распространяться в операционных системах Unix как программа routed. Программа routed стала стандартной частью многих хостов различных разработчиков и пакетов маршрутизации TCP/IP. RIP включен и в бесплатное программное обеспечение Корнельского университета, названное gated. RIP получил широкое распространение еще за несколько лет до его стандартизации в документе RFC 1058. Вторая версия протокола была предложена в 1993 г. и улучшена в 1994 г. (после этого исходная версия получила маркировку "историческая", т.е. устаревшая). RIP анализирует маршрут на основе простого вектора расстояния. Каждому попаданию присваивается вес (обычно 1). Общая метрика пути получается как сумма весов всех участков попадания. Выбор лучшего пути для следующего попадания производится по наименьшему значению метрики. На рис. 8.3 показано распространение в сети процедуры оценки по вектору расстояния. Маршрутизатор из верхнего левого угла рисунка может определить, что датаграмма, направляемая через маршрутизатор А в сеть N, имеет меньше попаданий, чем направляемая в эту сеть через маршрутизатор B.  Рис. 8.3. Исследование количества попаданий до точки назначения Для RIP наиболее важны простота и доступность. Часто нет особых причин использовать более совершенные (и более сложные) методы маршрутизации для малых сетей или сетей с простой топологией. Однако при применении в больших и сложных сетях у RIP проявляются серьезные недостатки. Например: ■ Максимальное значение метрики для любого пути равно 15. Шестнадцать означает "Точки назначения достичь нельзя!". Поскольку в больших сетях можно быстро получить переполнение счетчика попаданий, обычно RIP конфигурируется со значением веса 1 для каждого из участков попадания независимо от того, является этот участок низкоскоростной коммутируемой линией или высокоскоростной волоконно-оптической связью. (Ограничение счетчика позволяет исключить зацикливание датаграмм по круговому маршруту. Другого метода для этого в RIP не существует. — Прим. пер.) ■ После нарушений в работе сети RIP очень медленно восстанавливает оптимальные маршруты. Реально после нарушения в сети трафик может даже зациклиться по круговому маршруту. ■ RIP не реагирует на изменения в задержках или нагрузках линий связи. Он не может распараллеливать трафик для обеспечения баланса нагрузки на связи. 8.9.1 Инициализация RIPПри запуске каждый маршрутизатор должен знать только о сети, к которой он подключен. Маршрутизатор RIP отправляет эти сведения широковещательной рассылкой на все соседние с ним в локальной сети маршрутизаторы. Кроме того, эти же сведения посылаются соседям на других концах линий "точка-точка" и виртуальных цепей. Как показано на рис. 8.4, новости распространяются как сплетни — каждый маршрутизатор пересылает их своему ближайшему соседу. Например, маршрутизатор С очень быстро узнает, что он на расстоянии в два попадания от подсети 130.34.2.0. 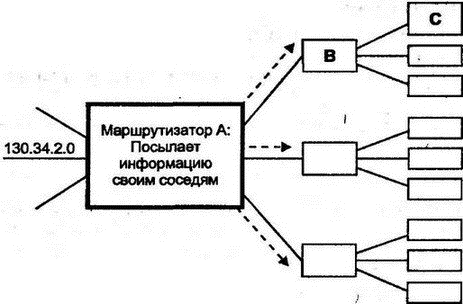 Рис. 8.4. Распространение информации о маршрутизации Как и все автоматизированные протоколы маршрутизации, RIP посылает информацию об изменениях маршрутов, получает такие сведения от других и пересчитывает пути. Маршрутизатор RIP отсылает информацию своим соседям-маршрутизаторам каждые 30 с. Отправка этих данных называется объявлением о маршруте (advertising route). Хосты локальной сети могут подслушать объявления в широковещательных рассылках RIP и использовать их для обновления собственных таблиц или, по крайней мере, узнать, что маршрутизатор продолжает работать. 8.9.2 Обновление таблиц RIPКак видно на рис. 8.5, маршрутизатор А пересылает трафик в сеть 136.10.0.0 через маршрутизатор B. А получил изменения от своего соседа D, который объявил о более коротком маршруте, и А изменил свою таблицу маршрутизации. Отметим, что количество попаданий от А до В добавляется к метрике от D для вычисления расстояния (2) от А до 136.10.0.0. 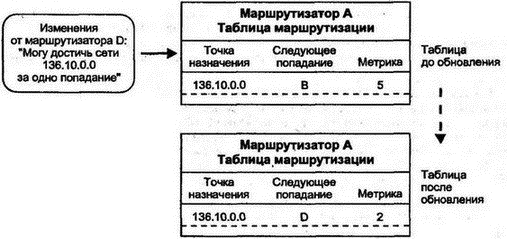 Рис. 8.5. Обновление таблиц маршрутизации в RIP 8.9.3 Механизм RIP версии 1Рассмотрим формальные этапы маршрутизации в RIP версии 1. Предположим, что в таблице маршрутизации уже есть сведения о нескольких расстояниях. Затем, когда от соседа прибывает информация об изменениях, маршрутизатор перепроверяет свою таблицу и анализирует строки на предмет добавления или улучшения: 1. Присваивается вес для каждой подключенной и пересекаемой при пересылке датаграмм подсети (обычно 1). 2. Маршрутизатор посылает свою таблицу соседям каждые 30 с. 3. Когда маршрутизатор получает таблицу от соседа, он проверяет каждую строку этой таблицы. Присвоенный подсетям вес (в поступивших изменениях) добавляется к каждой из метрик. 4. К локальной таблице маршрутизации добавляются новые точки назначения. 5. Если точка назначения уже присутствует в таблице, но в изменениях указан более короткий путь, то заменяется соответствующая строка локальной таблицы. Прекрасно, когда маршруты постоянно улучшаются, но иногда, вследствие неисправности связи или маршрутизатора, нужно будет пересылать трафик по более длинному пути. Реакция на неисправности предполагает два пути: 1. Маршрутизатор А пересылал трафик в точку назначения через маршрутизатор X, а X прислал изменения, указывающие на увеличение количества попаданий до точки назначения (или на невозможность достижения точки назначения по данному пути). Маршрутизатор А соответствующим образом изменит строку своей таблицы. 2. Маршрутизатор А пересылал трафик в точку назначения через маршрутизатор X, но не получил изменений от X в течение трех минут. А предполагает неисправность X и маркирует все пути через X как недостижимые (указав для метрики значение 16). Если за 2 мин для таких точек назначения не будет обнаружен новый маршрут, соответствующие строки удаляются (такой процесс образно называют "сборкой мусора" — garbage collection). В то же время маршрутизатор А указывает своим соседям через посылаемые изменения, что маршрутизатор X не может обеспечить путь к точкам назначения. 8.9.4 Сообщения об изменениях в RIP версии 1Как было сказано выше, между маршрутизаторами RIP периодически формируются сообщения об изменениях. Дополнительно можно послать к соседям сообщения с запросами информации о маршрутизации: ■ Во время инициализации ■ При выполнении операций сетевого мониторинга Формат сообщений RIP версии 1 для запросов или ответов/изменений показан на рис. 8.6. Поле команд со значением 1 указывает на запрос, а идентификатор 2 определяет ответ или самопроизвольное сообщение об изменениях. 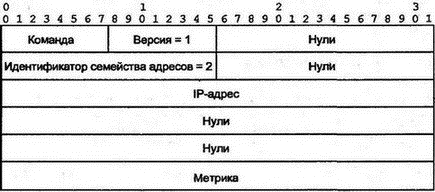 Рис. 8.6. Формат сообщений в RIP версии 1 8.9.5 Поля сообщения об изменениях в RIP версии 1Когда создавалась исходная спецификация RFC для RIP, предполагалось, что сообщения о маршрутизации будут использоваться и другими протоколами, а не только IP. Поэтому в сообщении появилось поле идентификатора семейства адресов (address family identifier) и место для адреса в 14 октетов. Семейство адресов, IP-адрес и поле метрики могут повторяться, поэтому сообщение может содержать до 25 адресных элементов. Максимальная длина сообщения составляет 512 октетов. Если нужно переслать сведения о более чем 25 элементах, используется несколько сообщений. В сообщении об изменениях присутствуют все точки назначения и метрики из таблицы маршрутизации отправителя. В запросе указывают элементы для каждого из адресов, метрику которого нужно получить. Элемент с адресом 0 и метрикой 16 запрашивает полное изменение таблицы маршрутизации. Регулярные изменения RIP пересылаются через протокол UDP из порта источника 520 в порт 520 маршрутизатора назначения. Однако запросы могут посылаться из любого порта, на который и придет ответ на запрос. 8.9.6 Настройка RIPВыше мы рассмотрели базовые механизмы протокола RIP. Однако реализации этого протокола имеют некоторые дополнительные возможности для решения следующих проблем: ■ При интервале между изменениями, равном 30 с, требуется много времени на распространение изменений по большой сети ■ После изменения, особенно при потере соединения, имеется тенденция к зацикливанию трафика по кольцу Далее рассматриваются пути решения этих проблем. 8.9.7 Триггерные изменения и хранениеТриггерные изменения (triggered updates) ускоряют процесс исследования изменений. Маршрутизатор, изменив метрику пути, посылает объявление о таком изменении. Отметим, что новое изменение приводит к переключению следующего изменения, и процесс продолжается далее (это напоминает работу триггера). Такой кратковременный поток сообщений позволит множеству пользователей не применять заведомо неисправные пути. Поскольку формируются причины для одновременной пересылки большого числа изменений, каждая из систем будет ожидать произвольный период времени, прежде чем начать дальнейшую пересылку. Кроме того, полоса пропускания для трансляции таких изменений может быть сокращена за счет пересылки только реально изменившихся строк, а не всей таблицы маршрутизации. В процессе распространения согласований таблиц маршрутизатор может обнаружить восстановление неисправности и послать сообщение об отмене изменений, поскольку плохой маршрутизатор снова стал хорошим. В таком случае никто не должен менять в своих таблицах хорошую информацию на плохую и вносить изменения, чтобы не распространять далее неверные сведения. По этой причине многие разработчики реализуют в своих устройствах операцию хранения (hold down), когда в течение определенного периода времени игнорируются точки назначения, маркированные как недостижимые. 8.9.8 Деление горизонта и опасный реверсПочему иногда происходит зацикливание трафика в RIP? Причина в том, что после изменения проходит некоторое время, пока все маршрутизаторы не обновят информацию. На рис. 8.7 показан простой пример (он взят из RFC 1058). Маршрутизатор D имеет два пути к сети N. Один из них короткий (в одно попадание), а другой — длинный (в 10 попаданий). Если оборвется связь по короткому пути, маршрутизатор D заменит его на альтернативный (длинный) путь с метрикой 10. 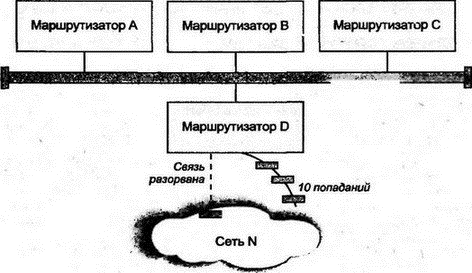 Рис. 8.7. Маршрутизация после неисправности в сети Однако в сообщениях RIP об изменении; посланных маршрутизаторам А, В и С, будут только следующие сведения: Сеть N Метрика = 2 Нет никакого способа указать в сообщении, что путь проходит через маршрутизатор D. Что же произойдет, когда маршрутизатор D получит изменения от А до того, как укажет А на собственные изменения? ■ D изменит строку своей таблицы на:
■ D попытается переслать трафик к сети N через А (последний отправит трафик обратно). ■ D отправит объявления об изменении своей таблицы на А, В и С (что он может достичь сети N за три попадания). ■ Маршрутизаторы ответят, что они теперь смогут попасть в сеть N за четыре попадания. Маршрутизаторы В и С столкнутся с неоднозначностью и, в зависимости от времени поступления изменений, могут пытаться отправлять свои трафики к сети N друг через друга, через А или D. ■ Изменения RIP будут распространяться дальше и глубже. Хорошо то, что метрики для сети N в А, В и С будут постоянно увеличиваться с приходом каждого нового изменения, пока не достигнут значения 11 и не будет определен правильный маршрут. Два простых механизма позволяют избежать путаницы в сети, которая может возникнуть во время устранения неисправности. Деление горизонта (split horizon) требует, чтобы маршрутизаторы не посылали своих объявлений о пути к системам со следующим попаданием по этому пути. В примере на рис. 8.7 маршрутизаторы А, В и С не будут указывать D, что могут достичь сети N, поскольку путь к N проходит через сам маршрутизатор D. Опасный реверс (poisoned reverse) идет еще дальше. По этому алгоритму маршрутизаторы А, В и С (см. рис. 8.7) предотвращают распространение неверных сведений с помощью специального сообщения, означающего "Не пытайтесь передавать через меня!". Более точно — изменения будут включать элемент: Сеть N Метрика = 16 Это исключает проблемы в небольших сетях, но для сетей с большим диаметром колец зацикливания они остаются, даже когда реально нельзя достичь точки назначения. Метрики все равно когда-нибудь увеличатся до 16, и будет восстановлен правильный маршрут. Этот процесс называется подсчетом до бесконечности (counting to infinity). Способы, идентичные рассмотренным выше алгоритмам, можно обнаружить в любом из маршрутизаторов RIP. Однако существует десяток версий RIP, написанных для слишком простых устройств (возможно, для кухонных тостеров). Если нет достоверных данных о способе работы конкретной модели маршрутизатора, его лучше переместить в небольшую сеть и конфигурировать вручную. Несколько очевидных недостатков сообщений протокола RIP версии 1 мы рассмотрим в следующих разделах. 8.9.9 Нет маски подсетиВ сообщения прокола RIP версии 1 не включаются маски (см. рис. 8.6), следовательно, нельзя определить, что представляет собой адрес: подсеть или хост. Долгое время разработчики маршрутизаторов решали эту проблему, требуя, чтобы пользователи выбирали одну маску подсети для всей сети. Подключенный к сети маршрутизатор определял эту маску с помощью анализа конфигурации интерфейсов сети. Маршрутизаторы, не подключенные непосредственно к сети, не имели возможности определить маску подсети. Сведения о подсети удаленной сети были для них бесполезны. По этой причине маршрутизаторы RIP версии 1 не посылали сведений о подсетях и хостах на маршрутизаторы, которые не были подключены непосредственно к сети, содержащей эти подсети и хосты. Внешний маршрутизатор посылал единственный элемент для всей сети (например, 145.102.0.0). Данный способ мог привести как к избытку строк в таблице маршрутизации, так и к их недостатку. Если в сети использовалась адресация CIDR, следовало обеспечить отдельные строки для каждого из адресов класса С такой связки. В то время как один элемент с маской подсети мог бы представлять всю сеть CIDR. 8.9.10 Широковещательные рассылки в локальной сетиВерсия 1 выполняет широковещательные рассылки в локальной сети. Следовательно, каждый из сетевых интерфейсов должен принимать и анализировать такие сообщения. Больший смысл имеет использование многоадресных рассылок. 8.9.11 Отсутствие аутентификацииЕще одним неприятным свойством версии 1 является отсутствие аутентификации для сообщений RIP. Если некто получил доступ к сети и сформировал сообщение с заведомо ложной информацией (фальсифицировав адрес источника), то это может сделать недоступным большинство точек назначения и привести к серьезному нарушению работы сети. 8.9.12 Отсутствие распознавания медленных и быстрых связейСетевой администратор может вручную присвоить для связи значение счетчика попаданий. Следовательно, для связи "точка-точка" со скоростью 9,6 Кбайт/с можно установить значение счетчика 5, что укажет на ее меньшие возможности по сравнению со связью 10 Мбайт/с. К сожалению, когда счетчик достигнет значения 15, точка назначения станет недоступной, а значит, администратору лучше использовать для всех связей одно и то же значение веса, равное 1. Небольшое максимальное значение счетчика имеет одно преимущество. Вспомним, что недоступная точка назначения иногда приводит к временному зацикливанию пути. Метрики из сообщений об изменениях быстро доведут значение счетчика до 16, и такое кольцо зацикливания будет удалено. Больший предел счетчика привел бы к увеличению времени на уничтожение колец зацикливания. 8.9.13 Избыточный трафикВ больших сетях размер таблиц маршрутизации быстро увеличивается. Пересылка всего содержимого таблицы приведет к существенной дополнительной нагрузке на сеть. Кроме того, замедляется работа маршрутизаторов, которым требуется постоянно анализировать десятки и сотни строк из сообщений об изменениях, большинство из которых вовсе не нужно обновлять. Небольшой по времени период обновления таблиц приводит к проблемам коммутации на дальние расстояния. Коммутируемые линии или цепи X.25 могут использоваться случайно, создавая отдельные всплески сетевого трафика. Для экономии такие линии и цепи часто закрывают после завершения пересылки данных. По возможности используется ручная конфигурация для связей с удаленными сетями. Новые протоколы маршрутизации решают такие проблемы с помощью посылки изменений только после их внесения и включают в сообщение только сведения о реально измененных путях. Периодически маршрутизаторы обмениваются сообщениями Hello! (Привет!), позволяющими выяснить работоспособность друг друга, за исключением коммутируемых связей, для которых всегда предполагается нормальное состояние у соседа, пока попытка реальной пересылки данных не завершится неудачей. 8.10 Протокол RIP версии 2Хотя стандарт RFC 1058, в котором была определена версия 1, был опубликован еще в 1983 г., версия 2 протокола RIP появилась только в 1993 г. К этому времени была проведена большая работа по созданию более сложного протокола, способного решить проблемы старой версии. Однако многим организациям нравится простота в инсталляции и использовании RIP старой версии. Версия 1 была декларирована "исторической", и пользователям нужно было перейти на версию 2. RIP версии 2 предлагает простые решения большинства проблем первой версии. Однако для совместимости с версией 1 изменения были ограничены. Максимальное значение счетчика попаданий осталось равным 15, а все содержимое таблицы маршрутизации по-прежнему обновляется каждые 30 с. Но для передачи изменений стали использоваться многоадресные, а не широковещательные рассылки. Большинство доработок в версии 2 связано с размещением дополнительной информации в сообщении об изменениях. Формат сообщения версии 2 показан на рис. 8.8. 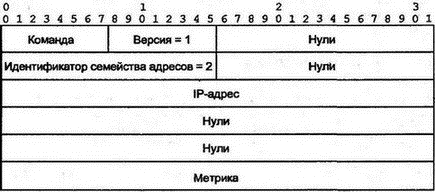 Рис. 8.8. Формат сообщения RIP версии 2
 Рис. 8.9. Использование поля "Следующее попадание" в отчете маршрутизатора 8.10.1 Аутентификация в RIP версии 2Как один из вариантов, место для первого изменения может быть использовано для аутентификации. Оно указывается как поле аутентификации при значении X'FFFF в поле идентификатора семейства адресов. Используемый тип аутентификации описывается в следующем поле. Оставшиеся 16 бит содержат саму информацию об аутентификации. Хотя для версии 2 определен только один тип аутентификации (с идентификатором 2), использующий простой пароль, разработчики маршрутизаторов понемногу переходят на аутентификацию MD5. На рис. 8.10 показан формат сообщения с аутентификационной информацией. 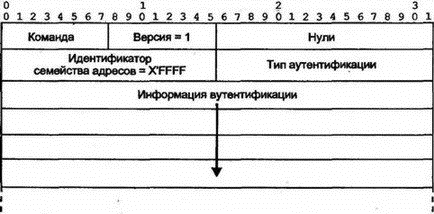 Рис. 8.10. Сообщение версии 2 RIP, начинающееся с аутентификации 8.11 Переход на более интеллектуальные протоколыДля перехода на более интеллектуальные протоколы были сделаны два улучшения. Как и RIP, лицензированный протокол IGRP компании Cisco использует вектор расстояния, однако в нем устранены недостатки RIP. OSPF и IS-IS являются протоколами по состоянию связи. В них создаются карты сети и исследуются все маршруты к точке назначения, а затем полученные метрики путей сравниваются друг с другом. В этих протоколах поддерживаются дополнительные возможности, например способность разделять трафик по нескольким эквивалентным путям. Кроме того, произошел переход на поддержку маршрутизации на основе типов обслуживания (TOS). Например, один из низкоскоростных маршрутов можно зарезервировать для интерактивного трафика, а путь с большей производительностью (но не слишком малой задержкой) использовать для пересылки больших массивов данных. 8.12 Протоколы IGRP и EIGRPХотя IGRP основан на векторе расстояния, его метрики вычисляются по формуле, учитывающей множество факторов, включая полосу пропускания и задержку сети. Дополнительно IGRP учитывает текущий уровень загрузки каждой связи, а также уровень ошибок при пересылке данных из одного конца в другой. IGRP может разделять трафик по эквивалентным или почти эквивалентным путям. Когда существует несколько путей к точке назначения, большая часть трафика пересылается по пути с большей полосой пропускания. Граничный маршрутизатор провайдера, использующий протокол IGRP, может собирать сведения от нескольких внешних автономных систем. Следовательно, в этом протоколе поддерживается маршрутизация между различными автономными системами. EIGRP использует те же метрики и формулы маршрутизации, что и IGRP, но имеет несколько важных улучшений: существенно снижает дополнительный трафик, пересылая сообщения об изменениях только после их внесения в свою таблицу и передает при этом только сведения о реальных изменениях. В EIGRP реализован алгоритм исключения колец зацикливания. В следующих разделах мы рассмотрим возможности IGRP и улучшения, вносимые EIGRP. 8.12.1 Маршрутизация в IGRPКак и в RIP, маршрутизатор IGRP периодически распространяет среди соседей содержимое своей таблицы через широковещательные рассылки. Однако в отличие от RIP маршрутизатор IGRP начинает работу с уже сформированной таблицей маршрутизации для подключенных к нему подсетей. Эта таблица расширяется далее благодаря сведениям от ближайших соседей-маршрутизаторов. В сообщениях об изменениях протокола IGRP не содержится сведений о маске подсети. Вместо простого счетчика попаданий RIP применяются различные типы информации о метриках, а именно:
Значения для задержки, полосы пропускания и MTU берутся из конфигурационной информации маршрутизатора, а значения для нагрузки и надежности вычисляются динамически на основе информации, которой обмениваются маршрутизаторы. В таблице 8.3 дано несколько примеров для кодов задержки и полосы пропускания. В таблице 8.2 приведены метрики, возвращаемые протоколом Simple Network Management Protocol (SNMP) из пула маршрутизаторов Cisco. Например:
Для IGRP/EIGRP значения метрик имеют следующий смысл: Метрика 1 Обобщенная метрика маршрута Метрика 2 Метрика полосы пропускания Метрика 3 Сумма задержек интерфейса Метрика 4 Счетчик попаданий маршрута Метрика 5 Надежность интерфейса (255 означает 100%) Таблица 8.3 Измерение задержки и полосы пропускания в IGRP
8.12.2 Другие конфигурируемые значения IGRPКонфигурировать маршрутизаторы IGRP несложно. Кроме IP-адреса, маски подсети, MTU, полосы пропускания и задержки связи, можно специфицировать: ■ Фактор изменения (variance factor) V. Если M является наименьшей метрикой пути, используется путь с метрикой М×V. ■ Разрешить или запретить хранение (hold down). ■ Можно конфигурировать и таймеры, хотя чаще используют следующие значения по умолчанию: ■ Широковещательная рассылка изменений каждые 90 с. ■ Если в течение 270 с не приходит сообщение об изменениях от соседнего маршрутизатора, то соответствующие элементы удаляются по тайм-ауту. Если нет альтернативных маршрутов, точка назначения маркируется как недостижимая. ■ Выполняется хранение, во время которого не учитываются новые пути к недостижимой точке назначения (в течение не менее 280 с). ■ Если в течение 540 с (время существования потока обновления — flush time), не приходит сведений об изменениях точки назначения, то удаляется соответствующая строка. 8.12.3 Механизм протокола IGRPКак и в RIP, маршрутизатор IGRP периодически посылает своим соседям сведения об изменениях. К ним относится полное содержимое текущей таблицы маршрутизации со всеми метриками. Промежуток хранения предотвращает воссоздание разорванного маршрута по сведениям из устаревших сообщений. Ни один новый маршрут к точке назначения не учитывается, пока не завершится период его хранения (хотя можно отключить этот механизм). Метод расширения горизонтов служит для предотвращения объявления о пути тем маршрутизатором, который расположен ниже по цепочке следования на таком маршруте. Кроме того, IGRP предоставляет собственную версию метода опасного реверса. Если метрика маршрута увеличивается более чем в 1,1 раза, вероятно, будет сформировано зацикливание, и такой маршрут игнорируется. Триггерные изменения пересылаются только после внесения этих изменений в собственную таблицу маршрутизации (например, при удалении маршрута). Маршрут удаляется в следующих случаях: ■ По тайм-ауту коммуникации с ближайшим соседом — удаляется маршрут к этому соседу ■ Маршрутизатор следующего попадания указывает на недоступность маршрута ■ Метрика увеличивается настолько существенно, что возможно возникновение опасного реверса 8.12.4 Внешняя маршрутизацияПричина популярности IGRP среди провайдеров заключается в возможности управления маршрутизацией между автономными системами. Распространяемые в IGRP изменения включают в себя несколько путей к внешним сетям, из которых можно выбрать один путь для использования по умолчанию. 8.12.5 Возможности EIGRPУлучшения в EIGRP основаны на тех же метриках и вычислении расстояния, что и обычные свойства этого протокола. Однако расширение свойств существенно улучшает возможности EIGRP за счет поддержки маски подсети и исключения периодических изменений. Пересылаются только реальные изменения, a EIGRP обеспечивает проверку их получения путем анализа обратного сообщения о подтверждении приема. Простые периодические сообщения Hello! (Привет!) позволяют узнать об активности своих ближайших соседей. Еще одним важным усовершенствованием стало применение диффузионного алгоритма для изменений (Diffusing Update Algorithm — DUAL), гарантирующего маршрутизацию без зацикливания. 8.12.6 DUAL в EIGRPОсновная идея DUAL проста и основана на следующем наблюдении: Если путь постоянно приближает к точке назначения, то он не может сформировать зацикливание. С другой стороны, если путь зациклен (т.е. образует кольцо), он будет содержать маршрутизатор, расстояние которого до точки назначения больше, чем у предшествующего маршрутизатора (см. рис. 8.11). 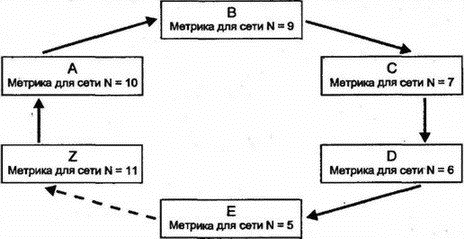 Рис. 8.11. Маршрут с формированием зацикливания Метод DUAL разработан для поиска таких путей, на которых каждый маршрутизатор при движении к точке назначения стоит ближе каждого своего предшественника. Маршрутизатор E на рис. 8.11 порождает серьезные подозрения, поскольку сведения от ближайшего маршрутизатора, следующего по пути движения (Z), в сообщениях будут иметь большую метрику, чем в собственной таблице E. 8.12.7 Таблицы топологии в DUALДля реализации DUAL протокол EIGRP сохраняет информацию, которой не пользуется IGRP. EIGRP хранит информацию о маршрутах для каждого соседнего маршрутизатора, извлекая ее из сообщений об изменениях от этих маршрутизаторов (IGRP игнорирует любую информацию о неоптимальных маршрутах). Эта информация хранится в дополнительной таблице топологии (topology table), содержащей следующие сведения:
8.12.8 Пригодный преемник в DUALНаиболее интересными в таблице топологии являются сведения о пригодном преемнике (feasible successor), которым для маршрутизатора является его ближайший сосед, находящийся в текущий момент ближе к точке назначения, чем он сам. Когда существует, по крайней мере, один пригодный преемник, то можно достичь точки назначения, и для данного пути текущим является пассивное (passive) состояние DUAL. Однако когда поступившие изменения меняют картину и пригодный преемник теряется, маршрутизатор начинает опрос ближайших соседей, чтобы определить, нельзя ли переключиться на более длинный маршрут и не будет ли при этом сформировано зацикливание. Рассмотрим этот процесс с более формальной точки зрения: 1. Предположим, что я могу достичь точки, где будет только один пригодный преемник на пути к точке назначения, через маршрутизатор Z. 2. Поступившие от Z изменения увеличат метрику Z. Более того, новое расстояние от Z до точки назначения больше, чем текущее расстояние. Это верный признак формирования зацикливания. 3. Я перехожу в активное (active) состояние и начинаю процесс пересчета маршрута (route recomputation). 4. Во время пересчета я продолжаю маршрутизировать данные через Z. 5. Я посылаю сообщение об изменениях (называемое query — запрос) всем ближайшим соседям, за исключением Z. В сообщении объявляется о моей новой, большей метрике расстояния до точки назначения. 6. Если сосед имеет один или более пригодных маршрутов, он посылает ответ и объявляет собственный верный путь к точке назначения. 7. Сосед, не имеющий пригодного пути, переходит в активное состояние (если только он уже не находится в нем) и посылает запросы своим соседям (может немедленно сообщить о том, что он в активном состоянии и выполняет пересчет). 8. Запросы распространяются в сети, пока не будут найдены все пригодные маршруты или запрос не дойдет до маршрутизатора, который точно знает, что данная точка назначения недостижима. 9. Когда маршрутизатор определяет для себя пригодный путь или недоступность точки назначения, он отсылает обратно ответ на полученный им запрос. 10. Когда придут ответы на все собственные запросы (не вторичные от других маршрутизаторов. — Прим. пер.), маршрутизатор переходит в пассивное состояние. EIGRP показал, что вектор расстояния еще долго может использоваться при маршрутизации в сетях. В следующих разделах мы рассмотрим альтернативный способ — метод по состоянию связи. 8.13 Протокол OSPFВ 1988 г. комитет IETF начал работу над стандартом нового протокола для замены RIP. В результате была создана спецификация одного из протоколов IGP, призванная сначала открывать самый короткий путь (Open Shortest Path First — OSPF). OSPF был разработан как протокол маршрутизации для использования внутри всех автономных систем любых сайтов. В 1990 г. OSPF был рекомендован в качестве стандарта. Это нелицензированный протокол для общедоступного использования. Вспомним, что протоколы по состоянию связи исследуют пути посредством построения карты сети для формирования дерева пути, корнем которого является маршрутизатор. Метрики вычисляются для каждого пути, а затем оптимальный путь (пути) определяется для каждого типа обслуживания IP (Type Of Service — TOS). В OSPF используется как метод вектора расстояния, так и состояние связи. Этот протокол разрабатывался для обеспечения хорошей масштабируемости и быстрого распространения по сети сведений о точных маршрутах. Кроме того, в OSPF поддерживается: ■ Быстрое определение изменений в топологии и очень эффективное восстановление маршрутов без зацикливания ■ Небольшая нагрузка, что связано с распространением в сети только сведений об изменениях, а не обо всех маршрутах ■ Разделение трафика между несколькими эквивалентными путями ■ Маршрутизация на основе типа обслуживания ■ Использование в локальных сетях многоадресных рассылок ■ Маски для подсетей и суперсетей ■ Аутентификация В апреле 1990 г., когда очень большая сеть NASA Science (Космического агентства США — Прим. пер.) была переведена на протокол OSPF, обнаружилось существенное снижение трафика в этой сети. После изменения или нарушения в работе сети глобальная корректировка информации о маршрутизации стала выполняться необычайно быстро — в пределах нескольких секунд (по сравнению с минутами для некоторых старых протоколов). В середине 1991 г. была опубликована вторая версия OSPF, а в марте 1994 г. появилась доработанная вторая версия. Последний вариант описывается в 216-страничном документе, поэтому приведенные ниже сведения можно рассматривать только как общее описание этого протокола. 8.13.1 Автономные системы, области и сетиВ стандарте OSPF термин "сеть" (network) означает сеть IP, подсеть или суперсеть CIDR. Точно так же маска сети (network mask) определяет сеть, подсеть или суперсеть CIDR. Область (area) рассматривается как набор непрерывных сетей или хостов вместе со всеми маршрутизаторами, имеющими интерфейсы в этих сетях. Автономная система, использующая OSPF, создается из одной или нескольких областей. Каждой области присвоен номер. Область 0 представляет собой магистраль (backbone), которая соединяет все другие области и объединяет вместе автономные системы. Рассматриваемую топологию иллюстрирует рис. 8.12. 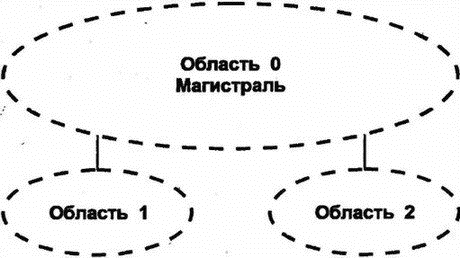 Рис. 8.12. Области и магистрали OSPF 8.13.2 Маршрутизация в области OSPFМаршрутизация внутри области основана на подробной карте состояний связи в этой области. OSPF хорошо масштабируется, поскольку маршрутизатору нужно подробно знать топологию и метрики только об области, которой он принадлежит. Каждый маршрутизатор OSPF в заданной области хранит идентичную базу данных маршрутизации (routing database), описывающую топологию и статус всех элементов этой области. База данных используется для создания карты области и содержит сведения о состоянии каждого маршрутизатора, каждого используемого интерфейса маршрутизатора, подключенной к нему сети и смежных с ним маршрутизаторах. Как только происходит изменение (например, обрыв связи), информация об этом распространяется по всей сети. Именно этим обеспечивается точность маршрутизации и быстрая реакция на неисправность. Например, если для показанной на рис. 8.13 структуры используется OSPF, то маршрутизатор A будет быстро информирован об обрыве связи с маршрутизатором В и узнает о невозможности доступа к сети N. 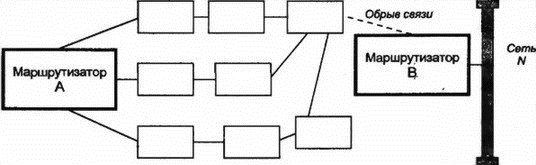 Рис. 8.13. Использование полной информации о маршрутизации Маршрутизатор инициирует получение копии текущего состояния базы данных от смежного с ним соседа. После этого происходит обмен только изменениями, которые быстро становятся известными в OSPF, поскольку для распространения информации об изменениях по всей области используется потоковый алгоритм. 8.13.3 Кратчайшие пути для области OSPFМаршрутизатор использует базу данных области для создания дерева кратчайших путей, рассматривая себя как корень этого дерева. На основе дерева формируется таблица маршрутизации. Если в области поддерживается тип обслуживания (TOS), то для значений каждого из типов обслуживания формируются отдельное дерево и набор маршрутов. 8.13.4 Магистрали, грани и границы OSPFОбласти объединяются магистралями. Магистраль содержит все маршрутизаторы, принадлежащие разным областям, а также любые сети и маршрутизаторы, не включенные в другие области. Области нумерованы, а магистраль имеет номер 0. Маршрутизатор грани (border) принадлежит одной или нескольким областям и магистрали. Если автономная система соединена с внешним миром, то маршрутизатор границы (boundary) содержит сведения о маршрутизаторах сети, являющейся внешней для автономной системы. На рис. 8.14 магистраль (область 0) включает маршрутизаторы А, В, С, F и G. К области 1 относятся маршрутизаторы В и D. Область 2 содержит маршрутизаторы С, E и F. Маршрутизаторы В, С и F являются маршрутизаторами грани, a G — маршрутизатором границы. Маршрутизатор В знает все о топологии области 1 и магистрали. Аналогично маршрутизаторы С и F имеют сведения об области 2 и магистрали. 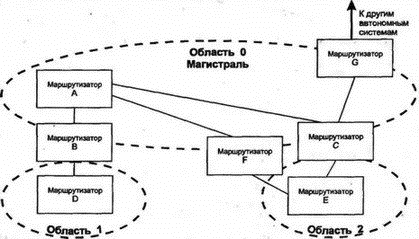 Рис. 8.14. Маршрутизаторы и области в автономных системах Магистраль должна быть непрерывной. Что произойдет при разрыве магистрали из-за расформирования сети или неисправности оборудования? Иногда для объединения отдельных элементов в магистраль используют виртуальные связи. Виртуальную связь (virtual link) можно установить между двумя маршрутизаторами магистрали, имеющими интерфейсы в одной и той же области. Виртуальная связь трактуется как нечисловая связь "точка-точка". Мера стоимости виртуальной связи определяется общей стоимостью пути между двумя маршрутизаторами. Как показано на рис. 8.15, когда потеряна связь между А и F, маршрутизатор F не будет более соединен с другим маршрутизатором посредством магистральной связи. Для восстановления целостности магистрали придется воспользоваться виртуальной связью F-E-C. 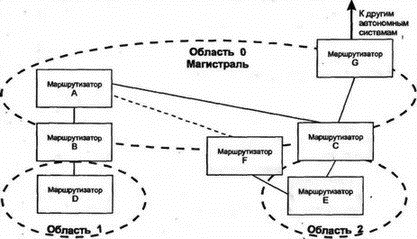 Рис. 8.15. Определение виртуальной связи 8.13.5 Маршрутизация через грань области OSPFМаршрутизатор грани имеет все данные о топологии каждой из подключенных к нему областей. Кроме того, он знает и всю топологию магистрали, поскольку подключен к ней непосредственно. 8.13.6 Использование итоговой информации внутри области OSPFКаждый маршрутизатор грани создает итоговую информацию об области и указывает другим маршрутизаторам магистрали, насколько далеко они расположены относительно сети его области. Это позволяет каждому маршрутизатору грани вычислять расстояние до точки назначения вне его собственной области и пересылать эти сведения внутрь собственной области. Итоговая информация содержит сведения о сети, подсети или идентификатор суперсети, а также маску сети и расстояние от маршрутизатора до внешней сети. Например, на рис. 8.16 маршрутизатору E нужно выбрать путь к сети M. Маршрутизатор E использует базу данных своей области для поиска расстояния dc и df до маршрутизаторов граней С и F. Каждый из них сообщает сведения о своем расстоянии mc и mf до сети M. Маршрутизатор E может сравнить dc+ mc и df+mf и выбрать кратчайший маршрут. 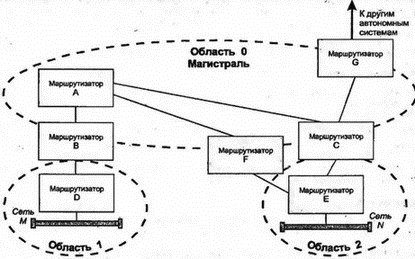 Рис 8.16. Маршрутизация между областями Отметим, что маршрутизатор В может не беспокоиться о пересылке итоговых сведений о расстоянии в область 1. Существует только один путь из этой области и можно использовать единственный элемент, описывающий путь по умолчанию, который применим для всех внешних точек назначения. Если область имеет единственный маршрутизатор грани или если неважно, какой из нескольких маршрутизаторов будет использован, то такая область именуется тупиковой (stub), и для доступа из нее к внешней точке назначения должен использоваться один или несколько маршрутизаторов по умолчанию. 8.13.7 Точка назначения вне автономной области OSPFМногие автономные системы соединены с Интернетом или другими автономными системами. Маршрутизаторы границ (boundary, не путать с гранями. — Прим. пер.) предоставляют информацию о расстоянии до сети, расположенной вне автономной системы. В OSPF существует два типа метрик для внешнего расстояния. Тип 1 эквивалентен метрике состояния локальной связи. Метрика типа 2 служит для длинных расстояний — она измеряет величины в большом диапазоне. Используя аналогию, можно уподобить метрику типа 2 километражу по общенациональной карте автодорог, на которой расстояния измеряются в сотнях км, а метрику типа 1 — километражу по карте отдельной области, где расстояния измеряются в км. На рис. 8.17 показаны два маршрута к внешней сети N. На таком расстоянии игнорируется метрика типа 1, а вычисления производятся по метрике типа 2 (будет выбран маршрут со значением этой метрики, равным 2). 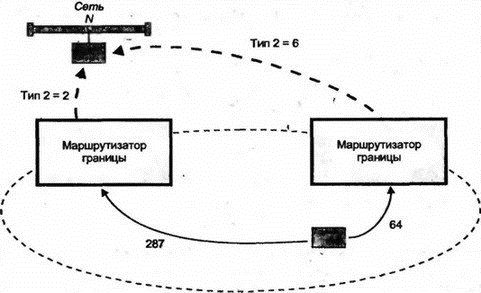 Рис. 8.17. Выбор маршрута по метрике типа 2 Еще одной возможностью OSPF (специально предназначенной для провайдеров) является возможность маршрутизатора границы автономной системы работать в качестве сервера маршрутизации (route server) и предоставлять сведения, идентифицирующие другие маршрутизаторы границ. Такие сведения должны включать: Точку назначения, Метрику, Используемый маршрутизатор границы 8.13.8 Протокол OSPFТеперь мы готовы описать некоторые внутренние свойства протокола OSPF. Каждый маршрутизатор OSPF обслуживает подробную базу данных с информацией для создания дерева маршрутизации области. Например, в базе данных отражены: ■ Каждый интерфейс маршрутизатора, соединения и связанные с ними метрики ■ Каждая сеть с множественным доступом и список всех маршрутизаторов такой сети Как маршрутизатор получает эту информацию? Он начинает исследование с поиска своих ближайших соседей, используя для этого сообщения Hello. 8.13.9 Сообщения HelloКаждый маршрутизатор OSPF конфигурируется с уникальным идентификатором, использующимся в сообщениях. Обычно в качестве идентификатора применяют наименьшую часть IP-адреса этого маршрутизатора. Маршрутизатор периодически отправляет в многоадресной рассылке сообщение Hello! (Привет!) в сети с множественным доступом (например, локальные сети Ethernet, Token-Ring или FDDI), чтобы другие маршрутизаторы смогли узнать о его активности. Это же сообщение посылается на другие концы подключенных линий "точка-точка" или виртуальных цепей, чтобы партнеры по этим связям смогли узнать о рабочем состоянии маршрутизатора. Причина эффективности сообщения Hello кроется в передаваемом в нем списке идентификаторов ближайших соседей, от которых отправитель уже получил аналогичные сообщения. Таким способом каждый маршрутизатор узнает, через кого прошло сообщение. 8.13.10 Назначенный маршрутизаторВ сетях с множественным доступом сообщение Hello используется, кроме прочего, для выбора и идентификации назначенного маршрутизатора (designated router), который выполняет две задачи: ■ Несет ответственность за надежность изменений в базах данных своих смежных соседей в соответствии с последними изменениями в топологии ■ Служит источником объявления о сетевых связях (network link advertisement), в которых перечисляются все маршрутизаторы, подключенные к сети с множественным доступом На рис. 8.18 назначенный маршрутизатор А обменивается сведениями с маршрутизаторами В, С и D своей сети, а также с маршрутизатором E, подключенным по связи "точка-точка". 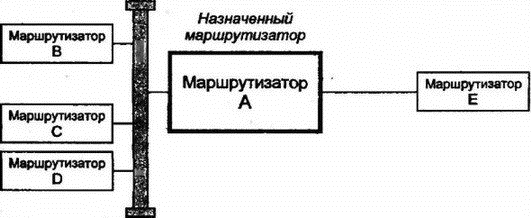 Рис. 8.18. Назначенный маршрутизатор обновляет сведения о сети у своих соседей 8.13.11 Смежность маршрутизаторовНазначенный маршрутизатор А является главным хранителем текущих сведений о сетевой топологии, предоставляя их для смежных с ним маршрутизаторов. Маршрутизаторы В, С и D синхронизируют содержимое своих баз данных с маршрутизатором А. Они не обмениваются этими сведениями друг с другом. Два маршрутизатора, которые синхронизируют свои базы данных, называются смежными (adjacent). Маршрутизаторы В и С являются соседями, но не являются смежными. Ясно, что назначенный маршрутизатор обеспечивает эффективный метод согласования содержимого баз данных маршрутизаторов локальной сети. Этот же способ применяется в сетях Frame Relay и X.25. Маршрутизаторы могут обмениваться сообщениями Hello по виртуальным цепям, выбирать назначенный маршрутизатор и синхронизовать с ним свои базы данных. Все это позволяет ускорить процесс синхронизации сведений о сети и снизить сетевой трафик. Потеря назначенного маршрутизатора приведет к серьезному нарушению работы в сети. Поэтому следует всегда выполнять резервное копирование информации из назначенного маршрутизатора и быть готовым к восстановлению этих данных. 8.13.12 Инициализация базы данных маршрутизацииПредположим, что выполняется запуск маршрутизатора В после завершения его профилактического обслуживания с выключением питания. Прежде всего В начинает прослушивать сообщения Hello, исследуя с их помощью своих ближайших соседей и определяя назначенный маршрутизатор (А). Далее В обновляет свои сведения при обмене с А. Если говорить более строго, то А и В обмениваются сообщениями Database Description (описание базы данных). В этих сообщениях находится список содержимого базы данных каждого маршрутизатора. Все элементы таблицы имеют порядковый номер, служащий для определения того, какой из маршрутизаторов содержит более свежие сведения (последовательный номер элемента увеличивается при каждом обновлении этого элемента, и обычно отсчет начинается с нуля). После завершения обмена каждый маршрутизатор будет знать: ■ Какой элемент еще не находится в локальной базе данных ■ Какой элемент имеется, но не содержит информации Сообщения Link State Request (запрос о состоянии связи) применяются для элементов, требующих обновления. Сообщение Link State Update (изменение состояния связи) приходит в ответ на Link State Request. После полного (и подтвержденного) обмена информацией базы данных считаются синхронизированными. Сообщения Link State Update применяются и для формирования отчета об изменениях в сетевой топологии. С их помощью такие изменения становятся известными по всей сети, и все базы данных синхронизируются. 8.13.13 Типы сообщений в OSPFПротокол OSPF использует сообщения пяти типов:
8.13.14 Сообщения OSPFСообщения OSPF пересылаются непосредственно в датаграммах IP с типом протокола, равным 89. Все сообщения OSPF начинаются 24-октетным заголовком (см. рис. 8.19). Номер текущей версии равен 2. Поле типа содержит номер соответствующего типа сообщения. Длина определяет общую длину сообщения, включая заголовок.  Рис. 8.19. Стандартный 24-октетный заголовок сообщения OSPF Тип аутентификации регистрируется через IANA. Безопасность и аутентификация пересылки информации маршрутизации особенно важны для надежности работы сети. 8.13.15 Содержание сообщения Link State Update протокола OSPFВ сообщениях Link State Update пересылается критическая для протокола OSPF информация. Изменения передаются между смежными маршрутизаторами. Назначенный маршрутизатор, получая сообщение об изменениях в сети с широковещательными рассылками, передает их в многоадресных рассылках другим маршрутизаторам этой сети. Изменения распространяются по области необычайно быстро. Прием каждого объявления о новом состоянии связи должен быть подтвержден. Сообщения Link State Update содержат элементы, называемые объявлениями (advertisement). Каждое сообщение может включать следующие типы объявлений:
Сообщение Link State Update начинается стандартным 24-октетным заголовком. Оставшаяся часть сообщения содержит объявления о различных типах связей (перечислены выше). 8.13.16 Улучшения в OSPFПротокол OSPF был значительно улучшен. Например, для снижения стоимости выгодно отключать коммутируемые линии и виртуальные цепи, когда по ним не пересылается трафик. Теперь в протоколе для таких линий формируются периодические сообщения Hello, что позволяет отключать линии, не участвующие в работе. Кроме того, OSPF доработан для поддержки многоадресных рассылок IP. В настоящее время OSPF активно используется, и можно ожидать дальнейших улучшений и пересмотров требований. 8.14 Маршрутизация в OSIВ OSI вместо маршрутизаторов или шлюзов используются промежуточные системы (intermediate system). Протокол маршрутизации OSI (IS-IS) был первоначально разработан для OSI, но позднее расширен на IP. Как и OSPF, IS-IS является протоколом по состоянию связи и поддерживает иерархическую маршрутизацию, типы обслуживания (TOS), разделение трафика по нескольким путям и аутентификацию. В IS-IS определены маршрутизаторы двух типов: уровня 1 для маршрутизации внутри области и уровня 2 для точек назначения вне области (последние можно рассматривать как аналоги магистральных маршрутизаторов OSPF). Маршрутизатор уровня 1 для промежуточных систем пересылает трафик, направленный вне границ области, на ближайший маршрутизатор уровня 2. Трафик маршрутизируется далее на маршрутизатор уровня 2 области назначения. Многие механизмы OSPF основаны на подобных (но не идентичных) механизмах IS-IS, например объявления о состоянии связи, поток сообщений и последовательные номера. Некоторые сторонники IS-IS считают, что этот протокол лучше IP и для OSI более выгодно применение единого интегрированного протокола, чем отдельных протоколов, для взаимодействия между маршрутизаторами. 8.15 Протоколы EGPПо определению протокол EGP используется внутри автономной системы. Различные автономные системы свободны в выборе конкретного протокола и метрик, наиболее подходящих для каждого конкретного случая. Однако как сделать правильный выбор для маршрутизации трафика между различными автономными системами? 8.16 EGPМногие годы в Интернете широко использовался простой протокол внешнего шлюза (Exterior Gateway Protocol — EGP) для обеспечения автономных систем маршрутизацией информации во внешнюю сеть. Он характеризуется очень простой структурой. Маршрутизаторы EGP соседних автономных систем обмениваются сведениями о достижимых через них сетях. EGP был разработан еще в начале 80-х годов, когда Интернет имел очень простую топологию, состоящую из магистрали и набора сетей, непосредственно подключенных к этой магистрали. Когда Интернет достиг современного размера и стал представлять собой топологию в виде сети сетей, EGP используется для пересылки сведений о доступе через цепочки автономных систем (см. рис. 8.20). 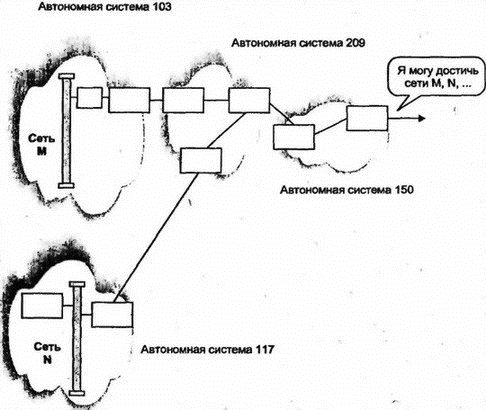 Рис. 8.20. Простое сообщение EGP в сложной сети EGP не раскрывает, через какие маршрутизаторы будет проходить датаграмма на пути следования к внешней точке назначения. Он скрывает и сведения о пересекаемых на этом пути автономных системах. Простейшие сведения о достижимости, предоставляемые EGP, не соответствуют используемому современному оборудованию. Применение EGP сокращается, поэтому мы рассмотрим его очень кратко. 8.16.1 Модель EGPМаршрутизатор EGP конфигурируется с адресом IP для одного или нескольких внешних соседних маршрутизаторов. Обычно внешние соседи соединены с общей сетью с множественным доступом или объединены одной линией "точка-точка". EGP позволяет маршрутизатору определить, какие из сетей доступны через его внешнего соседа. В EGP используются следующие понятия:
Содержание сообщений Network Reachability требует несколько большего обсуждения. Если внешний сосед соединен с линией "точка-точка", то сообщение должно идентифицировать сети, которых можно достичь через отправителя сообщения. Обеспечиваются сведения о счетчике попаданий для каждой точки назначения. На рис. 8.21 показана такая конфигурация — маршрутизатор А отчитывается о достижимости сетей перед маршрутизатором X. 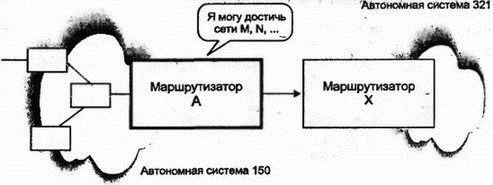 Рис. 8.21. Сообщения Network Reachability Как показано на рис. 8.22, иногда несколько маршрутизаторов различных автономных систем совместно используют сеть с множественным доступом. В этом случае маршрутизатор А по протоколу EGP будет информировать маршрутизатор X о достижимых через А, В и С сетях, предоставляя для каждой из них значения счетчика попаданий. Точно так же EGP-маршрутизатор X будет информировать маршрутизатор А о сетях, достижимых через X, Y и Z. 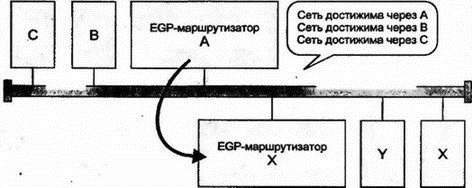 Рис. 8.22. Эффективный обмен информацией EGP Маршрутизаторы А и X являются прямыми соседями (direct neighbor), а В и С — косвенными (indirect) для маршрутизатора X. Если откажет маршрутизатор А, то X должен попытаться использовать одного из своих косвенных соседей (В или С) как прямого соседа для протокола EGP. Сообщения EGP пересылаются непосредственно в датаграммах IP, имеющих в поле протокола значение 8. 8.17 Протокол BGPВ Интернете широко используется протокол граничного шлюза (Border Gateway Protocol — BGP). Текущей версией протокола является BGP-4. В современном Интернете существует множество провайдеров, объединенных между собой на манер сети межсоединений. При движении к точке своего назначения трафик часто пересекает сети различных провайдеров. Например, показанный ниже путь начинается в JVNC, пересекает MCI, SPRINT и маршрутизатор NYSERNET, а затем достигает точки своего назначения. > traceroute nyu.edu traceroute to CMCL2.NYU.EDU (123.122.128.2), 30 hops max, 40 byte packets 1 nomad-gateway.jvnc.net (128.121.50.5C) 3 ms 3 ms 2 ms 2 liberty-gateway.jvnc.net (130.94.40.250) 49 ms 10 ms 21 ms 3 border2-hssi2-0.NewYork.mci.net (204.70.45.9) 13 ms 12 ms 19 ms 4 sprint-nap.NewYork.mci.net (204.70.45.6) 33 ms 25 ms 19 ms 5 sl-pen-2-F4/0.sprintlink.net (192.157.69.9) 24 ms 21 ms 21 ms 6 ny-nyc-2-H1/0-T3.nysernet.net (144.228.62.6) 31 ms 29 ms 24 ms 7 ny-nyc-3-F0/p.nysernet.net (169.130.10.3) 31 ms 23 ms 20 ms 8 ny-nyu-1-h1/0-T3.nysernet.net (169.130.13.18) 21 ms 34 ms 19 ms 9 NYU.EDU (128.122.128.2) 19 ms 22 ms 21 ms Целью BGP является поддержка маршрутизации через цепочку автономных систем и предотвращение формирования зацикливания. Для этого системы BGP обмениваются информацией о путях к сетям, которых они могут достичь. В отличие от EGP, BGP показывает всю цепочку автономных систем, которые нужно пройти по пути к заданной сети. Например (см. рис. 8.23), система BGP в автономной системе 34 сообщает автономной системе (АС) 205, что сети M к N находятся в этой АС. АС 205 отчитывается о пути к M и N через себя и через АС 34. Затем АС 654 указывает на путь к M к N через себя и АС 205 и 34. В этом процессе происходит увеличение длины маршрута, но для каждой следующей системы в отчете приводится описание полного пути. Таким образом, информация о доступности в BGP включает полную цепочку автономных систему которые пересекаются по пути следования к точке назначения. 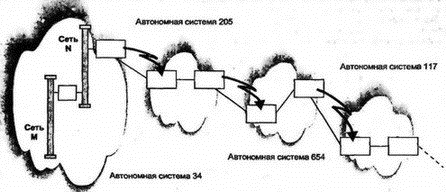 Рис. 8.23. Цепочка BGP из автономных систем Путь приводится в том порядке, в котором будут пересекаться автономные системы по пути следования к точке назначения: 654, 205, 34 Когда эти сведения будет передавать АС 117, она добавит себя в начало: 117, 654, 205, 34 Отметим, насколько просто выявляются и устраняются кольца зацикливания. Когда АС получает объявление, в котором видит собственный идентификатор, она просто игнорирует такое объявление. Кроме отчета о маршруте к отдельной сети, BGP способен распознать объединенный набор сетей, используя для этого префикс CIDR. 8.17.1 Объединение маршрутов в BGPМаршрут в Интернете состоит из сети назначения и инструкций по ее достижению. Наблюдается огромное увеличение числа маршрутов вследствие увеличения числа сетей. Необходимы меры по управлению маршрутами. Текущим методом сокращения количества маршрутов является присваивание блока адресов с общим префиксом каждому провайдеру, который выделяет из этого блока подблоки своим клиентам. Длина префикса провайдера определяется числом, указывающим в битах размер префикса в IP-адресе. Трафик может направляться из внешней автономной системы к провайдеру и его клиентам, предполагая использование одного маршрута, соответствующего префиксу. Затем провайдер самостоятельно использует длинный префикс для направления трафика каждой из автономных систем своих клиентов. Это несложно сделать для входящего трафика, но приходится выполнять обратные действия, когда провайдеру требуется обрабатывать выходящий трафик на основе внешних объявлений. Клиентская автономная система будет информировать провайдера о маршруте к своей внутренней сети. Далее провайдер объединит (aggregate) маршруты с общим префиксом в единый элемент описания маршрута, перед тем как об этом маршруте будет объявлено во внешнем мире. 8.17.2 Механизмы BGPСистемы BGP открывают соединение TCP с общеизвестным (well-known) портом 179 соседа по BGP. Каждое сообщение об открытии определяет автономную систему отправителя и имеет идентификатор BGP, а также может содержать дополнительные сведения. После открытия соединения равные между собой соседи обмениваются информацией о маршрутах. Соединение остается открытым и используется при необходимости для пересылки сведений об изменениях. Для проверки продолжения контакта системы периодически (обычно каждые 30 с) обмениваются сообщениями Keep-alive (продолжаю работать). Сеть провайдера переносит трафик между автономными системами, и очень неплохо, когда многие системы могут общаться через BGP. Такие системы способны взаимодействовать друг с другом через внутренние соединения BGP. Внешние соединения BGP используются для коммуникации между равными друг другу системами, находящимися в различных автономных системах (такие соединения называются связями, даже если это соединения TCP, которые, возможно, проходят через промежуточные маршрутизаторы). Существенным отличием BGP от других протоколов маршрутизации является способность обмена информацией о маршрутизации с хостами, а не только с маршрутизаторами. Возможна конфигурация, в которой хост возьмет на себя всю работу по общению с внешними системами BGP в соседних автономных системах. Хост может использоваться как сервер маршрутизации, пересылая информацию граничному серверу собственной автономной системы. 8.17.3 Содержание сообщения об изменениях в BGPСообщение об изменениях в BGP может содержать сведения только об одном пригодном маршруте. Однако в нем может присутствовать список из одного или нескольких изолированных (withdrawn) маршрутов, которые не следует более использовать. Описание маршрута состоит из нескольких атрибутов маршрута, которые включают:
8.17.4 Проблема выбора вариантаРис. 8.24 показывает различия между Multi-exit Discriminator и Local Preference. Системы в АС 117 хотят достичь сети N автономной системы (АС) 433. АС 654 имеет два маршрута к точке назначения, и она объявила, что лучший из них — через маршрутизатор E. Однако АС 117 имеет внутренне назначенное локальное предпочтение для доступа к сети N через АС 119. 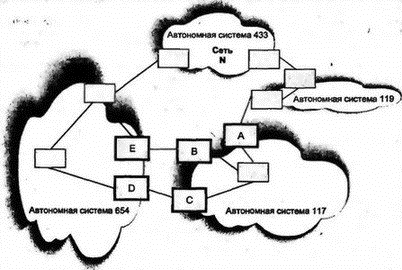 Рис. 8.24. Предпочтительные маршруты 8.17.5 Применение объединения маршрутовЦелью объединения маршрутов является исключение ненужной информации из удаленных таблиц маршрутизации. Провайдер может объединить маршруты, сведения о которых получены от его клиентской автономной системы. Как показано на рис. 8.25, маршрутизаторы BGP в автономных системах 650, 651 и 652 могут отчитаться о своих маршрутах, однако провайдер автономной системы 117 объединил их в один маршрут (элемент таблицы маршрутизации). Этот факт отражается атрибутом Atomic Aggregate. 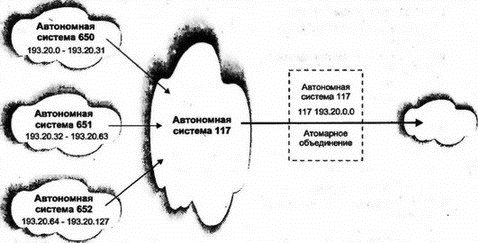 Рис. 8.25. Объединение маршрутов Отметим, что автономная система 652 может быть локальным провайдером и объединять маршруты своих клиентов, т.е. от удаленной системы может быть скрыто более одного маршрута. Каждый из объединяющих маршрутизаторов автономной системы будет пересылать трафик к точкам назначения своих клиентов на основе собственной таблицы маршрутизации. 8.17.6 Изолированные маршруты BGPМаршрут исключается, если: ■ Он присутствует в списке изолированных маршрутов из сообщения об изменениях. ■ В изменениях приведен заменяющий маршрут. ■ Система BGP завершает такое соединение. Все маршруты через эту систему становятся недействительными. 8.18 Дополнительная литератураМаршрутизация настолько важна, что ей посвящены многие RFC. Несколько наиболее существенных и широко используемых документов перечислены ниже. Следует проверить индекс RFC на наличие более поздних версий. RIP: RFC 1058 Routing Information Protocol (протокол информации о маршрутизации) RFC 1723 RIP Version 2 Carrying Additional Information (RIP, версия 2: перенос дополнительной информации) RFC 1582 Extensions to RIP to Support Demand Circuits (расширение RIP для поддержки цепей по требованию) OSPF: RFC 1583 OSPF Version 2 (OSPF, версия 2) RFC 1793 Extending OSPF to Support Demand Circuits (расширение OSPF для поддержки цепей по требованию) RFC 1586 Guidelines for Running OSPF Over Frame Relay Networks (рекомендации по работе с OSPF через сети Frame Relay) RFC 1584 Multicast Extensions to OSPF (расширение OSPF для многоадресных рассылок) RFC 1403 BGP OSPF Interaction (взаимодействие BGP и OSPF) BGP (в будущем предполагается вытеснение BGP протоколом IDRP для OSI — Inter-Domain Routing Protocol, протокол междоменной маршрутизации): RFC 1771 A Border Gateway Protocol 4 (BGP-4) (протокол граничного шлюза, версия 4) RFC 1773 Experience with the BGP-4 Protocol (исследование протокола BGP-4) RFC 1772 Application of the Border Gateway Protocol in the Internet (Приложения для BGP в Интернете) Кроме того, можно обратиться к интерактивной документации компании Cisco по адресу www.cisco.com для получения технических данных о протоколах IGRP и EIGRP. Надежное казино - это ваш ключ к большим выигрышам. |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||