|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Глава 19WWW 19.1 Введение19.1.1 ГипертекстИдея гипертекста (hypertext) известна уже многие годы. Она основана на следующих положениях: ■ Выделенные в документе фразы связаны с указателями на другие документы. ■ Пользователь может перейти на другой документ, щелкнув мышью на выделенной фразе. Пользователи Microsoft Windows или Macintosh хорошо знакомы с гипертекстом по справочным системам, хотя могли и не слышать о самом термине. Например, меню справки может выглядеть так: Для получения более подробных сведений по каждой из этих тем следует щелкнуть мышью на соответствующем заголовке. В данном случае каждая из выделенных фраз заголовка обеспечивает гипертекстовую ссылку на другой документ. В иных пользовательских интерфейсах такие фразы могут отличаться цветом или иным способом выделения. 19.1.2 ГипермедиаИдея гипертекста расширяется до понятия гипермедиа (hypermedia), когда выделенная фраза указывает на изображение, звуковой файл, видеоклип или иные виды двоичных данных. Изображение может также содержать элементы, щелчок на которых мышью вызывает ссылки на документы, изображения, звуковые файлы или видеоклипы. Такой способ доступа к информации уже давно и успешно используется на компакт-дисках. (Однако наиболее общим свойством гипермедиа-гипертекста следует считать не возможность перехода по ссылкам и не встраивание различных типов информации, а нелинейную структуру самого гипертекста. В отличие от обычного текста, который является линейным и состоит из последовательных строк, гипертекст состоит из отдельных фрагментов, объединенных ссылками. Структура такого текста может быть не только не линейной, но даже и не древовидной. Вместе с множеством достоинств в гипертексте есть один недостаток: чтобы просмотреть последовательно весь документ от начала до конца, придется отслеживать все переходы по ссылкам. Разумеется, этот процесс автоматизирован в современных браузерах WWW, которые выделяют в тексте не только сами ссылки, но и специальным образом отмечают уже просмотренные пользователем ссылки вместе с реализацией функции возврата по последней ссылке. — Прим. пер.) 19.1.3 Гипермедиа и WWWИспользование гипермедиа расширяется на сетевую информацию через службу Интернета World Wide Web (WWW). В этом случае выделенные фразы могут указывать не только на локальный элемент, но и на любой элемент данных любого удаленного компьютера. Именно эта простая идея лежит в основе пользовательского интерфейса, существенно упрощающего перемещение по Интернету. 19.2 История WWWИдея WWW возникла среди физиков. Теоретические основы были заложены Тимом Бернерс-Ли (Tim Berners-Lee) из швейцарского центра физических исследований ЦЕРН. 19.3 Браузеры WWWТолчком к распространению WWW послужило создание Марком Андрессеном в 1992 г. клиента WWW под названием Mosaic. В то время Андрессен был аспирантом Иллинойского университета и сотрудником университетского центра по применению суперкомпьютеров (National Center for Supercomputing Applications — NCSA). Mosaic был первым браузером (browser) для Интернета, т.е. программой доступа к данным из различных источников, включая гипертекстовые архивы, серверы gopher, поисковые средства баз данных, сайты пересылки файлов и группы новостей. Как показано на рис. 19.1, браузер может работать по нескольким протоколам, которые требуются для доступа к различной информации. На основе Mosaic был создан мощный коммерческий браузер Netscape Navigator, распространяемый компанией Netscape Communications Corporation. На рис. 19.2 представлена домашняя страница этой компании в браузере Netscape. 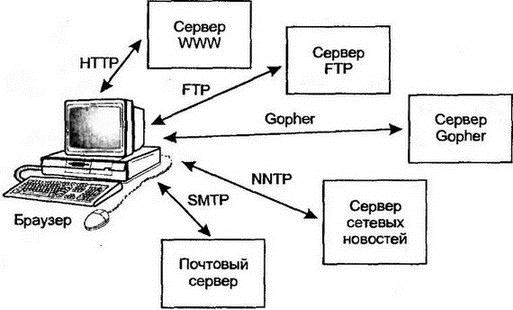 Рис. 19.1. Браузер может работать по нескольким протоколам  Рис. 19.2. Домашняя страница компании Netscape в браузере этой компании. Использование браузеров и серверов WWW расширяется, равно как и происходит ускоренное совершенствование технологий и протоколов. 19.4 URLУспех WWW обеспечивается и очень важной концепцией унификации. Каждый информационный ресурс WWW идентифицирован унифицированным указателем ресурсов (Uniform Resource Locator — URL), иногда называемым и универсальным указателем ресурсов (Universal Resource Locator). URL определяет: ■ Имя ресурса ■ Местоположение ресурса ■ Используемый для доступа к ресурсу протокол URL является частным случаем универсального идентификатора ресурса (Universal Resource Identifier — URI), обеспечивающего единообразный способ именования любых информационных ресурсов. 19.4.1 URL для гипертекстаЕсли в браузере WWW ввести значение URL гипертекстового документа, браузер извлечет этот документ по протоколу пересылки гипертекста (Hypertext Transfer Protocol — HTTP). Формат URL для гипертекста: http://имя-системы/имя-файла Например: http://www.ibm.com/index.html Если указать только: http://имя-системы то браузер WWW возвратит по умолчанию домашнюю страницу (home page), которая обычно именуется home.html или index.html. Более общий формат URL для протокола HTTP имеет вид: http://хост:порт/путь?путь_поиска Не менее проста структура URL для других протоколов. 19.4.2 URL для gopherЕсли в браузере ввести URL: gopher://gopher.jvnc.net/ то браузер будет работать как клиент gopher и соединится с сервером gopher по имени gopher.jvnc.net. Если сервер недоступен на обычном порту (70), но использует другой порт, например 3333, то нужно указать URL в виде: gopher://gopher.somewhere.edu:3333/ 19.4.3 URL для FTPПересылка файлов по протоколу FTP может быть выполнена по URL: ftp://ds.internic.net/ или с указанием определенного файла file://ds.internic.net/rfc/rfc1738.txt Для доступа по FTP к сайту с вводом пароля и идентификатора пользователя применяется: ftр://имя_пользователя:пароль@идентификатор_хоста Хост можно указать через IP-адрес или имя домена. Для доступа к файлу URL должен быть похож на: file://ds.internic.net/rfc/rfc1738.txt Отметим, что протокол не указан, однако по умолчанию используется FTP. 19.4.4 URL для telnetСоединиться по telnet поможет: telnet://ds.internic.net/ Или в более общей форме: telnet://имя_пользователя:пароль@идентификатор_хоста/ 19.4.5 URL для сетевых новостейURL для группы новостей имеет вид news.имя_группы, например: news:rec.airplane Сервер новостей не идентифицирован в URL. Вместо этого его название (или адрес) указывается в параметрах конфигурации браузера. 19.4.6 URL электронной почтыURL для отправки электронной почты: mailto:пользователь@размещение_почты Как и для новостей, имя или адрес почтового шлюза указывается в конфигурационной информации браузера. 19.4.7 URL для WAISХотя и редко используемый (если вообще когда-либо), URL был определен для доступа к базам данных WAIS по протоколу Z39.50. Например, интерфейс для каталога общедоступного сервера WAIS имеет форму: wais://cnidr.org/каталог_сервера В общем случае URL для WAIS имеют формат: wais://хост:порт/база_данных wais://хост:порт/база_данных?search wais://хост:порт/база_данных/тип/путь На момент выхода книги немногие (если вообще какие-нибудь) браузеры поддерживали протокол доступа к WAIS. Поиск в базах данных обычно выполняется путем заполнения форм и отправки их на сервер WWW, который должен запустить соответствующее поисковое средство. 19.5 Обобщенный формат URLОбобщая вышесказанное, отметим, что: ■ URL начинается с указания используемого протокола доступа. ■ Для всех приложений, кроме сетевых новостей и электронной почты, далее следует разделитель ://. ■ Затем указывается имя хоста сервера. ■ Наконец определяется ресурс (иначе будет извлечен файл по умолчанию). Для сетевых новостей и электронной почты местоположение нужного сервера новостей и почтового шлюза определяется конфигурационной информацией браузера. Применяется только часть разделителя (:), и в URL не указывается никакой серверный хост. 19.5.1 Специальные символыИногда идентификатор ресурса содержит пробелы или иные специальные символы (например, слэш или двоеточие), которые применяются в URL как разделители. Например, имена файлов Macintosh и Windows 95 могут содержать пробелы и другие необычные символы. Специальные символы в именах ресурсов записываются строкой, начинающейся с символа процентов (%). Такое отображение показано в таблице 19.1. Таблица 19.1 Отображение специальных символов
19.6 Введение в HTMLДокументы WWW с гипертекстовыми ссылками записываются на языке разметки гипертекста (Hypertext Markup Language — HTML). Гипертекстовые файлы, совместимые с версиями 1 и 2 HTML, обычно имеют имена в формате: имя_файла.html Файл, содержащий расширенные возможности версии 3, именуется как: имя_файла.html3 На компьютерах DOS и Windows применяется суффикс htm или ht3. HTML основан на обобщенном стандарте разметки гипертекста (Standard Generalized Markup Language — SGML). Основная идея состоит в размещении в документе специальных тегов для идентификации таких элементов, как заголовки, подзаголовки, границы параграфов, маркированные списки, графические символы и т.д. HTML должен быть независим от платформы, чтобы обеспечить просмотр гипертекстового документа любыми клиентскими устройствами: от неинтеллектуальных терминалов до мощных рабочих станций. Клиенты должны уметь выводить документы на экранах любого размера и использовать локально выбранные шрифты. Далее мы рассмотрим основы HTML, следуя спецификации HTML версии 3. HTML становится очень большим по объему языком и имеет массу возможностей. Например, можно не указывать описание структуры сложных форм при записи пересылаемых от клиента на сервер данных. Такие формы могут использоваться для ввода запросов в базу данных или заказов товаров в интерактивных магазинах. Другая важная способность — это построение изображений с областями для щелчка мышью. Конечный пользователь может щелкать на области в изображении, чтобы выбрать связанный с этой областью документ. 19.6.1 Создание документа на HTMLНекоторые детали отображения документа оставлены клиенту. Браузер настольной системы обычно разрешает конечному пользователю выбрать шрифты для выводимого текста. Текст HTML-документа будет переформатирован согласно размеру окна экрана и выбранного шрифта. Автор документа HTML может определить следующие элементы: ■ Заголовки ■ Подзаголовки ■ Абзацы ■ Ссылки с помощью URL ■ Списки ■ Предварительно отформатированный текст ■ Форматирование символов ■ Специальные символы ■ Встроенные изображения ■ Внешние графические изображения ■ Формы для ввода данных ■ Карту областей щелчка мышью ■ Таблицы и формулы Включенный в HTML-документ элемент определяется соответствующим тегом. Например, тег <TITLE> вводит заголовок документа. Гипертекстовый документ можно создать, используя обычный текстовый редактор. Однако популярные программы текстовых процессоров обеспечивают подключаемые модули для автоматизации создания тегов и позволяют проводить работу в режиме "Что видим, то и получаем". Существуют специальные программные продукты для создания гипертекстовых документов. В них автоматизировано построение различных элементов и по желанию можно скрыть от пользователя примененные теги. Хороший способ создания документа HTML состоит в том, чтобы отформатировать документ в обычном текстовом процессоре, а затем применить конвертер для автоматического преобразования в HTML. Общее понимание принципов работы HTML полезно при рассмотрении способов наиболее эффективного использования любых его средств. Кроме того, постоянно появляются новые возможности в самом языке, которые еще не реализованы в соответствующих инструментах, и такого рода данные могут вводиться только вручную. К счастью, HTML достаточно прост для изучения. 19.6.2 Теги HTMLТег состоит из названия элемента и параметров, заключенных в угловые скобки (<...>). Ниже мы рассмотрим наиболее широко используемые теги. Символы тегов не чувствительны к регистру, но для постоянства мы будем записывать их только в верхнем регистре. Большинство тегов применяется парами, показывая начало и конец элемента. Заключительный тег имеет то же самое имя, что и начальный, но начинается с символа слэша </...>. Например: <TITLE>Welcome То The Web</TITLE> 19.6.3 Общий формат HTML-документаНесколько тегов служат для определения начала и конца HTML-документа или выделяют в нем заголовок и тело. Например: <HTML>Начало гипертекстового документа. <head>Начало заголовка. <!--Last Modified on October 21, 1995-->Комментарий. <base href = "http://www.abc.com/ind.html3">Указывает размещение данного документа. <TITLE>Welcome to the Web</TITLE>Заголовок, обычно выводимый вверху клиентского экрана. </head>Конец заголовка. <BODY>Начало тела документа. ... </BODY>Конец тела документа. </HTML>Конец гипертекстового документа. 19.6.4 Заголовки HTMLГлавы, разделы и подразделы документа начинаются заголовками. Можно использовать шесть уровней заголовков, и каждый будет выведен собственным форматом. Например, заголовки первого уровня обычно представлены жирным шрифтом большого размера: <Н1>Это заголовок первого уровня — самый главный</Н1> <Н2>Заголовок второго уровня можно применять для разделов</H2> <H3>Существуют еще заголовки уровней с третьего по шестой</H3> 19.6.5 Абзацы и разрывыАвтор должен указывать границы абзацев, иначе весь выводимый текст сольется вместе. Клиентская программа обычно объединяет повторяющиеся пробелы и пустые строки в один пробел или пустую строку, если не указано иное форматирование. Старые версии HTML выделяли абзацы, помещая тег <P> в начале каждого нового абзаца: <P>Это абзац. <P>Это следующий абзац. Это справедливо и для версии 3, но в ней можно применять и пару тегов, отмечающих начало и конец абзаца: <P> Это абзац.</P> По умолчанию большинство браузеров вставляет между абзацами пустую строку (в версии 3 есть теги для описания другого стиля абзацев, например, для отступа в первой строке). Если нужно начать новую строку, но не новый абзац, используют разрыв: Розы — красные, <BR> Фиалки — голубые.<BR> 19.6.6 Неупорядоченные спискиНеупорядоченный список выводится как последовательность помеченных элементов. Например: <UL> <LI> Яблоко <LI> Груша </UL> В версии 3 определен необязательный заголовок списка и тег конца элемента: <UL> <LH>Виды фруктов</LH> <LI>Яблоко</LI> <LI>Груша<LI> </UL> 19.6.7 Упорядоченные спискиУпорядоченные списки имеют такую же структуру, но элементы нумеруются: <OL> <LH>Это упорядоченный список.</LH> <LI>Первый элемент. <LI>Следующий элемент. </OL> Как и раньше, тег конца элемента списка (</LI>) и заголовок списка (<LH> ... </LH>) необязательны. 19.6.8 Список определенийСписок определений является последовательностью терминов и их определений: <DL> <LH>Терминология WWW</LH> <DТ>Язык разметки гипертекста (HTML) <DD>Язык форматирования для записи гипертекстовых документов. Теги документа идентифицируют такие элементы, как заголовки, абзацы или списки. <DТ>Протокол пересылки гипертекста (HTTP) <DD>Протокол для запроса и пересылки гипертекстовых документов. </DL> При выводе это будет выглядеть как: Терминология WWW Язык разметки гипертекста Язык форматирования для записи гипертекстовых документов. Теги документа идентифицируют такие элементы, как заголовки, абзацы или списки. Протокол пересылки гипертекста. Протокол для запроса и пересылки гипертекстовых документов. Списки любого типа могут быть вложенными. 19.6.9 Дополнительные тегиДля выделения отдельных частей документа можно воспользоваться горизонтальным разделителем, который пересекает всю ширину выводимой страницы: <P><HR></P> Иногда нужно получить текст, размещенный точно так же, как он был введен. Тег предформатирования (<PRE>) указывает браузеру на вывод текста "как есть": <PRE> Этот текст будет показан так, как написан, включая отступы. </PRE> Цитируемый блок текста (block quote) — еще один способ выделения фрагмента в тексте. Обычно это делается сдвигом вправо всего блока. В версии 2 применяется тег <BLOCKQUOTE>. <BLOCKQUOTE> Это — цитируемый блок. Возможно, он будет выведен пользователю сдвинутым вправо. </BLOCKQUOTE> В версии 3 название тега сокращено до <BQ>. 19.6.10 Выделение в текстеИногда требуется выделить фрагмент текста особым образом, например полужирным шрифтом или курсивом. Это можно сделать двумя способами: 1. Оставить детали вывода на усмотрение браузера <ЕМ> Обычно выводится курсивом. </ЕМ> <STRONG> Обычно выводится полужирным шрифтом. </STRONG> <CODE> Обычно отображается моноширинным шрифтом. </CODE> 2. Явно указать способ изображения текста: <I> Вывести курсивом. </I> <В> Вывести полужирным шрифтом. </В> <U> Подчеркнуть текст. </U> <S> Перечеркнуть текст. </S> <TT> Вывести моноширинным шрифтом (как на пишущей машинке). </TT> <SUB> Подстрочными символами. </SUB> <SUP> Надстрочными символами. </SUP> Версия 3 имеет много дополнительных свойств, обеспечивая автору разнообразные возможности по управлению выводом текста клиенту. 19.6.11 СсылкиЧтобы включить в документ ссылку, нужно: ■ Использовать теги начала и конца ссылки ■ Указать URL связанного со ссылкой документа ■ Обеспечить метку для щелчка мышью (обычно выводится подчеркиванием или голубым цветом). Ниже показан пример ссылки. Символ А определяет название тега, именуемого точкой привязки, или якорем. Параметр HREF идентифицирует элемент, через который выполняется ссылка. Текст перед разделителем </А> становится меткой для щелчка мышью на этой ссылке: <А HREF= "http://www.abc.com/wwwdocs/showme.html">Щелкните здесь для вывода дополнительных сведений</А> Не всегда нужно записывать полный URL для связанного документа. Предположим, что документ showme.html содержит ссылку на файл more.html из того же каталога. Тогда можно записать ссылку как: <А HREF = "more.html">дополнительные сведения</A> Такой способ называется указанием относительного пути. Его можно применять и для подкаталогов текущего каталога. 19.6.12 Ссылки на локальные документыМожно создать ссылку на документ локального хоста. Например, ссылка на локальный документ DOS выглядит как: <А HREF = "file:///c:\webdocs\home.htm">Документ локального хоста</А> Для извлечения такого документа нет надобности в протоколе HTTP. Отметим, что имя хоста не указано — между косыми чертами (///) ничего нет. Допустимо ссылаться на отдельные места того же самого документа. Сначала маркируется нужное место. В версии 2 это выполняется вставкой точки привязки с использованием параметра NAME: <A NAME = "Раздел3"> 3. Самолеты </А> Затем создается ссылка на это место документа путем указания перед его именем символа диез: См. <А HREF = "#Раздел3"> обратитесь к разделу три </А> за дополнительной информацией. Если пользователь щелкнет мышью на подчеркнутой фразе (обратитесь к разделу три), клиент "перескочит" на заданное место документа. В версии 3, вместо маркировки позиции в документе специальным тегом, можно добавить идентификатор к любому уже существующему тегу. Например, ниже мы добавляем идентификатор для тега Н2: <Н2 ID = "Раздел3"> 3. Самолеты </Н2> 19.6.13 ИзображенияТег IMG служит для вставки изображения в документ. Тег содержит параметр SRC, который определяет URL для файла, имеющего изображение. URL изображений выглядит как любые другие URL. Ссылка на изображение будет выглядеть как: <IMG SRC = "http://www.abc.com/wwwdocs/ourlogo.gif"> <IMG SRC = "bigpic.jpeg"> <IMG SRC = "file:///c:\webdocs\building.gif"> Ha WWW-страницах часто используются изображения в формате для обмена графикой (Graphics Interchange Format — GIF). Для сжатия точечных (растровых) изображений служит формат перемещаемой сетевой графики (Portable Network Graphics — PNG). Еще одним популярным форматом является формат объединенной экспертной группы по фотографии (Joint Photographic Experts Group — JPEG). Он был разработан для сжатия фотографических изображений, но иногда используется и для других типов графики. Не имеющие графических возможностей браузеры будут игнорировать теги IMG, если только в них не указан параметр ALT. Например: <IMG SRC = "bigpic.jpeg" ALT = "Памятник Вашингтону"> Вместо изображения текстовый браузер выведет строку "Памятник Вашингтону". 19.6.14 Просмотр исходного кода HTMLЧтобы хорошо изучить HTML, нужно познакомиться с исходными кодами документов. Обычно браузер имеет для этого специальный режим, иначе придется сохранить документ на диске и затем просмотреть его в обычном текстовом редакторе. 19.7 Архитектура HTTPКак и в gopher, извлечение гипертекстового документа достаточно просто. Как показано на рис. 19.3, клиент соединяется с сервером WWW, извлекает часть документа (обычно ее называют страницей. — Прим. пер.) и закрывает соединение. Браузер выводит извлеченную страницу, а пользователь может выполнять следующую операцию. 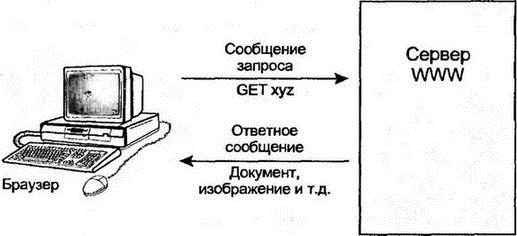 Рис. 19.3. Браузер извлекает страницу гипертекста с сервера WWW. Сервер WWW, предоставляющий только текстовые документы, работает очень эффективно и может поддерживать множество пользователей. Однако объем информации резко увеличивается при работе и перемещении графических изображений или звуковых файлов. Эти объекты имеют значительный размер, и для их пересылки требуется большее количество ресурсов сети и центрального процессора, чем для обмена обычными текстовыми файлами. Более того, некоторые запросы вызывают программы, формирующие ответную информацию. Для этого нужно еще больше системных ресурсов. 19.7.1 Прокси-серверПрокси-сервер WWW используется для доступа к внешним серверам WWW клиентов, расположенных в пределах зоны безопасности сети. В этом случае браузер клиента конфигурируется для отправки всех запросов прокси-серверу, который, в свою очередь, взаимодействует с реальным сервером WWW и возвращает клиенту полученный результат. На рис. 19.4 показан клиент, обращающийся к серверу WWW через прокси. 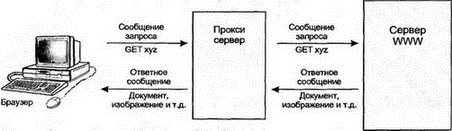 Рис. 19.4. Извлечение информации с сервера WWW через прокси Некоторые прокси кешируют пересылаемые документы и могут самостоятельно отвечать на повторные запросы. 19.8 Протокол HTTPСлужба WWW реализуется поверх соединений TCP (хотя можно применять и другие транспорты) и разрастается вместе с Интернетом. Работа сервера WWW заключается в следующем: ■ Клиент соединяется с сервером. ■ Клиент посылает запрос, например: GET /home.html НТТР./1.0 ACCEPT: text/html ■ Сервер отвечает на запрос, указывая тип пересылаемой информации и передавая затребованный документ. Сервер может взаимодействовать с различными видами клиентов благодаря подстройке отправляемых данных под возможности конкретного клиента. Клиент может объявлять о своих возможностях в операторе Accept:, отправляемом на сервер в запросе на извлечение документа. Один клиент может указать, что способен принимать только тексты в формате HTML, а другой — о своих возможностях по обработке текстов, изображений и звуковых файлов. Обычно сервер WWW работает через общеизвестный порт TCP с номером 80. Иногда серверы конфигурируются для работы через другие порты. В объектно-ориентированном языке (HTTP) вместо терминов "команда" или "запрос" используется термин "метод". Клиент может запрашивать три стандартных метода:
Метод GET извлекает страницу. Страница — это документ, содержащий любые изображения или звуковые файлы. Она может размещаться на одном листе или иметь размер целой книги. Команда HEAD позволяет клиенту до начала пересылки определить длину и тип данных извлекаемого элемента, равно как и дату последнего изменения и текущую версию. Если браузер уже кешировал на локальном диске последнюю версию документа, то документ будет извлечен локально. 19.8.1 Пример типичного диалога HTTPОдин из доводов в пользу быстрого развития протокола WWW состоит в том, что разработчики не тратили время на повторное изобретение колеса, а заимствовали форматы заголовков и типов данных из классической электронной почты и стандартов MIME. Представленный ниже диалог показывает, насколько просто выполняется взаимодействие в HTTP. Запрос GET/HTTP/1.0 требует извлечения с сервера документа по умолчанию и объявляет, что клиент работает по версии 1.0 протокола HTTP. Клиент также указывает, что способен принимать только текстовые документы HTML. Ответ сервера объявляет об используемой версии HTTP (1.0) и коде статуса; 200 — означает успешное выполнение запроса. Далее следует серия подобных MIME заголовков. Пустая строка (<CR><LF>) сообщает о конце раздела заголовков и начале тела документа. GET/HTTP/1.0 ACCEPT: text/html HTTP/1.0 200 Document follows Date: Sat, 28 Oct 1995 14:07:25 GMT Server: NCSA/1.5.1 Content-type: text/html Last-modified: Tue, 09 May 1995 01:22:41 GMT Content-length: 1563 <TITLE>InterNIC Directory and Database Services Home Page</TITLE> <IMG src = "/Pics/logo.gif" alt = ""> <a href = ds/dspg01.html> <H1>InterNIC Directory and Database Services</H1></a> <P> Welcome to InterNIC Directory and Database Services provided by AT&T. These services are partially supported through a cooperative agreement with the National Science Foundation. . . . Сервер закроет соединение, когда будет завершена пересылка. 19.8.2 Заголовки сообщенияВ таблицах 19.2–19.5 представлены краткие описания заголовков в запросах и ответах. Таблица 19.2 Главные заголовки HTTP
Таблица 19.3 Заголовки запросов HTTP
Таблица 19.4 Заголовки ответов HTTP
Таблица 19.5 Заголовки элементов HTTP
■ В сообщении первыми стоят главные заголовки как в запросах, так и в ответах (таблица 19.2). ■ Затем следуют заголовки, специфичные для запросов (таблица 19.3) или ответов (таблица 19.4). ■ Наконец последними стоят заголовки элементов, которые обеспечивают детальное описание данного элемента (таблица 19.5). Нужно помнить, что запрос POST приводит к пересылке от клиента к серверу определенных элементов, например данных формы. Поэтому заголовки элементов могут появляться в запросах и ответах. 19.8.3 Коды состоянияКоды состояния используются подобно электронной почте и пересылке файлов (FTP). Наиболее распространенные значения кодов:
Более детальные сведения обозначаются дополнительными кодами. 19.9 Продолжение совершенствованияВ ответ на требования пользователей по обеспечению больших функциональных возможностей HTTP и HTML постоянно совершенствуются. На момент написания книги шла разработка стандартов для обеспечения безопасности взаимодействий клиент/сервер и для создания действительно защищенных коммерческих систем. Других достижений можно ожидать в области определения и реализации независимой от размещения ресурсов схемы именования (Uniform Resource Names — URN), поскольку существует проблема потери ссылки при перемещении документа на другой компьютер или в другой каталог. URN делает доступным извлечение нужного документа из другого места сети. Можно указать несколько мест размещения документа с выбором оптимального варианта для извлечения. 19.10 Дополнительная литератураRFC 1738 содержит описание URL. RFC 1630 — это техническое руководство по Universal Resource Identifiers. Спецификация HTTP 1.0 была опубликована в RFC 1945. Отдельные документы по HTML существуют в Интернете в форме проектов, к которым можно обратиться по ftp://ftp.internic.net/internet-drafts. Информация о безопасности в HTTP, HTML и WWW доступна на сайте консорциума W3 (http://www.w3.org/). |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||