|
||||
|
|
ТЕХНОЛОГИИ: Новая надеждаВыхода графического ускорителя нового поколения от ATI, известного под кодовым названием R520, ожидали долго. Даже, пожалуй, слишком долго: мы искали его на Computex, мы надеялись увидеть его в июле, когда nVidia начала продавать видеокарты GeForce 7800GTX, затем в сентябре, когда, казалось, ждать дальше уже было некуда. Но прошли уже все мыслимые сроки, а R520 все не было. Тестовая система: Материнская плата: ASUS A8N SLI Deluxe. Оперативная память: Corsair DDR CMX512-3200XLPRO, 2x512 Мбайт, 2-2-2-10. Видеокарта: nVidia 7800GTX 256 Мбайт, ATI X1800XT 512 Мбайт. Операционная система: Microsoft Windows XP SP2. Драйверы: последние официальные на момент написания статьи. Все настройки системы оставлялись по умолчанию, процессоры функционировали на своих номинальных частотах: Athlon 64 FX-57 2,8 ГГц - множитель 14, шина 200 МГц, память в синхронном режиме с таймингами 2-2-2-10 Вот и получилось, что ситуация на рынке сегодня далеко не в пользу канадцев. Уверенно лидируя в «дешевых» и «интегрированных» нишах, солидных по оборотам, но, увы, не приносящих по-настоящему большой прибыли, самые «вкусные», высокопроизводительные сегменты еще недавно доминировавшая здесь ATI утратила. В результате - провальный квартал и 104 млн. долларов убытков. Почему так вышло? Думаю, отчасти виноват новый, прогрессивный 90-нм low-k технологический процесс, освоение которого на заводах TSMC, производящей GPU по заказам aTI, вероятно, проходило далеко не так гладко, как рапортуют теперь маркетологи[Все мы помним, что первая итерация 90-нм процессоров Intel получилась «слишком горячей» (большие токи утечки вносили ощутимый вклад в тепловыделение ранних степпингов Prescott), а у aMD - «слишком медленной». Да и nVidia, тоже размещающая заказы на заводах TSMC, предпочла изготавливать свой новый GPU G70 по «старому, дорогому и медленному», зато проверенному 110-нм техпроцессу]. Отчасти - «погоня за двумя зайцами», то есть одновременная разработка и запуск в серию двух совершенно разных продуктов: основанного на унифицированной шейдерной архитектуре процессора R500[На нем построена приставка Xbox 360, выпуск которой намечен на ноябрь], который невозможно использовать в обычных видеокартах; и нашего сегодняшнего героя R520, построенного по «классической», но сильно переработанной архитектуре. Вдобавок чип получился по-настоящему новым и революционным (после едва ли не трех лет постепенной эволюции удачной линейки Radeon 9xxx), так что его проектирование и доводка наверняка отличались особенной сложностью, и сколько ушло итераций на то, чтобы отловить все ошибки, - знают только инженеры aTI. Впрочем, довольно толочь воду в ступе. В конце концов, пусть и с полугодовым опозданием, но R520 - перед нами, и в ближайшее время видеокарты на его основе появятся в розничной продаже. Технические характеристики новинки Итак, что же удалось сделать ATI? Я бы сказал, невероятно многое. Словно все три года, пока регулярно выходили превосходные видеокарты, полученные экстенсивным расширением старой технологии, инженеры откладывали все по-настоящему интересные задумки в долгий ящик, чтобы потом реализовать их скопом. Во-первых, радикально переработано сердце любого графического ускорителя - блок пиксельных процессоров, отвечающий за закраску сцены по заданным алгоритмам. Традиционно в этом блоке ставится энное количество одинаковых пиксельных конвейеров, каждый из которых «в параллель» с остальными вычисляет цвет отдельно взятого пиксела (или субпиксела) в нашей сцене[Строго говоря, одиночные конвейеры сейчас уже никто не использует, поскольку гораздо эффективнее собирать их в группы по четыре штуки (процессоры квадов), чтобы они обрабатывали не отдельные пикселы, а блоки 2x2 пиксела (квады). При этом часть логики удается объединить, проводя некоторые операции не над отдельными пикселами, а над квадами целом - это и быстрее и проще]. То есть, единожды попав на какой-нибудь конвейер, пиксел, обрабатываемый соответствующей ему программой - пиксельным шейдером, раз за разом проходит по этому конвейеру, как бы крутится внутри него до тех пор, пока не закончится вычисление его цвета. Соответственно все устройства, и, в частности, текстурные модули, выбирающие из видеопамяти необходимые для этих вычислений данные, напрямую подключены к исполнительным устройствам конвейера. Схема достаточно простая и эффективная: нужно увеличить вычислительную мощность графического процессора - ставим больше конвейеров, и количество обрабатываемых за такт пикселов, а вместе тем и скорость закраски изображения пропорционально возрастет. Инженеры aTI пошли другим, «процессорным» путем,[Подробнее см. «КТ» #609 (рубрика 'Архитектура ХХ века")] не став дублировать конвейеры, а организовав из GPU своеобразный суперскалярный процессор с единым конвейером, на котором несколько пикселов могут обрабатываться одновременно. Вместо того чтобы «распихать» пикселы по разным конвейерам, R520 накапливает их (вместе с соответствующими шейдерными инструкциями) в специальном огромном планировщике, который aTI называет Ultra-Threading Dispatch Processor. Почему Ultra? Да потому, что этот планировщик управляет одновременным выполнением колоссального числа операций (512 квадов 2x2 пиксела в High-End, и более скромные 128 квадов - в менее дорогих Middle-End и Low-End графических чипах). Все квады хранятся в длиннющих очередях, и по мере того, как освобождаются вычислительные ресурсы, отправляются на соответствующее устройство, будь то вычислительный, текстурный блок или блок графического Back-end’а (запись результатов во фрейм-буфер, блендинг, z-тест, антиалиасинг и пр.). Это более сложный подход, чем несколько однотипных конвейров, но и более гибкий и эффективный. Например, мы можем сколь угодно гибко варьировать соотношение количества вычислительных и текстурных модулей, так как они больше не подключаются друг к другу, образуя единое целое, а разделены по операциям, которые они выполняют[Подобную оптимизацию можно будет увидеть в ядре R530 - сердце Middle-End ускорителя Radeon X1600. В нем будет три процессора квадов (3x4 = 12 пиксельных конвейера), но всего один процессор текстур (1x4 = 4 TMU). Для современных шейдеров, которые больше занимаются вычислениями, нежели выборкой данных из оперативной памяти, такой подход оправдан, поскольку позволяет рациональнее расходовать площадь кристалла, увеличив число пиксельных конвейеров за счет сокращения числа TMU]. Речь идет о текстурных операциях, которые ранее могли блокировать конвейер до тех пор, пока не будет завершена операция выборки очередного тексела[Традиционный конвейер GPU устроен гораздо проще конвейера CPU, так что переупорядочивания инструкций, которое позволило бы обогнать застрявшую в конвейере инструкцию другой, не зависящей от нее, - в графических процессорах нет]. Заодно решается и проблема динамических условных переходов в шейдерах. Что это такое? Сейчас объясню: ради все того же упрощения пиксельных конвейеров, которых нужно уместить побольше на ограниченный кусочек кремния, эти конвейеры устраивают таким образом, что они вначале как бы настраиваются на ту или иную конкретную операцию над пикселами (сложение, вычитание, умножение) и затем применяют ее много раз подряд к разным пикселам; после чего перестраиваются на следующую операцию и снова применяют ее много раз к тем же пикселам, и т. д. Поскольку один и тот же шейдер обычно требуется применить к умопомрачительному количеству пикселов, такая схема обычно работает замечательно. Однако если встречается шейдер, в котором есть динамические условные переходы (которые нельзя заранее предсказать), то может оказаться так, что для одной части пикселов, «бегающих по кругу» в конвейере, какую-то операцию применять нужно, а для другой - нет. И это столь серьезная проблема, что графические чипы ATI долгое время не поддерживали динамические переходы (а значит, и Shader Model 2.0a и 3.0). Правда, решение nVidia очень уж красивым тоже не назовешь: в ее варианте «глупый» конвейер по кругу обрабатывает все пиксели, но в решающий момент над некоторыми из них производит операцию, а некоторые - игнорирует[Похожий способ исполнения условных переходов можно встретить в процессорах ARM]. ATI нашла гораздо лучший выход: поскольку вместо нескольких «глупых» и простых конвейеров у нее лишь один, но «умный» и сложный, то не требующие обработки пиксельные квады до исполнительных устройств просто-напросто не добираются, уступая место тем квадам, с которыми действительно нужно что-то делать. В результате конвейер хоть и исполняет по-прежнему одну и ту же операцию над разными пикселами, неторопливо перестраиваясь с одной на другую, но делает это не в пример интеллектуальнее и не разбазаривает попусту свои ресурсы. А заодно семейство Radeon X1000 получает практически «бесплатную» поддержку шейдеров третьей версии. Честно говоря, столь блестящему решению, убивающему разом целую стаю зайцев, можно только позавидовать! Это еще не унифицированная шейдерная архитектура, где единый конвейер (а вернее, набор из таковых) может обрабатывать любые шейдеры - как пиксельные, так и вершинные, но то, что полшага в ее сторону сделано, - несомненно. Вторая группа изменений коснулась оптимизации графического процессора для работы на больших и очень больших тактовых частотах. Например, архитектура подсистемы памяти была полностью переделана для поддержки казавшейся невероятно быстрой видеопамяти - 1500 МГц GDDR3[И ведь это еще не предел - ходят вполне правдоподобные слухи, что R520 поддерживает не вышедшую пока в свет графическую оперативную память следующего поколения, GDDR4]. Вместо традиционной схемы с множеством текстурных модулей (TMU), централизованно подключавшихся к единому контроллеру оперативной памяти, который, в свою очередь, по широким шинам запрашивал данные из памяти и возвращал ответ по тем же каналам связи, по которым пришел запрос, ATI изобрела принципиально новую, кольцевую внутреннюю шину видеопамяти, «размазывающую» контроллер памяти едва ли не по всему графическому процессору. Идея в том, что вместо одного большого и сложного контроллера мы делаем до восьми маленьких контроллеров, каждый из которых контролирует только свой относительно небольшой кусочек видеопамяти. Причем он расположен в кристалле так, чтобы сравнительно узкую (32-разрядную) шину видеопамяти от него было удобнее разводить на печатной плате и тем самым сводить к минимуму помехи, обычно возникающие из-за несовершенства разводки. Вдобавок, небольшим контроллерам требуются небольшие же кэши данных, что позволяет отказаться от традиционных упрощенных и имеющих ряд недостатков кэшей прямого отображения и наборно-ассоциативных кэшей в пользу более сложных, но лишенных этого недостатка полностью ассоциативных кэшей. Маленькие контроллеры (точнее, интерфейсы для подключения модулей памяти) объединяются очень быстрой внутренней двунаправленной кольцевой шиной (шириной 256 линий в каждом направлении для моделей с 256-разрядной основной шиной памяти и 128 линий - для более дешевых). На кольце имеется четыре «остановки» - точки подключения к внешних устройств. Например, для топовых R520 к каждой такой «остановке» подключено по два модуля памяти (шина памяти 2x32 разряда) и какая-то часть внутренних устройств процессора, расположенных поблизости. Каких? А неважно: какие было удобно подключить именно в этом месте, такие и подключили. Кроме того, по специальным простым управляющим шинам (по которым передаются только инструкции) каждая такая «остановка» подключена к «диспетчеру» - тому самому централизованному контроллеру памяти, который не занимается доставкой данных к исполнительным устройствам, а только «отдает распоряжения» и «присматривает» за тем, чтобы нужные данные прочитал нужный маленький контроллер и отправил их по кольцу до нужной «остановки», где их сможет снять само исполнительное устройство. В результате мы не просто добиваемся более эффективного подключения внешних модулей памяти к кристаллу - мы устраняем хорошо знакомую системным администратором проблему «звездной» топологии, когда к центральному элементу системы - контроллеру памяти (а у сетевиков - к свитчу) сходится во-о-от такой пучок проводов, работать с которым очень неудобно. Теперь у нас есть одна простая и быстрая кольцевая шина, и устройства подключены к ней «распределенно», по маленьким, коротким и простым в разводке проводникам. А где простота - там и высокие тактовые частоты. Красиво, правда? А если добавить, что упростившийся контроллер памяти в R520 стал программируемым и его можно на лету программировать так, чтобы он обеспечивал наиболее эффективное распределение данных в видеопамяти для конкретной игрушки… В общем, перед нами еще одно изящное решение из разряда «одним махом семерых побивахом». ***  Третья группа усовершенствований в R520 - это «доводка» ранее существовавших элементов. Например, этот графический процессор хранит в своих кэшах сжатые данные, сжимая и разжимая их на лету. Обычно подобный подход применяется только для хранения данных в видеопамяти (поскольку позволяет записать намного больший объем информации), а в R520 разработчики ухитрились применить тот же принцип и для самих кэшей, что почти равнозначно увеличению их объема. До восьми штук доведено число вершинных процессоров. Значительно улучшены вычислительные устройства блока пиксельных шейдеров - в них вдвое увеличено число собственно «вычислялок», поэтому за один такт это устройство способно выполнять до пяти разных операций над пикселом (две векторные над 3-векторами, две скалярные и одну операцию условного перехода). Таким образом, ATI почти догнала по этому показателю nVidia, которая использует в одном пиксельном процессоре G70 один векторный (но умеющий выполнять две разные операции одновременно) и один скалярный ALU. Правда, у nVidia векторные ALU работают с векторами длины 4, а у ATI - только с 3-векторами, и если приходится вычислять четвертую компоненту, то приходится задействовать и скалярное ALU, однако в целом заметной разницы в играх между подходами обеих компаний быть не должно. Еще сюда можно отнести улучшенную поддержку чисел с плавающей точкой, в частности - полноценную поддержку фрейм-буфера в плавающем формате (включая возможность антиалиасинга). Для чего это нужно? Экспоненциальное представление цвета более естественно для человеческого глаза и позволяет легко и качественно реализовывать сцены с очень большой контрастностью (HDR, High Dynamic Range), довольно часто возникающие в играх и реальной жизни (например, когда мы смотрим из темноты на свет, который освещает лишь небольшую часть помещения) Четвертая группа усовершенствований - «косметические» мелочи, в основном влияющие на разные «красивости». Поддержка некогда фирменного 30-битного (против обычного 24-битного) цвета Matrox, поддержка Adaptive Antialiasing - аналога Transparency SuperSampling в видеокартах nVidia9, поддержка более качественной, хотя и довольно медленной анизотропии. Аппаратное ускорение воспроизведения большинства распространенных современных видеокодеков, включая MPEG-2, WMV и H.264, позволяющее без проблем воспроизводить то, что мы называем High Definition Video (как Blu-ray, так и HD-DVD). Специальный аппаратный блок AVIVO, обеспечивающий качественную аппаратную обработку видеосигнала (10-битный цвет, гамма-коррекция, цветокоррекция, масштабирование, деинтерлейсинг); причем для кодирования TV-сигнала используется высококлассный кодер Xilleon, поддерживающий HDTV (а через переходник можно и HDMI организовать). Усовершенствованные блоки DVI и традиционная полноценная поддержка двух мониторов. В общем, грех на что-либо жаловаться. Наконец, последняя, пятая группа усовершенствований - это чисто технологические новинки. В первую очередь, конечно же, новый технологический процесс 90-нм low-k, позволивший разместить 320 млн. транзисторов (да-да, детище ATI с шестнадцатью конвейерами переплюнуло по сложности даже nVidia G70 с его двадцатью четырьмя конвейерами!) на чуть меньшей, чем у конкурента, площади ядра и сыгравший свою роль в увеличении тактовой частоты R520. Тут все очевидно и особых комментариев, думаю, не требует Практика 5 октября была анонсирована целая линейка графических ускорителей, основывающихся на новой архитектуре. Их характеристики приведены в таблице. Как видим, графические ускорители одного вроде бы семейства радикальнейшим образом отличаются друг от друга. Особенно выделяется R520 (Radeon X1800) - он просто наголову превосходит ближайшего «конкурента» новой линейки, словно это два абсолютно разных процессора! Вот она, гибкость новой архитектуры: как захотели - так и сделали. И сверхнавороченный, и скромный процессор - на основе одних и тех же подходов. Впечатляют и тактовые частоты, не опускающиеся ниже 450 МГц у ядра (у GeForce 7800 GTX, для сравнения, «всего» 430 МГц, пусть и гораздо более «полновесных», чем мегагерцы какого-нибудь X1600 XT), и оперативной памяти (1,4-1,5 ГГц - не шутки!). Правда, доступно все это великолепие будет далеко не сразу - с «высокочастотными» карточками придется подождать до ноября-декабря (да и X1800 XL на момент написания статьи в московской рознице еще не встречалась). Однако стараниями нашего замечательного редактора Х, в неравном бою отбившего нам на тестирование топовую карточку нового семейства Radeon X1800 XT, краткое «превью» новой быстродействия архитектуры мы можем сделать уже сейчас. 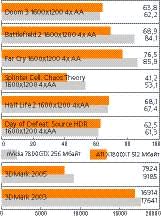 Что можно сказать про референсную карточку? Из-за внушительной двухслотовой системы охлаждения и солидной длины (как у 7800GTX и двухпроцессорных видеокарт) Radeon X1800 XT встанет не в каждый корпус и будет мешать установке других карт расширения. Но шумит он, как ни странно, довольно слабо, большую часть времени работая на пониженных оборотах (хотя и сильно греясь при этом). Дизайн платы совершенно нетипичный для ATI и больше всего напоминает… продукт nVidia - с расположением чипов памяти вокруг GPU и вынесенной на край мощной схемой питания (из-за которой плата и получилась такой длинной). Карточки младших семейств будут, естественно, скромнее по размерам и обладать уже однослотовой системой расширения. Скорость… результаты тестов говорят сами за себя: в тяжелых режимах с включенным антиалисингом и высоким разрешением в новейших играх (а для чего еще покупать такую видеокарту, как не для игры с максимальным качеством графики?) Radeon X1800 XT нигде заметно не уступает GeForce 7800GTX (1-2 fps разницы - не в счет), а некоторых игрушках - вырывается далеко вперед. Браво, ATI! Обычно революционные архитектуры поначалу страдают некоторой, гм, «тормознутостью» и не догоняют отлаженные решения предыдущих поколений, однако в данном случае, похоже, ATI удалось этого если не избежать, то по крайней мере минимизировать. Хотя и назвать это победой язык не поворачивается. Во-первых, по мере отключения «наворотов» и перехода к более простым программам и менее тяжелым графическим режимам GeForce 7800GTX уходит вперед. Во-вторых, 7800GTX поддерживает режим SLI, а X1800 XT режим CrossFire - пока нет. В-третьих, 7800GTX продается уже три месяца и успела снять сливки с рынка Hi-End-ускорителей следующего поколения; цены на ее топовые модификации быстро ползут вниз, и редким пока топовым X1000-м картам, которые поначалу будут недешевы, придется несладко. В-четвертых, как уверяют наши коллеги из других изданий, X1300 и особенно X1600, основанные на сильно урезанной архитектуре R520, в своих рыночных нишах, увы, выступают не слишком удачно. Как только сможем достать соответствующие видеокарты, мы эти утверждения обязательно проверим. Наконец, многие анонсированные видеокарты до сих пор очень трудно (или вообще невозможно) купить - довольно неприятный контраст с оперативным выходом на рынок ускорителей семейства GeForce 7800. Одним словом, карточки у ATI получились неплохие. Вот только не поздновато ли? Благодарим компанию ATI за предоставление тестового образца ATI Х1800ХТ и компанию AMD за тестовую платформу на Athlon 64 FX-57. |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||