|
||||
|
|
Глава четвертая. АВТОМАТИЗАЦИЯ ПРАВДОПОДОБНЫХ РАССУЖДЕНИЙ (С.А. Стебаков)Я гнет бездарности тащу От Аристотеля до Бэкона Аристотель упоминал о двух основных процессах рассуждений: нисходящем или дедуктивном и восходящем или индуктивном. Иногда говорят, что дедукция – это рассуждение «от общего к частному», а индукция – «от частного к общему». При таком понимании этих двух процессов возникает иллюзия, что они как будто обратны друг другу и одну схему рассуждений можно получить из другой прямым обращением. Этой иллюзии поддался и Аристотель. Увлеченный красотой и стройностью воздвигнутого им здания силлогистики, он попытался втиснуть в его объемы и индуктивное рассуждение, ввести схему индуктивного силлогизма. Но здесь его подстерегала неудача. Индуктивные рассуждения никак не хотели отливаться в ту стройную форму, которая так подошла дедуктивным рассуждениям. Попытки адептов учения Аристотеля исправить, уточнить, расширить понятие индуктивного силлогизма остались тщетными. В основе различия дедукции и индукции лежало нечто более существенное, чем думали мыслители, не желавшие выходить за рамки мира, очерченного рукой гениального Аристотеля. Напомним еще раз основную цель, которую преследовал Аристотель, создавая силлогистику. Она должна была стать непобедимым оружием в споре. Если оппонент признавал общее положение, относящееся к классу однородных объектов или явлений (а как он мог не признать, например, столь очевидную истину, что «Все люди смертны»), и принадлежность какого-либо объекта или явления к этому классу (например, что «Сократ есть человек»), то ему ничего не оставалось сделать, как признать, что общий для всего класса признак переносится и на отдельный элемент этого класса. Возражать против такого хода рассуждений мог бы только человек, спорить с которым не имеет никакого смысла, ибо он отвергает очевидное. Если бы аналогичная цель стояла перед спорящим, который пользуется методом индукции, то схема его рассуждений должна была быть следующей. Сначала он мог бы сообщить оппоненту несколько утверждений об отдельных представителях класса, в существование которого должны верить оба спорящих. Каждое такое утверждение должно касаться одного и того же признака, связанного с элементами этого класса (например, оппоненту надо было сообщить, что «Гомер смертен», «Фидий смертен», «Эзоп смертен», и добиться от оппонента признания правильности этих утверждений). После этого надо было прийти с противником к согласию, что все эти элементы принадлежат одному классу (в нашем примере, что Гомер, Фидий и Эзоп являются людьми). Далее нужно было совершить главный индуктивный шаг, перейти к утверждению о классе (т.е. ввести утверждение «Все люди смертны») и заставить противника принять это утверждение. Трудность таится именно на последнем шаге спора. Примет или не примет этот шаг оппонент, зависит от степени его уверенности в правильности данного шага. Этот шаг требует не умения логически обосновывать свои действия и рассуждения, а веры в свою справедливость. Можно ли от трех конкретных утверждений о Гомере, Фидии и Эзопе перейти к общему утверждению о всех людях? Ответ на этот вопрос не снимается, если мы к названным трем великим представителям греческой культуры добавим еще кого-нибудь. Где граница, после которой индуктивный шаг станет оправданным? Ответа на этот вопрос нет и быть не может. Именно поэтому индуктивное умозаключение всегда является правдоподобным рассуждением. Его надо принимать на веру. И обсуждать можно только то, как оценить обоснованность этой веры, т.е. как оценить степень правдоподобности выведенного утверждения. Мы получили весьма важный вывод о том, что каждое правдоподобное утверждение А должно сопровождаться некоторой оценкой правдоподобности (достоверности) Q(A). Интерпретация Q(A) может быть различной. Некоторые из них, сейчас наиболее распространенные, будут обсуждены в последующих разделах этой главы. Подчеркнем еще раз принципиальное различие между дедуктивной и индуктивной схемами рассуждений. Если посылки в дедуктивной схеме выбраны правильно, являются истинными, то получаемые с их помощью заключения не могут быть ложными. Если они нас чем-то настораживают, вызывают недоумение, то надо еще раз проверить истинность посылок. Убедившись в их правоте, ничего не остается делать, как полностью принять следующие из них выводы. Если посылки в индуктивной схеме выбраны правильно, являются истинными, то получаемые с их помощью заключения могут быть как истинными, так и ложными. Та или иная точка зрения на заключения зависит от степени субъективной уверенности в достаточности посылок для получения заключения. Именно поэтому вместо оценки истинности или ложности заключения в правдоподобных рассуждениях используется оценка правдоподобности (или истинности) Q(A). Известный специалист по психологии восприятия Р. Грегори писал:
Таким образом, индукция тесно связана с восприятием, опытом. Когда в развитии научного мировоззрения возник этап понимания, что опытные данные, эксперимент, реальная деятельность по достижении определенных целей служат единственным мерилом обоснования научных построений, тогда наступила пора индукции. Понимание роли индуктивных рассуждений в научном познании связано с именем двух людей, носивших одинаковую фамилию. Один из них, Роджер Бэкон, был францисканским монахом и выдающимся мыслителем. С целью прославления церкви и воплощения своей мечты о том, что католическая церковь должна царить над всем миром, этот монах в 1265 году посвятил папе Клименту IV свою работу, где сделал набросок новой экспериментальной науки, которая должна была дать в руки человечества инструмент к познанию природы и роли высшего разума в ее существовании. Только через опыт возможно постижение истины – к такому выводу пришел Роджер Бэкон. И, критикуя метод Аристотеля, он писал: «Было бы лучше сжечь сочинения Аристотеля и начать все сызнова, нежели принимать его заключения без проверки». Но францисканец поспешил. В XIII веке схоластическая наука еще не собиралась сдавать свои позиции. Аристотель считался вершиной научной мысли. И надо было дожидаться XVII века, когда человек, обладавший большой политической властью и непревзойденным красноречием, лорд Веруламский Фрэнсис Бэкон опубликует свой труд под красноречивым и недвусмысленным названием Novum Organum[7]. В этой работе философ обратил внимание ученых на важность экспериментального метода в науке. Мысль о том, что всякое научное положение, полученное в теории, должно подтверждаться практикой, сформулирована им четко и исчерпывающе. Фрэнсису Бэкону повезло куда больше, чем его однофамильцу. Он высказал свои мысли в нужное время, когда экспериментальная наука начала победное шествие по миру. И за это он стал признанным отцом нового направления в научном познании. Но если внимательно разобраться в сочинениях Фрэнсиса Бэкона, то в них вряд ли удастся обнаружить пропагандируемый им метод индуктивного развития науки. Ничего подобного силлогистике Аристотеля у него нет. А поэтому вплоть до середины XIX века в области индуктивных рассуждений ничего не менялось. Их теории просто не существовало. Индукция Джона Стюарта Милля В процессе наблюдения за окружающим миром мы решаем две главные задачи, связанные с созданием модели, его описывающей. Прежде всего мы выделяем в наблюдаемом некоторые сущности. В логике им соответствуют некоторые понятия. А кроме того, мы устанавливаем между этими понятиями определенные отношения. Эти отношения могут быть как наблюдаемыми непосредственно с помощью наших органов чувств (например, отношения типа «субъект-действие» или «быть раньше»), так и достраиваемыми на основании некоторой «логики знаний» (например, отношения типа «причина – следствие» или «цель – средство»). Среди всех этих отношений едва ли не главнейшую роль для познания окружающего мира играют каузальные отношения, отражающие в наиболее общей форме связи причин и следствий. Подробный разговор о каузальных связях мы отложим до конца этой главы. А пока поговорим лишь о том их виде, внимание к которому привлекли исследования английского логика середины XIX века Джона Стюарта Милля. Он поставил перед собой задачу нахождения связей между фактами и явлениями на основе анализа их совместного появления или непоявления в последовательности экспериментов. При этом он принял меры к тому, чтобы не повторять знаменитой ошибки при установлении причинно-следственных связей, которая вошла в историю науки под названием Post hoc ergo propter hoc, т.е. «После этого, значит вследствие этого». А ошибки такого типа не только встречались и встречаются в бытовых человеческих рассуждениях до сих пор, но иногда подобные выводы делаются сознательно, например, для создания неожиданных поэтических образов. Вот как превосходно использовал этот прием В. Луговской: «Речные девки в речках мочут косы, и над Русью от этого подъемлется туман». Принципы установления причинно-следственных отношений, которые предложил Милль, основываются на идеях выделения сходства и различия в наблюдаемых ситуациях внешнего мира. Способность улавливать сходство и выделять различия – фундаментальная способность, по-видимому, всех живых существ. Опираясь на эту способность, Милль сформулировал свои принципы индукции. Первым из них является Принцип единственного различия. В формулировке, которая дана в известном учебнике логики В. Минто, он звучит следующим образом: «Если после введения какого-либо фактора появляется, или после удаления его исчезает, известное явление, причем мы не вводим и не удаляем никакого другого обстоятельства, которое могло бы иметь в данном случае влияние, и не производим никакого изменения среди первоначальных условий явления, то указанный фактор и составляет причину явления». Схематически этот принцип можно описать в виде следующей схемы: 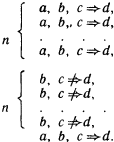 Здесь знак Второй основополагающий принцип индуктивного рассуждения Милля носит название Принципа единственного сходства. В формулировке того же В. Минто он звучит следующим образом: «Если все обстоятельства явления, кроме одного, могут отсутствовать, не уничтожая этим явления, то это одно обстоятельство находится в отношении причинной связи с явлением при условии, что приняты были все меры к тому, чтобы никаких других обстоятельств, кроме принятых во внимание, налицо не оказалось». Схематическое представление этого принципа Милля выглядит следующим образом:  В этой схеме все примеры являются положительными. Из нее по Принципу единственного сходства вытекает, что a и d связаны причинно-следственным отношением. Еще один принцип Милля – Принцип единственного остатка. Он формулируется В. Минто следующим образом: «Если вычесть из какого-либо явления ту часть его, которая согласно прежним исследованиям оказывается следствием известных причин, присутствующих в явлении причин, то остаток явления есть следствие остальных причин». Принцип единственного остатка можно проиллюстрировать следующей схемой: 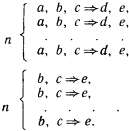 Следовательно, a и d связаны причинно-следственным отношением, а b и с являются возможными причинами е. Для дальнейшего уточнения зависимости надо посмотреть, приводит ли исключение b к появлению e. Если приводит, то отношением «причина – следствие» связаны между собой с и е. В противном случае это отношение имеется между b и е. Отметим ряд особенностей схем Милля. Прежде всего, они справедливы лишь при условии, что в описании ситуации имеется полное множество наблюдаемых фактов или явлений. Например, в последнем случае может оказаться, что и исключение b, и исключение с не влияют на появление е. Тогда можно предположить, что для появления е необходимо либо одновременное наличие b и с, либо е вызывается чем-то, не вошедшим в описание ситуации. Другими словами, появление некоторого элемента ситуации может определяться не отдельными факторами или элементами, а их совокупностью, задаваемой с помощью сложного логического выражения. В левой части причинно-следственного отношения может стоять сложное выражение, в котором отдельные элементы могут быть связаны между собой конъюнктивными и (или) дизъюнктивными связками. Проиллюстрируем это на следующих примерах. В качестве первого примера рассмотрим ситуации, показанные на рис. 20. С ними связана следующая история. Когда некий человек встречает на улице необычных зверюшек, то, глядя на них, он или радуется, или печалится. Нас интересует, какие качества зверюшек приводят человека в хорошее расположение духа. Другими словами, что является причиной его улыбки. Для удобства ответа на этот вопрос на рис. 20 положительные примеры и контрпримеры разделены штриховой чертой. 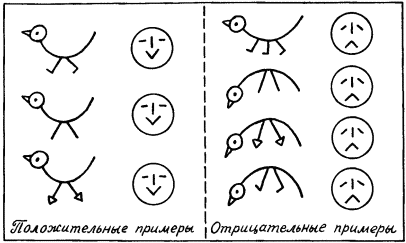 Рис. 20. Как видно из рисунка, зверюшки обладают тремя признаками: формой спины, числом ног и формой ног. Что же вызывает улыбку? Используем метод Милля. Возьмем в качестве первой возможной причины форму спины у зверюшки. Положительные примеры таковы, что во всех наблюдаемых случаях эта форма выгнута вниз. Обозначим этот признак через a, а реакцию человека, когда он радуется, через d. Можно ли утверждать, что а есть причина d? Согласно Принципу единственного сходства наличие спины такой формы должно всегда вызывать улыбку. Но первый же контрпример опровергает это. Число ног (обозначим этот признак как b) также не может быть причиной улыбки. В положительных примерах b везде равно двум, и можно подумать, что именно две ноги зверюшки веселят человека. Но в трех контрпримерах ног тоже две. С формой ног (этот признак обозначим как с) ситуация в положительных примерах такова, что сразу ясно, что с не может быть причиной d. Таким образом, ни один из признаков зверюшки по отдельности не может быть причиной улыбки человека. Попробуем выделить общее ядро сходства у всех зверюшек в положительных примерах. Такое ядро есть. Все зверюшки в этих примерах имеют выгнутую вниз спину и две ноги. Другими словами, для них всегда истинно утверждение Р1(а)&Р2(b), в котором Р1(а) – предикат, интерпретируемый как «форма спины, выгнутая вниз», а Р2(b) – предикат, интерпретируемый как «число ног равно двум». Проверим, будет ли истинным выделенное ядро в отрицательных примерах. Простой проверкой убеждаемся, что оно везде ложно. Таким образом, причина улыбки человека найдена. Она возникает тогда и только тогда, когда встреченная им зверюшка имеет выгнутую вниз спину и две ноги. Приведенный пример показывает, что при использовании методов индуктивных рассуждений, которые предложил Милль, весьма важную роль играет способ выделения признаков или фактов, с помощью которых описываются ситуации. Еще один пример связан с ситуациями, показанными на рис. 21. Теперь нас беспокоит реакция зверюшки на тех людей, которых она встречает на улице. У зверюшки хорошее настроение, когда она встречает людей с выражением на лице, как в положительных примерах. И ее настроение становится плохим, когда ей встречаются люди с такими лицами, как на отрицательных примерах. Возникает вопрос о причине появления у зверюшки хорошего настроения при встрече с людьми. Три элемента лица: рот, нос и глаза, полностью характеризуют выражение человеческого лица. Будем обозначать эти признаки как е, ? и g, а реакцию зверюшки как h. Поскольку все признаки принимают только два значения, как и реакция зверюшки, то можно (это можно было сделать и в предыдущем примере, но было желание продемонстрировать общий подход, использующий запись в виде предикатных формул) обойтись формулами исчисления высказываний. Будем считать, что е, ? и g истинны, если они соответствуют типу рта, носа и глаз человека из первого положительного примера. Будем также считать истинным значение h, соответствующее зверюшке с хорошим настроением. Если выделить ядро сходства у положительных примеров, то оно окажется пустым. Это свидетельствует о том, что причиной хорошего настроения зверюшки не может быть просто конъюнкция каких-то признаков человеческого лица. Выражение причины через признаки должно использовать дизъюнкцию. 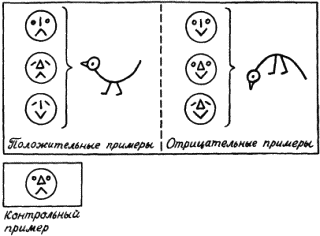 Рис. 21. В этом случае надо попытаться найти частные ядра сходства и попробовать объединить их в причину через операцию дизъюнкции. Выделим все попарные общие признаки у лиц, входящих в положительные примеры. Первое и второе лицо имеют общую часть е, первое и третье – ?, а второе и третье – Для того чтобы учесть третий пример, надо построить общее ядро различия для него и лиц, входящих в отрицательные примеры. Сразу видно, что форма рта тут не поможет. Остаются нос и глаза. Нос и глаза такой формы, как в третьем положительном примере, можно по отдельности найти в отрицательных примерах. Но их комбинация, характерная для третьего положительного примера (при принятых нами обозначениях эта комбинация описывается формулой ?& Попробуем теперь найти причину, когда зверюшка бывает в плохом настроении. Обратимся для этого к отрицательным примерам и попробуем на них выделить общее ядро сходства. Оно легко обнаруживается. Это Если составить таблицу, в которой перечислены все комбинации истины и лжи для е, ? и g, и определить истинность h и h’, то можно убедиться, что h’= Такая ситуация не является стопроцентной. На рис. 22 мы снова встречаемся с известной нам зверюшкой. Но здесь выражения для h и h’, легко вычисляемые с помощью общих ядер сходства, имеют вид h=e& Чем различаются два рассмотренных случая? Пусть на пути нашей зверюшки встретился человек с лицом, обведённым на рис. 21 и 22 в рамочку. Как среагирует на него зверюшка? В случае, показанном на рис. 21, она тут же перейдет в хорошее настроение, ибо h истинно, а h’, естественно, ложно. Но в случае, соответствующем рис. 22, ситуация для зверюшки становится весьма сложной. Для встретившегося ей персонажа h и h’ одновременно ложны. Возникает конфликт. Новый персонаж не укладывается в ту классификацию, которая была построена по положительным и отрицательным примерам. Конфликт для зверюшки неразрешим. 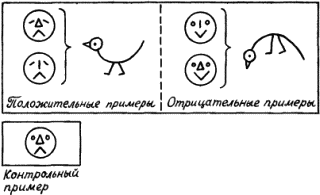 Рис. 22. Его можно разрешить лишь волевым усилием. Надо включить новый персонаж в число либо положительных, либо отрицательных примеров. В реалии разбиение чего-либо на классы (в наших случаях на два класса) вытекает из каких-то прагматических требований. Например, все люди, отнесенные к положительным примерам, относятся к зверюшке доброжелательно. Их не нужно опасаться. А люди, относимые к группе отрицательных примеров, таковы, что лучше обойти их стороной. От них ждать добра не приходится. Тогда волевое отнесение нового персонажа к той или иной категории должно получить практическое подтверждение своей правильности или неправильности. Если встреча с ним для зверюшки окажется благоприятной, то его, конечно, надо относить к положительным примерам. В противном случае его место среди отрицательных примеров. Мы продемонстрировали весьма важное положение, связанное с процессом индуктивного обобщения. Если h и h’ классифицируют множества положительных и отрицательных примеров, так что h= Пусть, например, мы снова имеем классификацию, которая соответствует ситуациям, показанным на рис. 21. Но контрольный пример поступает в систему с указанием, что он относится к группе отрицательных примеров. А система в соответствии с ранее построенной классификацией относит его к положительному классу. В таком случае необходимо внести коррективы в классификацию, полученную ранее, выработать новую классификацию с учетом нового множества отрицательных примеров. Вывод из этого только один. Поскольку множества положительных и отрицательных примеров не охватывают всех возможных случаев, то h и h’, построенные по методам Милля, даже в тех случаях, когда h= Рассуждения по аналогии Начнем с задачи. Посмотрим на первую строку, показанную на рис. 23. В этой строке представлено преобразование F, с помощью которого пара слов, стоящая слева от стрелки, преобразуется в слово, стоящее от нее справа. Можно ли угадать, во что превратится пара слов, стоящих во второй строке на этом рисунке, если считать, что преобразование F’ максимально похоже на преобразование F? Для ответа на этот вопрос надо сначала понять, какова суть F. После недолгого размышления можно прийти к выводу, что слово, получаемое в результате преобразования, устроено следующим образом: первая его половина совпадает с первой половиной первого слова в исходной паре, а вторая его половина получается из первой половины второго слова в исходной паре, если в ней сделать перестановку букв. Если мы верим, что F именно таково (еще раз обратим внимание на этот постулат веры), то можно попытаться придать F’ тот же смысл. Тогда вместо знака вопроса в правой части второй строки можно написать результат преобразования. Им будет слово «плен». Если считать, что F’’ – преобразование, аналогичное F и F’, то вполне законным будет получение правой части по паре левых и в третьей строке на этом рисунке. 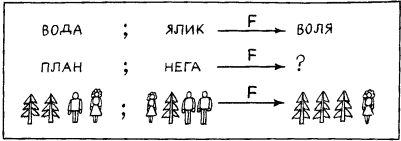 Рис. 23. Какой смысл мы вложили в слово «аналогичное», когда говорили о преобразованиях? По крайней мере, двоякий. Во-первых, мы предположили, что элементы, из которых состоят слова и рисунки, как-то соответствуют друг другу. Например, елочки и фигурки из третьей строки ассоциируются у нас с буквами, из которых состоят слова, а буквы важны не сами по себе, а по тому месту, которое они занимают в словах. Во-вторых, мы предполагаем, что сохраняется суть преобразования, хотя элементы, с которыми преобразование оперирует, могут быть другими. Эти соображения помогают уловить расплывчатый смысл, вкладываемый людьми в понятие аналогии. На рис. 24 показано три преобразования для треугольника Т. Преобразование 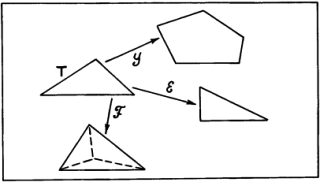 Рис. 24. Первая попытка формализовать понятие рассуждения по аналогии была предпринята Лейбницем. В своем сочинении «Фрагменты логики» он ввел понятие пропорции для отношения аналогии. Пропорция Лейбница формулируется следующим образом: «Вещь А так относится к вещи В, как вещь А’ к вещи В’». Обычно пропорцию Лейбница представляют в виде диаграммы: 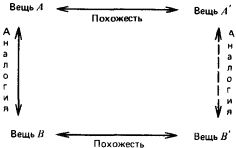 Для иллюстрации того, как может быть использована диаграмма Лейбница, рассмотрим семантическое пространство Осгуда. Это пространство, которое американский психолог Чарльз Осгуд строил экспериментально, проводя опыты с людьми, должно было, по его мнению, характеризовать организацию размещения информации в памяти человека. Мы не будем здесь останавливаться на способе его построения. В комментарии к данному разделу имеется некоторая информация по этому вопросу, а в библиографии заинтересовавшиеся читатели могут найти нужные работы. Скажем только, что упрощенное пространство Осгуда является обычным трехмерным евклидовым пространством. Близость по метрике этого пространства характеризует семантическую близость понятий, фактов и утверждений, а рассуждения, проведенные в пространстве относительно группы элементов, могут проецироваться по аналогии на группы, состоящие из семантически близких элементов. Проиллюстрируем эту мысль, взяв «кусок» пространства Осгуда, относящийся к понятиям, используемым для указания родства. То, что они в семантическом пространстве расположены компактно, было доказано экспериментально. Этот «кусок» пространства Осгуда показан на рис. 25. Для удобства введена система координат и сделано такое преобразование, чтобы все точки, соответствующие интересующим нас понятиям, оказались лежащими в вершинах единичного куба (правомочность такого преобразования в пространстве Осгуда мы тут не обсуждаем). 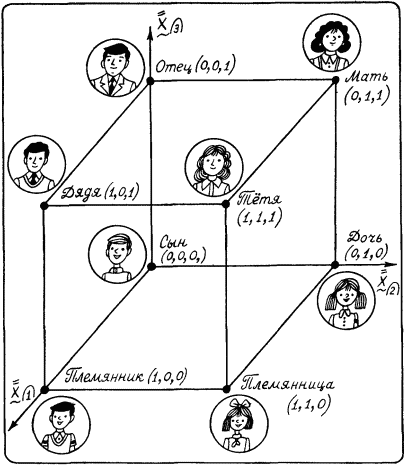 Рис. 25. Пусть даны три элемента пропорции Лейбница А, А’ и В. И необходимо узнать элемент В’. Для рассматриваемого примера примем следующий способ нахождения координат понятия В’: b’i=bi+а’i–аi где i=1,2,3. Пусть, например, нас интересует пропорция Сын:Дочь=Дядя:? Для определения неизвестного члена пропорции произведем необходимые вычисления, используя координаты понятий, отмеченные на рис. 25. Получим b’1=0+1–0=1; b’2=1+0–0=1; b’3=0+1–0=1. Таким образом, понятие В’ имеет координаты (1,1,1). Этим координатам соответствует понятие «Тетя». Для дальнейшего необходимо уточнить понятия «похожесть» и «аналогия», использованные в диаграмме для пропорции Лейбница, и придать им по возможности строгий смысл. Сделать это можно следующим образом. Выберем некоторый алгебраический язык для описания A и В, который обозначим Чтобы все сказанное стало понятнее, рассмотрим конкретный пример. На рис. 26 показана серия изображений, соответствующая пропорции Лейбница, в которой, как всегда, надо восстановить недостающее звено, т.е. осуществить (если это возможно) вывод по аналогии. Для описания изображений введем языки  Рис. 26. Введем теперь элементы языка Рассмотренная процедура носит общий характер. Можно строго доказать, что если в пропорции Лейбница А, А’ и В описаны с помощью алгебраического языка, использующего лишь двуместные отношения, задан характер преобразований F и установлено взаимно однозначное соответствие между Заметим, что из этого утверждения вытекает, что необходимым условием для возможности рассуждений по аналогии с использованием пропорции Лейбница служит требование коммутативности ее диаграммы. Требование коммутативности диаграммы означает, что описание В’, полученное из A с помощью F и взаимно однозначного соответствия H’, ничем не отличается от описания В’, полученного из A с помощью взаимно однозначного соответствия H и последующего применения к этому результату преобразования F’. С требованием коммутативности диаграмм мы еще столкнемся в последующих разделах этой главы. Несмотря на все сказанное, полное описание модели рассуждений по аналогии всё еще не получено, так как пропорция Лейбница явно не исчерпывает всех случаев рассуждений подобного типа. Да и в случае, когда мы имеем дело действительно с пропорцией Лейбница, остаются нерешенными по крайней мере два вопроса: как построить языки  Рис. 27. Готовы ли мы признать описанные две ситуации аналогичными? И должен ли Тристан действовать так же, как Ромео? Из соответствующих литературных произведений мы знаем, что развитие ситуации А было таково, что оно привело к совместной смерти Ромео и Джульетты. А Тристан и Изольда имели другую судьбу. Почему это произошло? И можно было бы это формально установить в процессе сравнения ситуаций А и А’? Ведь во второй ситуации имелся король Марк, а различное число отношений заведомо не позволяло установить взаимно однозначное отношение между их описаниями. Но может быть вместо изоморфизма (т.е. взаимно однозначного отношения) для Этот вопрос пока остается без ответа. Поэтому ограничимся лишь тем, что для рассуждений по аналогии можно считать твердо установленным. В следующем разделе попытаемся объединить то, что нам уже известно об индуктивном методе Милля и рассуждениях по аналогии. ДСМ-метод Сокращение ДСМ, вынесенное в название метода, означает Джон Стюарт Милль. Оно показывает, что метод поиска закономерностей по множествам положительных и отрицательных примеров, к описанию которого мы переходим, опирается на методы индукции, предложенные этим ученым. Их реализация в виде комплекса действующих программ на ЭВМ выполнена современными исследователями. Введем три множества: причин А={а1,а2,…,аp}, следствий B={b1,b2,…,bm} и оценок Q={q1,q2,…,ql}. Выражение вида аi Пусть мы вдруг оказались в стране, где до этого нам не приходилось бывать. Выйдя из гостиницы, мы увидели, что у подъезда стоит такси, выкрашенное в ярко-желтый цвет. Через некоторое время рядом останавливается еще одно такси такого же цвета. В нашей голове возникает положительная гипотеза вида «В этой стране, если автомобиль выполняет роль такси, то цвет его будет желтым». Оценка достоверности этой гипотезы при двух наблюдениях будет невелика. Но если во время прогулки по улицам города мы увидим, что такси окрашены в тот же желтый цвет, то оценка выдвинутой при выходе из гостиницы гипотезы будет все время возрастать. Станет ли она когда-нибудь равной единице? Если после недельного пребывания в стране наша гипотеза будет подтверждаться лишь положительными примерами, то на родине, рассказывая знакомым и друзьям о своих впечатлениях, связанных с поездкой, мы вполне можем заявить: «А такси у них покрашены в ярко-желтый цвет, что очень удобно – сразу можно найти его, когда нужно». Значит ли это, что гипотеза о цвете такси приобрела оценку достоверности, равную 1? Можно ввести два типа истинности: эмпирическую истину и теоретическую истину. В нашем примере высказыванию о цвете такси мы, конечно, приписываем эмпирическую истину. Просто все наши наблюдения были в пользу данной гипотезы. Но мы вполне можем допустить, что есть небольшое количество такси иного цвета. Они ни разу не попадались нам на глаза. Совсем другое положение будет в том случае, когда в путеводителе, обнаруженном в гостинице, будет сказано, что закон данной страны запрещает окрашивать такси в какие-либо другие цвета, кроме желтого. При такой информации высказывание о желтом цвете такси будет оценено как теоретическая истина. На этом простом примере видна разница между дедуктивным и индуктивным умозаключением. При использовании информации из путеводителя о цвете такси вы уже не нуждаетесь в эксперименте. Полученное знание носит общий характер. В каждом конкретном случае (например, при поиске такси) его можно механически применять, фиксируя цвета проходящих машин. Никакого нового знания при решении конкретных задач, связанного с цветом такси, получить нельзя. При получении же информации из наблюдений формируется новое знание, которого раньше не было. Гипотеза о цвете такси в данной стране – это новая информация. Таким образом, индуктивное рассуждение способно порождать новые знания. В этом смысле оно куда более «интеллектуально», чем дедуктивное рассуждение. Достижение эмпирической истины (а только такая истина и возможна при индуктивных рассуждениях) вполне возможно. Для этого достаточно некоторого множества положительных примеров при полном отсутствии отрицательных примеров, опровергающих выдвинутую гипотезу. А число необходимых положительных примеров, необходимых для того, чтобы считать гипотезу эмпирически истинной, может быть разным в различных обстоятельствах и у разных людей. Недаром же все представители рода человеческого делятся на тех, кто готов верить в нечто всего по одному примеру, и тех, кто подобно евангельскому Фоме никогда не может уверовать до конца даже в самые очевидные для остальных истины. Рассмотренный пример иллюстрирует процесс оценивания степени достоверности гипотезы, когда предполагаемая причина (в нашем случае – принадлежность автомашины к множеству такси) уже выделена из множества возможных причин. В ДСМ-методе формализован не только этот этап, но и предшествующий ему этап нахождения кандидата в причины, которая могла бы вызвать интересующее нас следствие. В примере это соответствовало бы следующему. Наблюдая на улицах города потоки автотранспорта и выделяя среди автомашин ярко-желтые, надо «сообразить», что желтыми являются только такси. Причины могут быть различными по типу. Наиболее редкими являются необходимые и достаточные причины. Если аi – причина такого типа, то bj происходит всегда, и если bj произошло, то наверняка было аi. Примерами такой «жесткой» связи двух явлений может служить падение тела, если для него отсутствует опора. Чаще встречаются достаточные причины, всегда вызывающие появление bj. Но появление bj не служит стопроцентным обоснованием того, что до этого было аi. Следствие bj могло быть вызвано и какими-то другими достаточными причинами. Если, например, ваш друг не пришел в условленное место и в условленное время на свидание, то, возможно, он заболел, ибо болезнь – достаточная причина для отказа от свидания, но весьма вероятно, что были какие-то другие причины нарушения им своего обещания. Дополнительные причины обладают тем свойством, что их наличие не вызывает следствия bj. Для того чтобы bj появилось, нужен вполне определенный набор дополнительных причин, который выступает в роли обобщенной достаточной причины появления bj. Легко себе представить такой набор причин, который приводит к попаданию мяча в сетку ворот при игре в футбол. Перечисление и обсуждение дополнительных причин, приведших к голу, – знакомое занятие для каждого истинного любителя футбола. Среди дополнительных причин могут быть необходимые дополнительные причины. Их вхождение в набор, образующий обобщенную достаточную причину, обязательно для того, чтобы bj реализовалось. Остальные дополнительные причины можно назвать факультативными. В окончательный набор могут входить те или иные комбинации факультативных причин. Так, в ситуации забивания гола две дополнительные причины являются заведомо необходимыми: удар, посылающий мяч в ворота, и ошибка вратаря. Остальные дополнительные причины являются факультативными. Наконец, возможные причины аi обладают тем свойством, что появление аi необязательно вызывает bj, но увеличивает возможность появления bj. Кроме причин аi важную роль в процессах реализации причинно-следственных зависимостей играют так называемые тормоза. Наличие тормоза наряду с причиной, вызывающей bj в обычных условиях, приводит к тому, что bj не появляется. Так, принятие смертельной дозы яда не приводит к ожидаемому исходу, если до этого было принято противоядие. Вернемся к ДСМ-методу. После сказанного становится ясным, что нахождение причин – кандидатов для формируемых гипотез – дело далеко не простое. В положительных и отрицательных примерах эти причины скрыты в описаниях реальных объектов, обладающих или не обладающих интересующими нас свойствами. Из этих описаний надо выделить кандидатов в причины, а затем убедиться, что выбор оказался не случайным. При первом реальном использовании ДСМ-метода одной из конкретных задач была задача нахождения причин того, что некоторое органическое химическое соединение будет обладать свойством биологической активности. Постулировалась, что информация о причинах биологической активности скрыта в структурной формуле того или иного соединения. Какие-то особенности этих формул оказывали влияние на интересующее исследователей свойство. Экспериментально для многих соединений было установлено наличие или отсутствие в них биологической активности. Эти экспериментальные факты составляли множество положительных и отрицательных примеров. На основании их программы, реализующие ДСМ-метод, должны были найти новые, не известные химикам и фармакологам закономерности, позволяющие без экспериментальной проверки (весьма дорогой и длительной) оценивать возможность того, что вновь синтезированное вещество будет обладать биологической активностью. Суть того, как это делалось с помощью ДСМ-метода, состоит в следующем. Рассмотрим группу положительных примеров. Находим некоторую часть описания объектов, общую для определенной совокупности примеров из этой группы. Например, обнаруживаем в значительной части структурных формул соединений, обладающих свойством биологической активности, кольцевую структуру с фиксированным заполнением позиций в этой структуре. Тогда есть основания считать ее кандидатом в причины. Таких кандидатов может оказаться несколько. Образуем матрицу М+, в которой строки соответствуют выделенным кандидатам аi, а столбцы – интересующим нас следствиям bj (при одном интересующем нас следствии в М+будет один столбец). На пересечении строк и столбцов будем записывать оценки достоверности qk гипотез hi+jk. Об их нахождении будет сказано ниже. Для множества отрицательных примеров аналогичным образом строится другая матрица М–, в которой содержатся оценки достоверности отрицательных гипотез hi–jk. Кандидаты в причины в матрицах М+и М?могут частично совпадать, так как положительные и отрицательные примеры не образуют полной выборки из всего множества возможных примеров. На каждом шаге работы ДСМ-метода используются новые наблюдения, пополняющие множества положительных и отрицательных примеров. Эти новые наблюдения могут либо подтверждать сформированные гипотезы hi+jk и hi–jk либо противоречить им. В первом случае надо увеличивать оценки достоверности соответствующих гипотез, а во втором – уменьшать их. Механизм изменения оценок qk может быть различным. В ДСМ-методе он устроен следующим образом. Значение n совпадает с числом имеющихся в данный момент положительных или отрицательных примеров. Таким образом, для М+и М–значение n может оказаться различным. С ростом n растет «дробность» оценок достоверности. Оценка 1/n играет особую роль. Она соответствует полному незнанию о достоверности гипотезы. Поэтому в начальный момент М+и М–заполнены лишь нулями, единицами и оценками 1/n. Значения истинности и лжи могут иметь гипотезы, у которых в качестве причин даны полные описания объектов, образующих множества примеров. Если некоторая положительная или отрицательная гипотеза hijk имела оценку k/n, то при появлении нового примера (n заменяется на n+1) проверяется, подтверждает или не подтверждает новый пример эту гипотезу. При подтверждении оценка k/n заменяется на (k+1)/(n+1), а при неподтверждении новым примером ранее выдвинутой гипотезы ее оценка меняется с k/n на (k–1)/(n+1). Таким образом, в процессе накопления новой информации оценки гипотез либо приближаются к 0 или 1, либо ведут себя каким-либо «колеблющимся» образом. В первом случае гипотеза может на некотором шаге (когда будет пройден некоторый априорно заданный нижний порог достоверности) исчезнуть из М+или М–. Во втором случае при достижении некоторого верхнего порога достоверности гипотеза может получить оценку, отражающую эмпирическую истину, и запомниться как некий установленный факт в системе или эта гипотеза сообщается человеку, работающему с ДСМ-программами. В третьем случае, если колебания оценок достаточно сильны, может также произойти исключение сформированной ранее гипотезы из тех, которые описаны в М+и М?. Новые гипотезы формируются не только на основании выделения в примерах определенного сходства (общей части в описании). Они могут использовать и метод различия, также сформулированный Миллем. Различие выявляется для примеров, относящихся к группам положительных и отрицательных примеров. Найденное различие служит кандидатом для гипотез, включаемых в М+или М–. Кроме выявления кандидатов в причины аi для положительных и отрицательных гипотез в описываемом методе ищутся также тормоза, наличие которых снимает влияние аi на появление bj. В новых версиях метода в качестве аi выступают весьма сложные утверждения, в которых отдельные части описаний объектов могут быть связаны между собой произвольными логическими выражениями, например, следующего типа: «Если в объекте есть а’ и а’’ и нет а’’’ или в объекте есть а’’’’, то свойство b имеет место». Как уже было сказано, в ДСМ-методе кроме прямой реализации идей Милля используются еще некоторые выводы по аналогии. Для этого на множестве описаний объектов вводится тем или иным способом понятие сходства. Если, например, речь идет о структурных формулах химических соединений, то мерой сходства для них могут быть совпадение самих структур при различных заполнителях позиций или, наоборот, наличие в некоторых фиксированных позициях структур одинаковых элементов. Если установлено отношение сходства, то в ДСМ-методе происходит вывод по аналогии. Он осуществляется следующим способом. Если гипотеза hijk имеет оценку k/n и такова, что причина, используемая в ней, сходна с причиной в гипотезе h’ijk, имеющейся в той же матрице М и оцениваемой с точки зрения достоверности значением 1/n, то на гипотезу h’ijk переносится оценка гипотезы hijk и она получает оценку достоверности k/n. Подобная процедура в ДСМ-методе называется правилом положительной аналогии. Существует в этом методе и правило отрицательной аналогии, а также градация тех и других правил по силе учитывающегося в них сходства. Таким образом, ДСМ-метод демонстрирует возможность проведения правдоподобных рассуждений весьма широкого спектра. Нечеткий вывод Ранее мы говорили о кванторах общности и существования в исчислении предикатов и о близких к ним по смыслу кванторах в силлогистике Аристотеля. Эти кванторы – не единственные. Могут встречаться и более сложные указатели. И как раз их-то чаще всего используют в своих рассуждениях люди. Эти кванторы в отличие от классических кванторов будем называть квантификаторами. Вот, например, квантификатор «только». Какова его роль в наших рассуждениях? Если кто-то говорит: «Маша из всех каш ест только гречневую», то квантификатор «только» выделяет из множества сущностей с именем «каши» одну определенную сущность. В этом случае рассматриваемый квантификатор играет роль выделителя определенной группы элементов. В другом утверждении «Только тропические страны пригодны для возделывания кофе» квантификатор «только» выполняет именно эту роль – выделителя из множества стран тех, которые относятся к тропическим. Утверждение, приведенное нами, порождает два других утверждения: «Существуют тропические страны, в которых возделывается кофе» и «Для всех стран, которые не являются тропическими, неверно утверждение, что в них можно возделывать кофе». Но в естественном языке «только» может использоваться и для указания на другие способы вычленения событий. Вот несколько примеров: «Я купил только чашки» (т.е. я купил чашки, а не что-либо иное), «На лекцию пришло только пять студентов» (т.е. именно пять, а не другое число), «Он приедет только завтра» (а не сегодня? не послезавтра?). Число подобных примеров можно неограниченно продолжать. «Только» – не единственный экзотический квантификатор. Чего стоит, например, квантификатор «Даже»! Сравним два утверждения: «Даже Джек смог догнать эту лисицу» и «Даже Джек не смог догнать эту лисицу». Внешне оба утверждения весьма похожи. Но квантификатор «даже» выполняет в них различную роль. В первом утверждении Джек стоит на нижнем конце шкалы, по которой упорядочены все собаки, пригодные для охоты на лис, а во втором утверждении квантификатор «даже» ставит Джека на первое место в этой шкале. До настоящего времени не создана теория рассуждений с подобными квантификаторами. Поэтому в данном разделе рассмотрим лишь вполне определенную группу квантификаторов, которую будем называть нечеткими квантификаторами. Обозначим их, как это традиционно принято для кванторов в логике, перевернутыми буквами. Прежде всего определим, какие же квантификаторы будем считать нечеткими. Их название указывает на тесную связь с новым разделом математики – нечеткой математикой. Слово «нечеткая» да еще в применении к математике вызывает законное недоумение. Но такова калька английского слова fuzzy, которое можно переводить еще как «размытая» или «расплывчатая». Именно это слово использовал Л. Заде – основатель нечеткой математики. В отличие от обычного понятия множества, известного каждому, кто сталкивался с математикой, Заде ввел понятие нечеткого множества. Оно отличается от обычного множества тем, что относительно любых его элементов в теории Заде можно сделать три утверждения, из которых только первые два рассматриваются в обычной (четкой) математике: «Элемент принадлежит данному множеству», «Элемент не принадлежит данному множеству» и «Элемент принадлежит данному множеству со степенью уверенности ?». При этом 0<?<1. Первые два утверждения соответствуют ?=1 и ?=0. На рис. 28, а показана ситуация, связанная с формированием множества с именем «высокие люди». По-видимому, никто не усомнится, что персонаж А к этому множеству принадлежит. Для него ?=1. Столь же очевидно, что персонаж В должен остаться вне формируемого множества. Для него ?=0. Относительно же персонажа С мнения могут разделиться. Одни будут склонны считать, что рост 170 см уже достаточен для отнесения С к высоким людям. Другие же будут придерживаться противоположного мнения. Мнения относительно принадлежности отдельных элементов нечеткому множеству никогда не становятся однозначными. Это произошло бы в единственном случае, когда понятие «высокий рост» было бы регламентировано ГОСТом, обязательным для всех людей, участвующих в нашем мысленном эксперименте. А пока этого нет, каждый волен иметь по этому поводу свое мнение. 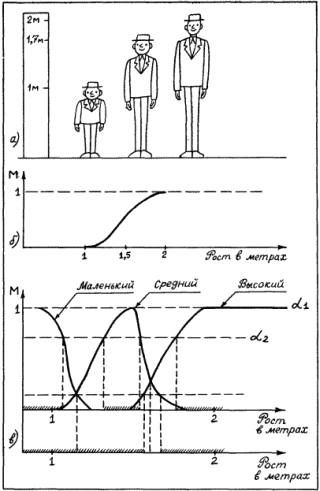 Рис. 28. Если опросить достаточное количество людей, то можно получить усредненные характеристики того, что люди считают высоким ростом. На рис. 28, б показана некоторая функция, называемая функцией принадлежности нечеткого множества. Ее ординаты показывают степень принадлежности людей с тем или иным значением роста, отложенным по горизонтальной оси, к множеству «высокие люди». Конкретные значения ординат этой функции могут меняться при смене тех, кого мы опрашиваем (например, в Юго-Восточной Азии произойдет явное смещение границы высоких людей влево), но качественный вид функции принадлежности будет неизменным. Сначала будет идти нулевая зона, потом начнется рост значений функции, а завершением ее будет опять горизонтальный участок со значением ?=1. «Высокий» – это представитель множества нечетких квантификаторов. Теперь можно сказать, что некоторый квантификатор является нечетким, если для него оказывается возможным построить функцию принадлежности к соответствующему нечеткому множеству. Таких квантификаторов в человеческих рассуждениях немало. Вот несколько примеров из стихотворений Б.Л. Пастернака: «Мне далекое время мерещится, дом на стороне Петербургской», «Огни заката догорали. Распутицей в бору глухом в далекий хутор на Урале тащился человек верхом», «На протяженьи многих зим я помню дни солнцеворота, и каждый был неповторим и повторялся вновь без счета». В них использованы нечеткие квантификаторы, формирующие нечеткие множества с именами «далекое время», «далекое место», «многие зимы». Для них можно построить соответствующие функции принадлежности, использовав, в частности, дополнительную информацию из текста стихотворения или из нормативных знаний о длительности человеческой жизни или об оценках расстояний, преодолеваемых верхом. Введем важное понятие лингвистической шкалы. Лингвистическая шкала – это последовательность нечетких квантификаторов, относящихся к оценке элементов по одному и тому же основанию (расстоянию, длительности, частоте, размерам и т.п.). Примерами лингвистических шкал могут служить шкала расстояний: вплотную, очень близко, близко, ни далеко ни близко, далеко, очень далеко, в бесконечности; или шкала размеров: крошечный, очень маленький, маленький, средний, большой, очень большой, огромный. Особенностью лингвистических шкал является то, что их элементы могут быть отражены в некоторых интервалах значений определенного параметра, измеряемого в натуральных единицах (метрах, часах, квадратных километрах и т.п.). При хорошо устроенной шкале эти интервалы должны покрывать ее плотно без наложений друг на друга. Добиться этого можно путем введения отсечек на графиках функций принадлежности, фиксирующих некоторое их пороговое значение. На рис. 28, в показаны два уровня отсечки ?: ?1 и ?2. Как видно из проекций отсекающих линий на ось абсцисс, ?1 таково, что плотного покрытия интервалами значений параметра «рост» не происходит. Между отрезками, соответствующими нечетким квантификаторам роста «маленький», «средний» и «высокий», образуются пустые отрезки (на рис. 28, в они не помечены косыми линиями). При значении ?2 заполнение почти плотное. Если оставшийся пустым отрезок разделить пополам между двумя соседними, то образуется лингвистическая шкала роста, содержащая три нечетких квантификатора. Величина ? может быть определена как степень уверенности, с которой квантификатор относит значения роста к соответствующим нечетким множествам (в нашем примере это множества «маленькие (в смысле роста) люди», «люди среднего роста» и «высокие люди»). Перейдем теперь к нечетким рассуждениям. Напомним сначала, что один шаг достоверного вывода можно описать в виде схемы следующего вида. 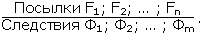 Здесь над чертой стоят те утверждения, истинность которых уже доказана, а ниже черты – утверждения, истинность которых логически следует из верхних утверждений и тех правил вывода, которые используются в данной логической системе. Для большей наглядности рассмотрим один частный, но весьма распространенный случай вывода, с которым мы уже сталкивались, – по правилу модус поненс. Напомним его схему: 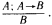 Рассмотрим теперь схему вида 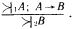 Здесь 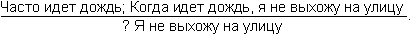 Знак вопроса стоит тут на том месте, где должен находиться некоторый нечеткий квантификатор. Интуиция подсказывает нам, что им должен быть квантификатор «часто». Вывод «часто я не выхожу на улицу» выглядит вполне в духе человеческих умозаключений. Рассмотрим еще одну схему: 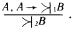 Здесь квантификатор 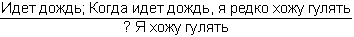 Какой квантификатор надо здесь подставить вместо знака вопроса? Однозначный ответ на этот вопрос вряд ли возможен. В схеме нет информации о частоте события А. А без этой информации трудно сделать сколь-нибудь содержательное заключение. Можно лишь отметить, что если речь идет о сиюминутном решении о прогулке, то положительное решение о ней имеет не слишком большую вероятность. Рассмотрим, наконец, схему 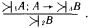 Конкретный случай ее реализации: 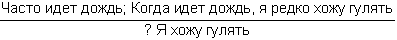 Здесь определение При создании логик, моделирующих нечеткие рассуждения, делалось немало попыток поиска формальных процедур, позволяющих «вычислять» вид В высказываниях «В Ленинграде часто идет дождь» или «Мой ребенок часто болеет» использован один и тот же нечеткий квантификатор «часто». Но каждому ясно, что за ним скрывается неодинаковая фактическая частота. Дожди в Ленинграде, наверное, идут куда чаще, чем болеет ребенок. Один и тот же квантификатор соотносится в этих высказываниях с различными нормами. Норма частоты дождя в Ленинграде иная, чем норма частоты заболевания детей. Если житель Москвы говорит, что он живет недалеко от работы, а житель Ялты говорит то же самое, то за квантификатором «недалеко» у москвича скрывается куда большее расстояние, чем у ялтинца. Таким образом, сами по себе квантификаторы ничего не определяют, кроме положения на лингвистической шкале. В конкретных ситуациях они приобретают некоторый физический смысл, зависящий от этих ситуаций. Поэтому особое значение приобретают исследования, в которых предлагается аппарат, позволяющий делать нечеткие выводы единообразным способом для всего класса однотипных или похожих ситуаций. Известен, например, Принцип ситуативной инвариантности, позволяющий, проведя рассуждение для одной ситуации, преобразовывать его формальным образом для ситуаций, сходных с первоначальной. Этот принцип срабатывает, если имеется лингвистическая шкала. Тогда переход от ситуации к ситуации связан с монотонным смещением всех отрезков, соответствующих квантификаторам шкалы, на определенное число позиций влево или вправо по множеству значений признака, учитываемого данной лингвистической шкалой. Такое смещение позволяет использовать в нечетких рассуждениях элементы, характерные для рассуждений по аналогии. Только вместо диаграммы, отражающей пропорцию Лейбница, в нечетких рассуждениях появляется нечеткая диаграмма моделирования (НДМ), которая имеет вид 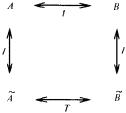 В этой диаграмме А обозначает описание некоторой ситуации, а ? – отображение этой ситуации с помощью перехода от качественных параметров, присутствующих в описании А, к их представлению через утверждения с нечеткими квантификаторами. Таким образом, ? есть нечеткая модель ситуации А. Если ситуация А является основанием для перехода с помощью некоторого рассуждения Т к ситуации B, то нам бы хотелось, чтобы существовало нечеткое рассуждение Такая близость рассуждений по аналогии и нечетких рассуждений не случайна. Ибо в основе этих рассуждений лежит идея сходства, похожести. Нечеткая силлогистика Силлогистика Аристотеля совсем недавно вновь стала объектом пристального внимания исследователей. Идеи нечетких рассуждений оказались перенесенными на модусы и фигуры, казавшиеся венцом достоверных рассуждений. Прежде чем изложить эти идеи, опишем одну историю, которую можно было бы назвать «Силлогизм бабушки».
Постараемся разобраться в силлогизме бабушки. Введем ряд обозначений: а – количество людей, которые ходят в цилиндре; b – количество людей, которые ходят с тросточкой; с – количество людей, которые пьют только абсент; Р(b/а) – доля тех, кто ходит с тросточкой среди тех, кто носит цилиндр; Р(c/b) – доля тех, кто пьет только абсент, среди тех, кто ходит с тросточкой; Р(c/a) – доля тех, кто пьет только абсент, среди тех, кто ходит в цилиндре; Р(а) – доля тех жителей города, которые ходят в цилиндре, от всех жителей города; Р(b) – доля тех, кто ходит с тросточкой, от всех жителей города; Р(c) – доля тех, кто пьет только абсент, от всех жителей города. Получение всей этой информации требует некоторого статистического обследования жителей города и их привычек. Результаты такого обследования могут быть сведены в таблицу сопряженности (табл. 5). Таблица 5 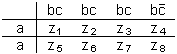 В этой таблице z3, например, доля жителей торода, которые ходят в цилиндре и с тросточкой, но не пьют абсента. Аналогичным образом интерпретируются и остальные ее элементы. Значения z1, удовлетворяют ряду соотношений. 1. z1+z2+z3+z4+z5+z6+z7+z8=1. Это соотношение вытекает из нормировки, так как zi – доли. 2. Восемь ограничений вида zi?0, вытекающие из смысла zi, i=1,2,…,8. 3. Предположим, что в городе множества жителей, которые носят цилиндр, ходят с тросточкой и пьют только абсент, не являются пустыми. Это означает, что должны выполняться следующие неравенства: 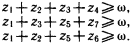 Значение ? выбрано так, чтобы все эти три неравенства были справедливы. 4. Еще два неравенства связаны с тем, что величины Р(b/а) и Р(c/b), входящие в посылку силлогизма бабушки, должны удовлетворять ограничениям P(b/a)?? и P(c/b)??, где ? подобрано таким образом, чтобы оба неравенства выполнялись. Если условные частоты выразить через элементы таблицы сопряженности, то можно получить еще два неравенства: 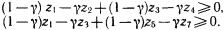 В этих ограничениях два параметра: ? и ?. Варьируя их, можно вводить различные нечеткие квантификаторы в силлогизм типа силлогизма бабушки или силлогизма Сумбурука. Дадим некоторые необходимые пояснения к приведенной системе. Посылки силлогизма бабушки, как его сформулировал бармен, звучат так: «Из тех, кто носит цилиндр, почти все ходят с тросточкой» И «Из тех, кто ходит с тросточкой, почти все пьют только абсент». Заглавная буква И отделяет один член посылки от другого. Первый член посылки говорит о том, что P(b/a) есть нечеткий квантификатор «почти все», а второй член посылки содержит аналогичное утверждение относительно P(c/b). Если считать, что нечеткому квантификатору «почти все» на лингвистической шкале соответствует некоторый отрезок, то он имеет вид [?,1], где ?>0. Именно в этом смысл двух последних неравенств. В силлогизме бабушки дается оценка нечеткого квантификатора, соответствующего Р(с/а). Бабушка считает, что Р(с/а) соответствует квантификатор «многие». Сумбурук же считает, что Р(с/а) соответствует квантификатор «почти все». Значит, бабушка предполагает, что Р(с/а) на лингвистической шкале соответствует полуинтервал [?,?] и ?>0, а Сумбурук уверен, что это отрезок [?,1]. В этом и состоит их несогласие. Их спор происходит в условиях некоторого «контекста». Этот контекст определяется величинами Р(а), Р(b) и Р(с), характерными для данного городка. В наших ограничениях контекст определяется параметром ?. Силлогизмы бабушки и Сумбурука – это формальный вывод вида А Как разрешить спор? Выход один. Надо задать значения ?, ? и ? и свести проблему к решению типовой задачи линейного целочисленного программирования, которая формулируется следующим образом. Найти целочисленные значения zi?0 (i=1,2,…,8), такие, что удовлетворяются шесть вышеприведенных неравенств, и такие, что минимум функции 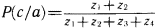 достигает своего максимума. Если задача решена и минимум Р(с/а) есть ? и этот минимум удовлетворяет неравенству ???, то верен силлогизм бабушки. А если ???<?, то верен силлогизм Сумбурука. Если же ?<?, то и бабушка, и Сумбурук ошиблись. Их силлогизмы будут ложными. Значит, все зависит от того, как определены ?, ? и ?. Пусть для определения этих значений мы опросили четырех людей Ч1, Ч2, Ч3 и Ч4. Их ответы сведены в табл. 6. Таблица 6  Интерпретация чисел в таблице следующая. Опрашиваемый считает, что можно говорить «почти все», когда явление это встречается не реже, чем в 95 случаях из 100. Аналогично интерпретируются и остальные элементы таблицы. В первом столбце стоят значения ?, во втором ?, а в третьем ?. Каждая строка может быть использована для решения задачи линейного программирования, которую мы сформулировали. Если решить возникающие четыре задачи, то выяснится, что силлогизм бабушки оказывается истинным во всех случаях, кроме третьего. В третьем случае прав Сумбурук, а бабушка ошибается. Из сказанного ясно, что при исследовании нечетких силлогизмов (или D-cиллогизмов, как их принято называть) необходимо анализировать области в пространстве параметров ?, ?, ?, в которых будут истинны или ложны те или иные силлогизмы. В частности, для силлогизма бабушки доказывается следующее утверждение, которое естественно было бы назвать Теоремой бармена: «Силлогизм бабушки истинен только в тех точках параметрического пространства, в которых выполняется соотношение ??max[0,2?1/?, 1?(1??)(?+1/?)]». Но, наверное, ни бармен, ни Сумбурук не смогли бы так четко сформулировать нужный для разрешения их спора результат. Рассуждая о споре в баре, мы незаметно сформулировали метод формального поиска оценок нечетких квантификаторов в схемах рассуждений. Ведь если вернуться к схемам предшествующего раздела, то становится ясным, что метод решения силлогизма бабушки вполне пригоден для поиска Коллекция схем Среди схем правдоподобных рассуждений встречаются не только те, которые мы расссмотрели и которые основаны на индуктивном выводе, аналогиях или нечетких квантификаторах. Многими исследователями предлагались и иные схемы. Их количество достаточно велико и продолжает расти. В этом разделе мы приведем (практически без комментариев) примеры схем, в основе которых лежат соображения, связанные с теорией вероятностей и аналогией, а также несколько схем, типичных для теории возможностей, активно развивающейся в последние годы ветви теории рассуждений. Рассмотрим прежде всего схемы рассуждений, опирающиеся на свойства вероятностей, т.е. вероятностные схемы рассуждений.  Рассуждением, основанным, например, на схеме 2, может служить следующее: «С вероятностью, большей 0,7, при переохлаждении двигателя он не заводится с помощью стартера. Вероятность того, что он не заводится, меньше 0,5. Следовательно, вероятность того, что двигатель переохлажден, меньше min(1,1–0,7+0,5), т.е. меньше 0,8». Так же нетрудно придумать примеры и для других схем вероятностных рассуждений. Рассмотрим две схемы рассуждения с учетом необходимых условий.  Значения q и r необходимости в этих схемах могут оцениваться в каких-то специальных единицах. Можно считать, например, что имеется лингвистическая шкала нечетких квантификаторов необходимости. Тогда q и r будут соответствовать некоторые интервалы или усредненные характеристики этих интервалов. В качестве примера рассуждения с учетом необходимых условий в соответствии со схемой 5 приведем следующее рассуждение: «Если у меня будет дача, то необходимо будет купить велосипед. Дача мне крайне необходима. Тогда покупка велосипеда для меня необходима». Рассмотрим еще две схемы, в которых наряду с необходимостью учитывается возможность некоторых фактов, явлений или действий. Подобные схемы (как и две предшествующие) характерны для упоминавшейся теории возможностей.  Пример рассуждения, основанного на схеме 7: «Когда поднимается температура в реакторе, чрезвычайно необходимо понизить в нем давление. Возможность повышения температуры в реакторе высока. Следовательно, возможность того, что надо будет снижать давление в реакторе, либо больше нуля, либо больше той возможности, которая приписана событию повышения температуры». Альтернативный характер этого рассуждения обусловлен тем, что q и r при проведении его не были оценены количественно. Это не позволяет сделать окончательный альтернативный вывод в следствии. Завершим раздел еще тремя схемами рассуждений, в которых учитывается возможная взаимосвязь А и В, а также некоторые соображения из рассуждений по аналогии.  Каждый, кого интересуют схемы правдоподобных рассуждений, может без труда увеличить нашу коллекцию, например, заимствовав их из книги Д. Пойи, приведенной в списке литературы. Нам же необходимо двигаться дальше к тем человеческим схемам рассуждений, в которых активно используются знания, хранящиеся в его памяти, т.е. к рассуждениям, на которые опирается интеллектуальная деятельность человека и ее моделирование в современных интеллектуальных системах. |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||
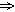 трактуется лишь как появление d при наличии а, b и c, а
трактуется лишь как появление d при наличии а, b и c, а 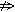 означает, что d не появляется. Повторение ситуаций n раз необходимо для того, чтобы убедиться в устойчивости всей ситуации в целом, для исключения случая, когда d появляется случайным образом, не будучи никак связанным с а. Если n, с точки зрения экспериментатора, достаточно для уверенного вывода, то, используя Принцип единственного различия, можно утверждать, что а является причиной, a d следствием, т.е. что между a и d имеет место причинно-следственное отношение. В дальнейшем будем называть реализации a,b,c
означает, что d не появляется. Повторение ситуаций n раз необходимо для того, чтобы убедиться в устойчивости всей ситуации в целом, для исключения случая, когда d появляется случайным образом, не будучи никак связанным с а. Если n, с точки зрения экспериментатора, достаточно для уверенного вывода, то, используя Принцип единственного различия, можно утверждать, что а является причиной, a d следствием, т.е. что между a и d имеет место причинно-следственное отношение. В дальнейшем будем называть реализации a,b,c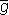 . Проверяем, какое из полученных выражений является ложным на всех контрпримерах. Таковым оказывается лишь е. Значит, е должно войти в выражение для причины хорошего настроения зверюшки. Но только два первых положительных примера характеризуются истинным е. Третий положительный пример портит все дело.
. Проверяем, какое из полученных выражений является ложным на всех контрпримерах. Таковым оказывается лишь е. Значит, е должно войти в выражение для причины хорошего настроения зверюшки. Но только два первых положительных примера характеризуются истинным е. Третий положительный пример портит все дело. g), нигде не встречается в отрицательных примерах. Это позволяет, наконец, написать выражение для причины h в следующей форме: h=(e
g), нигде не встречается в отрицательных примерах. Это позволяет, наконец, написать выражение для причины h в следующей форме: h=(e (?&
(?& можно назвать обобщением. При переходе от треугольника к многоугольнику наследуются только те геометрические свойства, которые верны для любых многоугольников. Сам треугольник по отношению к множеству многоугольников представляет некоторую конкретизацию. На рис. 24 преобразованием конкретизации служит
можно назвать обобщением. При переходе от треугольника к многоугольнику наследуются только те геометрические свойства, которые верны для любых многоугольников. Сам треугольник по отношению к множеству многоугольников представляет некоторую конкретизацию. На рис. 24 преобразованием конкретизации служит  , переводящее произвольный треугольник в его частный вид – прямоугольный треугольник. А вот преобразование
, переводящее произвольный треугольник в его частный вид – прямоугольный треугольник. А вот преобразование 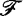 можно назвать преобразованием по аналогии. Треугольная пирамида сохраняет многие свойства треугольника, но является не плоской, а объемной фигурой.
можно назвать преобразованием по аналогии. Треугольная пирамида сохраняет многие свойства треугольника, но является не плоской, а объемной фигурой. 1 и некоторый (вообще говоря, другой) алгебраический язык для описания А’ и В’, который обозначим
1 и некоторый (вообще говоря, другой) алгебраический язык для описания А’ и В’, который обозначим  l и m
l и m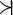 1 – нечеткий квантификатор, показывающий, что истинность А не является абсолютной. Конечно, вывод, который следует из подобной посылки, также не может быть достоверным. Степень его правдоподобности оценивается нечетким квантификатором
1 – нечеткий квантификатор, показывающий, что истинность А не является абсолютной. Конечно, вывод, который следует из подобной посылки, также не может быть достоверным. Степень его правдоподобности оценивается нечетким квантификатором 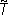 , с помощью которого из ? получалось бы описание
, с помощью которого из ? получалось бы описание 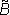 , и между А и ?, а также между В и
, и между А и ?, а также между В и